Warmth and competence in human-agent cooperation
2201.13448
0
0
📊
Abstract
Interaction and cooperation with humans are overarching aspirations of artificial intelligence (AI) research. Recent studies demonstrate that AI agents trained with deep reinforcement learning are capable of collaborating with humans. These studies primarily evaluate human compatibility through objective metrics such as task performance, obscuring potential variation in the levels of trust and subjective preference that different agents garner. To better understand the factors shaping subjective preferences in human-agent cooperation, we train deep reinforcement learning agents in Coins, a two-player social dilemma. We recruit $N = 501$ participants for a human-agent cooperation study and measure their impressions of the agents they encounter. Participants' perceptions of warmth and competence predict their stated preferences for different agents, above and beyond objective performance metrics. Drawing inspiration from social science and biology research, we subsequently implement a new ``partner choice'' framework to elicit revealed preferences: after playing an episode with an agent, participants are asked whether they would like to play the next episode with the same agent or to play alone. As with stated preferences, social perception better predicts participants' revealed preferences than does objective performance. Given these results, we recommend human-agent interaction researchers routinely incorporate the measurement of social perception and subjective preferences into their studies.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper examines the factors that shape human preferences for cooperating with AI agents trained using deep reinforcement learning.
- The researchers conducted a study where participants interacted with different AI agents and measured their impressions of the agents' warmth and competence, as well as their stated and revealed preferences for working with those agents.
- The study found that participants' perceptions of the agents' social attributes (warmth and competence) better predicted their preferences than the agents' objective performance metrics.
Plain English Explanation
As AI models become more advanced, researchers are interested in understanding how humans interact and cooperate with AI agents. This paper explores the factors that influence human preferences for working with different AI agents.
The researchers trained AI agents using a technique called deep reinforcement learning and had human participants interact with these agents in a two-player game. They measured not only how well the agents performed at the game, but also how the participants perceived the agents in terms of warmth and competence. Surprisingly, the participants' subjective impressions of the agents' social attributes were better at predicting the participants' preferences for working with the agents than the agents' actual performance.
Chatbots as social companions have shown that people's perceptions of an AI's social qualities can heavily influence how they interact with it. This paper suggests that this principle also applies to more complex AI agents designed for collaboration. The researchers found that people tended to prefer working with agents they saw as warm and competent, even if those agents didn't perform as well objectively.
Technical Explanation
The researchers trained deep reinforcement learning agents to play a two-player "Coins" game, which involves a social dilemma where individual and collective interests can conflict. They then recruited 501 participants to interact with these agents and measured their impressions of the agents' warmth and competence, as well as their stated preferences for working with the agents and their revealed preferences (whether they chose to play the next round with the same agent or alone).
The results showed that participants' perceptions of the agents' warmth and competence were more predictive of their preferences than the agents' actual task performance. Even when the agents performed similarly on objective metrics, participants tended to prefer working with the agents they saw as more warm and competent.
Building on social choice theory and research on human-AI collaboration, the researchers implemented a "partner choice" framework to elicit revealed preferences. After playing a round with an agent, participants could choose whether to continue working with that agent or play the next round alone. Again, social perception was a better predictor of these revealed preferences than objective performance.
Critical Analysis
The researchers acknowledge several limitations of their study. First, the Coins game may not fully capture the complexity of real-world human-AI collaboration scenarios. Additionally, the study only examined a single interaction episode, whereas long-term collaboration may reveal different dynamics.
The researchers also note that their study focused on a specific type of AI agent (trained via deep reinforcement learning) and a particular task domain. Designing human-agent alignment in other contexts may require different approaches.
While the results highlight the importance of social perception in human-AI interaction, further research is needed to fully understand the mechanisms underlying these effects and how they may vary across different populations and tasks. Addressing these limitations could lead to more robust insights for developing AI systems that can effectively collaborate with humans.
Conclusion
This study suggests that the subjective social attributes of AI agents, such as perceived warmth and competence, can play a vital role in shaping human preferences for collaboration, even when the agents' objective performance is similar. These findings highlight the need for AI researchers to consider not only task-based metrics, but also the social and relational aspects of human-AI interaction when designing and evaluating collaborative AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Negotiating the Shared Agency between Humans & AI in the Recommender System
Mengke Wu, Weizi Liu, Yanyun Wang, Mike Yao
0
0
Smart recommendation algorithms have revolutionized information dissemination, enhancing efficiency and reshaping content delivery across various domains. However, concerns about user agency have arisen due to the inherent opacity (information asymmetry) and the nature of one-way output (power asymmetry) on algorithms. While both issues have been criticized by scholars via advocating explainable AI (XAI) and human-AI collaborative decision-making (HACD), few research evaluates their integrated effects on users, and few HACD discussions in recommender systems beyond improving and filtering the results. This study proposes an incubating idea as a missing step in HACD that allows users to control the degrees of AI-recommended content. Then, we integrate it with existing XAI to a flow prototype aimed at assessing the enhancement of user agency. We seek to understand how types of agency impact user perception and experience, and bring empirical evidence to refine the guidelines and designs for human-AI interactive systems.
4/23/2024
Deconstructing Human-AI Collaboration: Agency, Interaction, and Adaptation
Steffen Holter, Mennatallah El-Assady
0
0
As full AI-based automation remains out of reach in most real-world applications, the focus has instead shifted to leveraging the strengths of both human and AI agents, creating effective collaborative systems. The rapid advances in this area have yielded increasingly more complex systems and frameworks, while the nuance of their characterization has gotten more vague. Similarly, the existing conceptual models no longer capture the elaborate processes of these systems nor describe the entire scope of their collaboration paradigms. In this paper, we propose a new unified set of dimensions through which to analyze and describe human-AI systems. Our conceptual model is centered around three high-level aspects - agency, interaction, and adaptation - and is developed through a multi-step process. Firstly, an initial design space is proposed by surveying the literature and consolidating existing definitions and conceptual frameworks. Secondly, this model is iteratively refined and validated by conducting semi-structured interviews with nine researchers in this field. Lastly, to illustrate the applicability of our design space, we utilize it to provide a structured description of selected human-AI systems.
4/19/2024
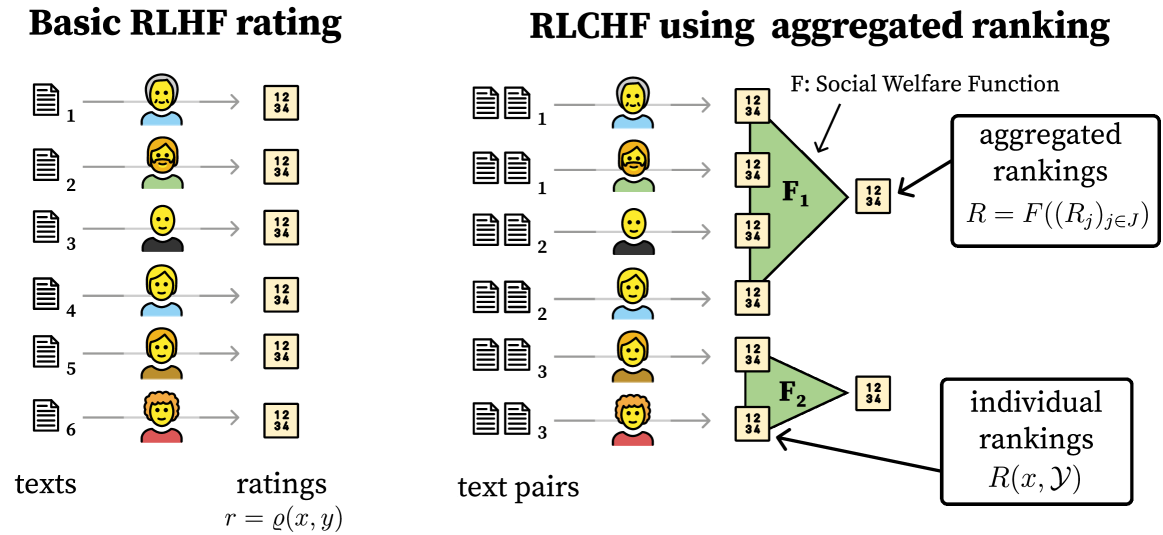
Social Choice for AI Alignment: Dealing with Diverse Human Feedback
Vincent Conitzer, Rachel Freedman, Jobst Heitzig, Wesley H. Holliday, Bob M. Jacobs, Nathan Lambert, Milan Moss'e, Eric Pacuit, Stuart Russell, Hailey Schoelkopf, Emanuel Tewolde, William S. Zwicker
0
0
Foundation models such as GPT-4 are fine-tuned to avoid unsafe or otherwise problematic behavior, so that, for example, they refuse to comply with requests for help with committing crimes or with producing racist text. One approach to fine-tuning, called reinforcement learning from human feedback, learns from humans' expressed preferences over multiple outputs. Another approach is constitutional AI, in which the input from humans is a list of high-level principles. But how do we deal with potentially diverging input from humans? How can we aggregate the input into consistent data about ''collective'' preferences or otherwise use it to make collective choices about model behavior? In this paper, we argue that the field of social choice is well positioned to address these questions, and we discuss ways forward for this agenda, drawing on discussions in a recent workshop on Social Choice for AI Ethics and Safety held in Berkeley, CA, USA in December 2023.
4/17/2024
🤔
Designing for Human-Agent Alignment: Understanding what humans want from their agents
Nitesh Goyal, Minsuk Chang, Michael Terry
0
0
Our ability to build autonomous agents that leverage Generative AI continues to increase by the day. As builders and users of such agents it is unclear what parameters we need to align on before the agents start performing tasks on our behalf. To discover these parameters, we ran a qualitative empirical research study about designing agents that can negotiate during a fictional yet relatable task of selling a camera online. We found that for an agent to perform the task successfully, humans/users and agents need to align over 6 dimensions: 1) Knowledge Schema Alignment 2) Autonomy and Agency Alignment 3) Operational Alignment and Training 4) Reputational Heuristics Alignment 5) Ethics Alignment and 6) Human Engagement Alignment. These empirical findings expand previous work related to process and specification alignment and the need for values and safety in Human-AI interactions. Subsequently we discuss three design directions for designers who are imagining a world filled with Human-Agent collaborations.
4/9/2024