VistaFormer: Scalable Vision Transformers for Satellite Image Time Series Segmentation

0

Sign in to get full access
Overview
- The paper proposes VistaFormer, a scalable vision transformer model for satellite image time series segmentation.
- VistaFormer leverages a novel time-conditioned squeezed attention mechanism to efficiently process temporal data.
- The model achieves state-of-the-art performance on multiple satellite image time series segmentation benchmarks.
Plain English Explanation
VistaFormer is a new artificial intelligence (AI) model designed to analyze satellite images over time. Satellite images are often captured in a sequence, creating a "time series" of data. VistaFormer uses a special attention mechanism to efficiently process this temporal information and segment the satellite images into meaningful regions, such as identifying different land cover types.
The key innovation in VistaFormer is the time-conditioned squeezed attention mechanism, which allows the model to focus on the most relevant temporal information when making predictions. This helps VistaFormer scale to large satellite image time series without sacrificing performance.
VistaFormer has been shown to outperform other state-of-the-art models on several benchmark datasets for satellite image time series segmentation. This suggests VistaFormer could be a powerful tool for applications like land use monitoring, urban planning, and disaster response.
Technical Explanation
VistaFormer is a vision transformer model designed for satellite image time series segmentation. The model uses a transformer architecture to process the spatial information in the satellite images, and a novel time-conditioned squeezed attention mechanism to efficiently incorporate the temporal dimension.
The time-conditioned squeezed attention mechanism works by first compressing the temporal information into a lower-dimensional representation, and then using that compressed representation to modulate the attention weights in the transformer. This allows VistaFormer to focus on the most relevant temporal features when making segmentation predictions, improving both performance and efficiency.
VistaFormer is evaluated on several satellite image time series segmentation benchmarks, including the SURFRACE and SMART datasets. The results show that VistaFormer outperforms other state-of-the-art models, demonstrating the effectiveness of the time-conditioned squeezed attention mechanism and the scalability of the overall transformer-based architecture.
Critical Analysis
The paper provides a thorough evaluation of VistaFormer's performance on multiple satellite image time series segmentation benchmarks, which lends confidence to the claims of its effectiveness. However, the authors do not discuss any potential limitations or caveats of the approach.
One area that could be explored further is the interpretability of VistaFormer's predictions. As a transformer-based model, it may be challenging to understand the specific temporal features the model is focusing on when making segmentation decisions. Providing more insight into the model's internal workings could help users trust and better utilize the system.
Additionally, the paper does not compare VistaFormer to other types of time series analysis models, such as recurrent neural networks or 3D convolutional networks. Exploring the trade-offs between these different approaches could provide a more comprehensive understanding of the strengths and weaknesses of the VistaFormer architecture.
Conclusion
The VistaFormer paper presents a novel vision transformer model that achieves state-of-the-art performance on satellite image time series segmentation tasks. The key innovation is the time-conditioned squeezed attention mechanism, which allows the model to efficiently process temporal information and scale to large datasets.
The results suggest VistaFormer could be a valuable tool for a range of applications that rely on analyzing satellite imagery over time, such as land use monitoring, urban planning, and disaster response. Further research into the interpretability and broader comparisons of the VistaFormer approach could provide additional insights and help drive the development of even more robust and capable models for working with satellite image time series.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!VistaFormer: Scalable Vision Transformers for Satellite Image Time Series Segmentation
Ezra MacDonald, Derek Jacoby, Yvonne Coady
We introduce VistaFormer, a lightweight Transformer-based model architecture for the semantic segmentation of remote-sensing images. This model uses a multi-scale Transformer-based encoder with a lightweight decoder that aggregates global and local attention captured in the encoder blocks. VistaFormer uses position-free self-attention layers which simplifies the model architecture and removes the need to interpolate temporal and spatial codes, which can reduce model performance when training and testing image resolutions differ. We investigate simple techniques for filtering noisy input signals like clouds and demonstrate that improved model scalability can be achieved by substituting Multi-Head Self-Attention (MHSA) with Neighbourhood Attention (NA). Experiments on the PASTIS and MTLCC crop-type segmentation benchmarks show that VistaFormer achieves better performance than comparable models and requires only 8% of the floating point operations using MHSA and 11% using NA while also using fewer trainable parameters. VistaFormer with MHSA improves on state-of-the-art mIoU scores by 0.1% on the PASTIS benchmark and 3% on the MTLCC benchmark while VistaFormer with NA improves on the MTLCC benchmark by 3.7%.
Read more9/16/2024
0
SegFormer3D: an Efficient Transformer for 3D Medical Image Segmentation
Shehan Perera, Pouyan Navard, Alper Yilmaz
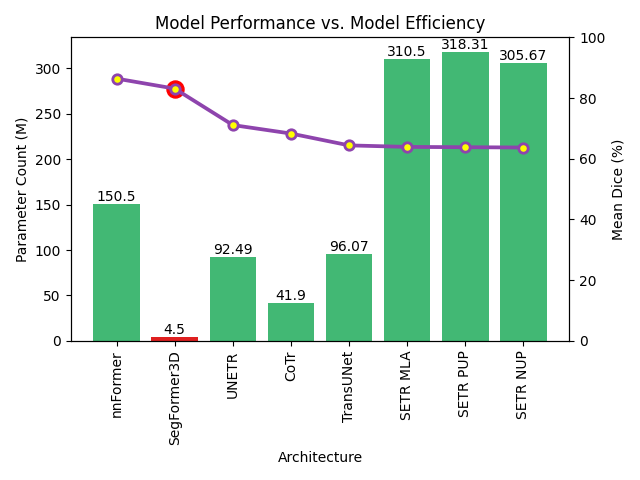
The adoption of Vision Transformers (ViTs) based architectures represents a significant advancement in 3D Medical Image (MI) segmentation, surpassing traditional Convolutional Neural Network (CNN) models by enhancing global contextual understanding. While this paradigm shift has significantly enhanced 3D segmentation performance, state-of-the-art architectures require extremely large and complex architectures with large scale computing resources for training and deployment. Furthermore, in the context of limited datasets, often encountered in medical imaging, larger models can present hurdles in both model generalization and convergence. In response to these challenges and to demonstrate that lightweight models are a valuable area of research in 3D medical imaging, we present SegFormer3D, a hierarchical Transformer that calculates attention across multiscale volumetric features. Additionally, SegFormer3D avoids complex decoders and uses an all-MLP decoder to aggregate local and global attention features to produce highly accurate segmentation masks. The proposed memory efficient Transformer preserves the performance characteristics of a significantly larger model in a compact design. SegFormer3D democratizes deep learning for 3D medical image segmentation by offering a model with 33x less parameters and a 13x reduction in GFLOPS compared to the current state-of-the-art (SOTA). We benchmark SegFormer3D against the current SOTA models on three widely used datasets Synapse, BRaTs, and ACDC, achieving competitive results. Code: https://github.com/OSUPCVLab/SegFormer3D.git
Read more4/17/2024
🤿
0
Mask4Former: Mask Transformer for 4D Panoptic Segmentation
Kadir Yilmaz, Jonas Schult, Alexey Nekrasov, Bastian Leibe
Accurately perceiving and tracking instances over time is essential for the decision-making processes of autonomous agents interacting safely in dynamic environments. With this intention, we propose Mask4Former for the challenging task of 4D panoptic segmentation of LiDAR point clouds. Mask4Former is the first transformer-based approach unifying semantic instance segmentation and tracking of sparse and irregular sequences of 3D point clouds into a single joint model. Our model directly predicts semantic instances and their temporal associations without relying on hand-crafted non-learned association strategies such as probabilistic clustering or voting-based center prediction. Instead, Mask4Former introduces spatio-temporal instance queries that encode the semantic and geometric properties of each semantic tracklet in the sequence. In an in-depth study, we find that promoting spatially compact instance predictions is critical as spatio-temporal instance queries tend to merge multiple semantically similar instances, even if they are spatially distant. To this end, we regress 6-DOF bounding box parameters from spatio-temporal instance queries, which are used as an auxiliary task to foster spatially compact predictions. Mask4Former achieves a new state-of-the-art on the SemanticKITTI test set with a score of 68.4 LSTQ.
Read more4/12/2024
0
New!AgileFormer: Spatially Agile Transformer UNet for Medical Image Segmentation
Peijie Qiu, Jin Yang, Sayantan Kumar, Soumyendu Sekhar Ghosh, Aristeidis Sotiras
In the past decades, deep neural networks, particularly convolutional neural networks, have achieved state-of-the-art performance in a variety of medical image segmentation tasks. Recently, the introduction of the vision transformer (ViT) has significantly altered the landscape of deep segmentation models. There has been a growing focus on ViTs, driven by their excellent performance and scalability. However, we argue that the current design of the vision transformer-based UNet (ViT-UNet) segmentation models may not effectively handle the heterogeneous appearance (e.g., varying shapes and sizes) of objects of interest in medical image segmentation tasks. To tackle this challenge, we present a structured approach to introduce spatially dynamic components to the ViT-UNet. This adaptation enables the model to effectively capture features of target objects with diverse appearances. This is achieved by three main components: textbf{(i)} deformable patch embedding; textbf{(ii)} spatially dynamic multi-head attention; textbf{(iii)} deformable positional encoding. These components were integrated into a novel architecture, termed AgileFormer. AgileFormer is a spatially agile ViT-UNet designed for medical image segmentation. Experiments in three segmentation tasks using publicly available datasets demonstrated the effectiveness of the proposed method. The code is available at href{https://github.com/sotiraslab/AgileFormer}{https://github.com/sotiraslab/AgileFormer}.
Read more9/18/2024