Navigating the Landscape of Large Language Models: A Comprehensive Review and Analysis of Paradigms and Fine-Tuning Strategies
2404.09022
0
0

Abstract
With the surge of ChatGPT,the use of large models has significantly increased,rapidly rising to prominence across the industry and sweeping across the internet. This article is a comprehensive review of fine-tuning methods for large models. This paper investigates the latest technological advancements and the application of advanced methods in aspects such as task-adaptive fine-tuning,domain-adaptive fine-tuning,few-shot learning,knowledge distillation,multi-task learning,parameter-efficient fine-tuning,and dynamic fine-tuning.
Create account to get full access
Related Work
Overview
- This paper provides a comprehensive review and analysis of the current landscape of large language models (LLMs) and the various fine-tuning strategies employed to enhance their performance.
- It explores different paradigms, such as task-adaptive fine-tuning, domain-adaptive fine-tuning, few-shot learning, knowledge distillation, multi-task learning, and [parameter-efficient fine-tuning], among others.
Plain English Explanation
The paper examines the different ways researchers are working to improve the capabilities of large language models (LLMs) - powerful AI systems that can understand and generate human-like text. It looks at various "fine-tuning" strategies, which involve using smaller datasets to adapt the LLMs to specific tasks or domains.
Some of the key fine-tuning approaches discussed include:
- Task-adaptive fine-tuning: Adapting the LLM to perform better on a specific task, like translation or text generation.
- Domain-adaptive fine-tuning: Adapting the LLM to a particular subject area or "domain," like legal documents or medical literature.
- Few-shot learning: Training the LLM to learn new tasks or skills using only a small amount of example data.
- Knowledge distillation: Transferring knowledge from a larger, more powerful LLM to a smaller, more efficient one.
- Multi-task learning: Training the LLM to perform multiple tasks simultaneously, which can improve its overall capabilities.
- Parameter-efficient fine-tuning: Updating only a small portion of the LLM's parameters during the fine-tuning process, which can be more computationally efficient.
The paper provides a comprehensive overview of these different fine-tuning strategies and discusses their potential benefits and limitations.
Technical Explanation
The paper presents a thorough review of the current research on large language models (LLMs) and the various fine-tuning techniques used to adapt them to specific tasks and domains. It covers a range of paradigms, including:
-
Task-Adaptive Fine-Tuning: This approach involves fine-tuning the LLM on a dataset related to a specific task, such as translation or text generation, to improve its performance on that task. The paper on boosting translation capabilities of LLMs provides an example of this strategy.
-
Domain-Adaptive Fine-Tuning: Here, the LLM is fine-tuned on data from a particular domain, like legal or medical literature, to better understand and generate text within that domain. The paper on automating research synthesis using domain-specific LLMs demonstrates this approach.
-
Few-Shot Learning: This paradigm focuses on training the LLM to learn new tasks or skills using only a small amount of example data, as shown in the paper on the future of machine translation.
-
Knowledge Distillation: This technique involves transferring knowledge from a larger, more powerful LLM to a smaller, more efficient one, as discussed in the paper on adaptations for recommender systems.
-
Multi-Task Learning: In this approach, the LLM is trained to perform multiple tasks simultaneously, which can enhance its overall capabilities, as described in the paper on enhancing general agent capabilities.
-
Parameter-Efficient Fine-Tuning: This strategy focuses on updating only a small portion of the LLM's parameters during the fine-tuning process, which can be more computationally efficient.
The paper provides a comprehensive analysis of these different fine-tuning paradigms, discussing their potential benefits, limitations, and areas for further research.
Critical Analysis
The paper presents a thorough and well-researched overview of the current state of large language models and the various fine-tuning strategies employed to enhance their performance. The authors have done an extensive literature review and provided detailed explanations of the different paradigms, making the content accessible to a wide audience.
One potential limitation of the paper is that it does not delve deeply into the specific technical details of each fine-tuning approach. While the high-level explanations are helpful, readers who are more technically inclined may want more in-depth information on the architectural changes, training procedures, and experimental results for each paradigm.
Additionally, the paper could have addressed some of the potential ethical concerns and societal implications associated with the increased use of large language models, such as the risk of bias, the spread of misinformation, and the impact on employment in certain industries. Incorporating a more critical examination of these issues would have strengthened the paper's overall analysis.
Despite these minor shortcomings, the paper remains a valuable resource for researchers, practitioners, and interested readers who want to gain a comprehensive understanding of the current landscape of large language models and the various strategies being employed to push the boundaries of their capabilities.
Conclusion
This paper provides a comprehensive review and analysis of the current landscape of large language models and the various fine-tuning strategies used to enhance their performance. It explores a range of paradigms, including task-adaptive fine-tuning, domain-adaptive fine-tuning, few-shot learning, knowledge distillation, multi-task learning, and parameter-efficient fine-tuning.
The paper offers a detailed and accessible explanation of these different approaches, highlighting their potential benefits, limitations, and areas for further research. While it could have delved deeper into the technical details and addressed some of the ethical implications more thoroughly, the paper remains a valuable resource for understanding the evolving field of large language models and the innovative ways researchers are working to push the boundaries of their capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
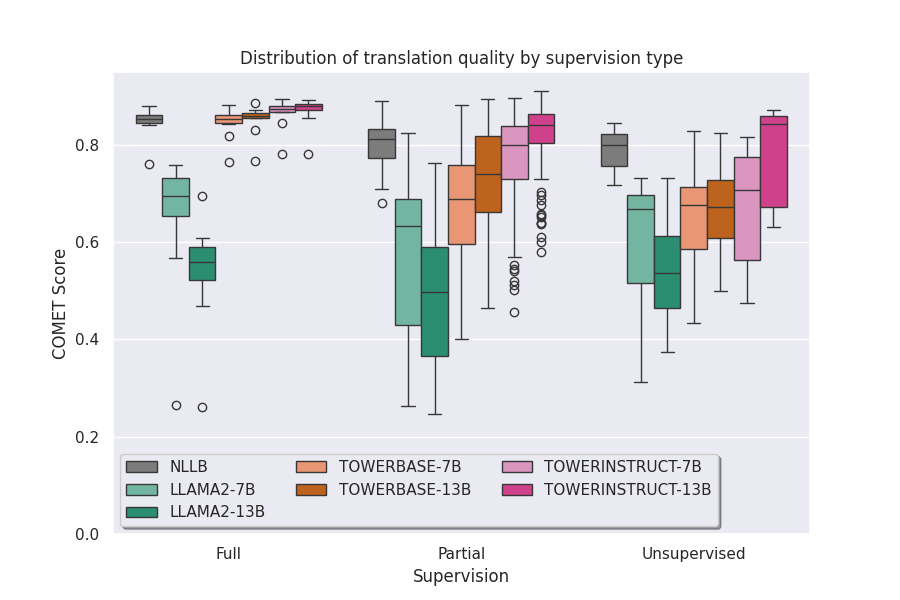
How Multilingual Are Large Language Models Fine-Tuned for Translation?
Aquia Richburg, Marine Carpuat
0
0
A new paradigm for machine translation has recently emerged: fine-tuning large language models (LLM) on parallel text has been shown to outperform dedicated translation systems trained in a supervised fashion on much larger amounts of parallel data (Xu et al., 2024a; Alves et al., 2024). However, it remains unclear whether this paradigm can enable massively multilingual machine translation or whether it requires fine-tuning dedicated models for a small number of language pairs. How does translation fine-tuning impact the MT capabilities of LLMs for zero-shot languages, zero-shot language pairs, and translation tasks that do not involve English? To address these questions, we conduct an extensive empirical evaluation of the translation quality of the TOWER family of language models (Alves et al., 2024) on 132 translation tasks from the multi-parallel FLORES-200 data. We find that translation fine-tuning improves translation quality even for zero-shot languages on average, but that the impact is uneven depending on the language pairs involved. These results call for further research to effectively enable massively multilingual translation with LLMs.
6/3/2024
💬
Exploring the landscape of large language models: Foundations, techniques, and challenges
Milad Moradi, Ke Yan, David Colwell, Matthias Samwald, Rhona Asgari
0
0
In this review paper, we delve into the realm of Large Language Models (LLMs), covering their foundational principles, diverse applications, and nuanced training processes. The article sheds light on the mechanics of in-context learning and a spectrum of fine-tuning approaches, with a special focus on methods that optimize efficiency in parameter usage. Additionally, it explores how LLMs can be more closely aligned with human preferences through innovative reinforcement learning frameworks and other novel methods that incorporate human feedback. The article also examines the emerging technique of retrieval augmented generation, integrating external knowledge into LLMs. The ethical dimensions of LLM deployment are discussed, underscoring the need for mindful and responsible application. Concluding with a perspective on future research trajectories, this review offers a succinct yet comprehensive overview of the current state and emerging trends in the evolving landscape of LLMs, serving as an insightful guide for both researchers and practitioners in artificial intelligence.
4/19/2024
💬
Domain-Specific Fine-Tuning of Large Language Models for Interactive Robot Programming
Benjamin Alt, Urs Ke{ss}ner, Aleksandar Taranovic, Darko Katic, Andreas Hermann, Rainer Jakel, Gerhard Neumann
0
0
Industrial robots are applied in a widening range of industries, but robot programming mostly remains a task limited to programming experts. We propose a natural language-based assistant for programming of advanced, industrial robotic applications and investigate strategies for domain-specific fine-tuning of foundation models with limited data and compute.
4/23/2024
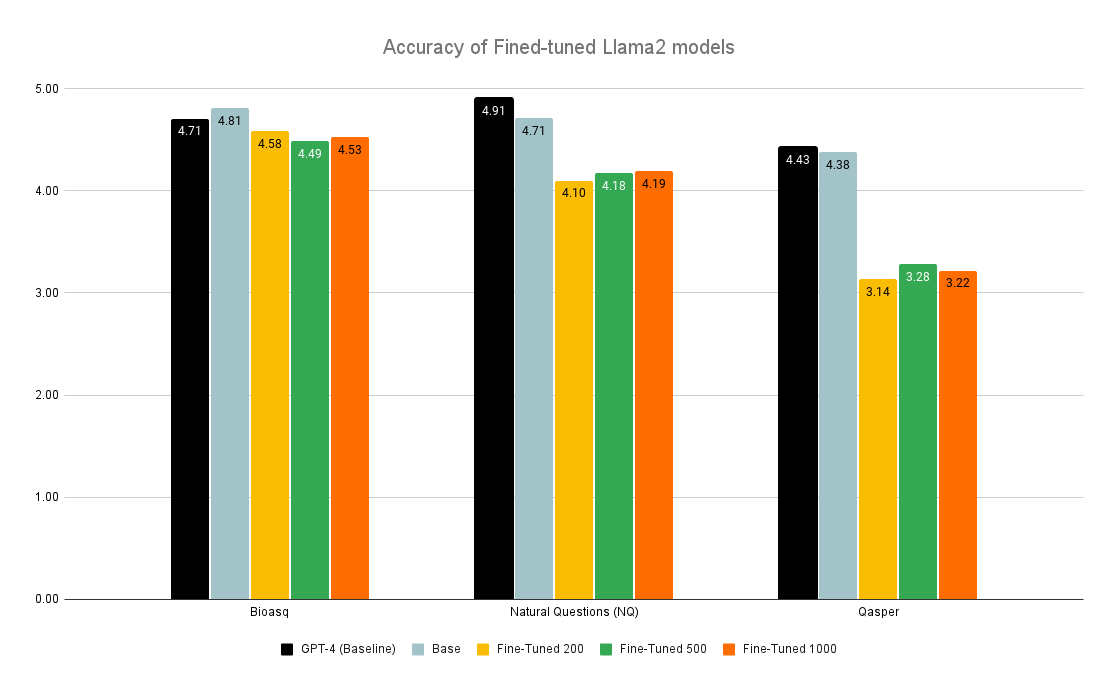
Fine-Tuning or Fine-Failing? Debunking Performance Myths in Large Language Models
Scott Barnett, Zac Brannelly, Stefanus Kurniawan, Sheng Wong
0
0
Large Language Models (LLMs) have the unique capability to understand and generate human-like text from input queries. When fine-tuned, these models show enhanced performance on domain-specific queries. OpenAI highlights the process of fine-tuning, stating: To fine-tune a model, you are required to provide at least 10 examples. We typically see clear improvements from fine-tuning on 50 to 100 training examples, but the right number varies greatly based on the exact use case. This study extends this concept to the integration of LLMs within Retrieval-Augmented Generation (RAG) pipelines, which aim to improve accuracy and relevance by leveraging external corpus data for information retrieval. However, RAG's promise of delivering optimal responses often falls short in complex query scenarios. This study aims to specifically examine the effects of fine-tuning LLMs on their ability to extract and integrate contextual data to enhance the performance of RAG systems across multiple domains. We evaluate the impact of fine-tuning on the LLMs' capacity for data extraction and contextual understanding by comparing the accuracy and completeness of fine-tuned models against baseline performances across datasets from multiple domains. Our findings indicate that fine-tuning resulted in a decline in performance compared to the baseline models, contrary to the improvements observed in standalone LLM applications as suggested by OpenAI. This study highlights the need for vigorous investigation and validation of fine-tuned models for domain-specific tasks.
6/18/2024