WARP: On the Benefits of Weight Averaged Rewarded Policies
2406.16768
2
0

Abstract
Reinforcement learning from human feedback (RLHF) aligns large language models (LLMs) by encouraging their generations to have high rewards, using a reward model trained on human preferences. To prevent the forgetting of pre-trained knowledge, RLHF usually incorporates a KL regularization; this forces the policy to remain close to its supervised fine-tuned initialization, though it hinders the reward optimization. To tackle the trade-off between KL and reward, in this paper we introduce a novel alignment strategy named Weight Averaged Rewarded Policies (WARP). WARP merges policies in the weight space at three distinct stages. First, it uses the exponential moving average of the policy as a dynamic anchor in the KL regularization. Second, it applies spherical interpolation to merge independently fine-tuned policies into a new enhanced one. Third, it linearly interpolates between this merged model and the initialization, to recover features from pre-training. This procedure is then applied iteratively, with each iteration's final model used as an advanced initialization for the next, progressively refining the KL-reward Pareto front, achieving superior rewards at fixed KL. Experiments with GEMMA policies validate that WARP improves their quality and alignment, outperforming other open-source LLMs.
Create account to get full access
Overview
- This paper introduces WARP (Weight Averaged Rewarded Policies), a novel reinforcement learning algorithm that can lead to improved performance and stability compared to standard reinforcement learning methods.
- WARP works by maintaining a running average of the agent's policy weights, which are then used to generate the agent's actions. This approach can help smooth out the policy updates and make the learning process more stable.
- The authors demonstrate the benefits of WARP on a range of reinforcement learning benchmarks, showing that it can outperform standard methods in terms of both performance and sample efficiency.
Plain English Explanation
The WARP: On the Benefits of Weight Averaged Rewarded Policies paper presents a new way to train reinforcement learning (RL) agents. In standard RL, the agent's policy (the way it decides what actions to take) is updated after each interaction with the environment. However, these policy updates can be unstable, leading to suboptimal performance.
The key idea behind WARP is to maintain a running average of the agent's policy weights, rather than just using the latest weights. This "weight averaging" approach can help smooth out the policy updates and make the learning process more stable. As a result, WARP agents can often achieve better performance and learn more efficiently compared to standard RL methods.
The authors test WARP on a variety of RL benchmark tasks, such as Online Merging of Optimizers for Boosting Rewards and Mitigating Tax and Improving Reward-Conditioned Policies using Multi-Armed Bandits. They find that WARP consistently outperforms standard RL algorithms, demonstrating the benefits of the weight averaging approach.
Technical Explanation
The WARP: On the Benefits of Weight Averaged Rewarded Policies paper introduces a novel reinforcement learning algorithm called WARP (Weight Averaged Rewarded Policies). WARP maintains a running average of the agent's policy weights, which are then used to generate the agent's actions.
Specifically, the WARP algorithm maintains two sets of policy weights: the current weights, which are used to generate actions, and the averaged weights, which are updated as a weighted average of the current weights and the previous averaged weights. The authors show that this weight averaging approach can lead to more stable and efficient learning compared to standard reinforcement learning methods.
The authors evaluate WARP on a range of reinforcement learning benchmarks, including Gaussian Stochastic Weight Averaging for Bayesian Low-Rank Approximation and Information-Theoretic Guarantees for Policy Alignment in Large Language Models. They find that WARP consistently outperforms standard RL algorithms in terms of both performance and sample efficiency.
Critical Analysis
The WARP: On the Benefits of Weight Averaged Rewarded Policies paper presents a promising new approach to reinforcement learning, but it also has some potential limitations and areas for further research.
One potential limitation is that the weight averaging technique may not be as effective in tasks with highly dynamic or rapidly changing environments, where the agent needs to be able to adapt quickly to new situations. The authors acknowledge this and suggest that WARP may be most beneficial in more stable or slowly changing environments.
Additionally, the paper does not provide a detailed theoretical analysis of the properties of the weight averaging approach, such as its convergence guarantees or the conditions under which it is most effective. Further theoretical work in this area could help provide a deeper understanding of the algorithm and its limitations.
Finally, while the authors demonstrate the benefits of WARP on a range of benchmark tasks, it would be interesting to see how the algorithm performs on more complex, real-world reinforcement learning problems. Applying WARP to challenging domains like robotics, autonomous driving, or large-scale decision-making could provide valuable insights into its practical applicability and limitations.
Conclusion
The WARP: On the Benefits of Weight Averaged Rewarded Policies paper introduces a novel reinforcement learning algorithm that maintains a running average of the agent's policy weights. This weight averaging approach can lead to more stable and efficient learning compared to standard RL methods, as demonstrated by the authors' experiments on a range of benchmark tasks.
While the paper has some limitations and areas for further research, the WARP algorithm represents an interesting and potentially impactful contribution to the field of reinforcement learning. As the field continues to advance, techniques like WARP could help pave the way for more robust and reliable RL systems with applications across a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
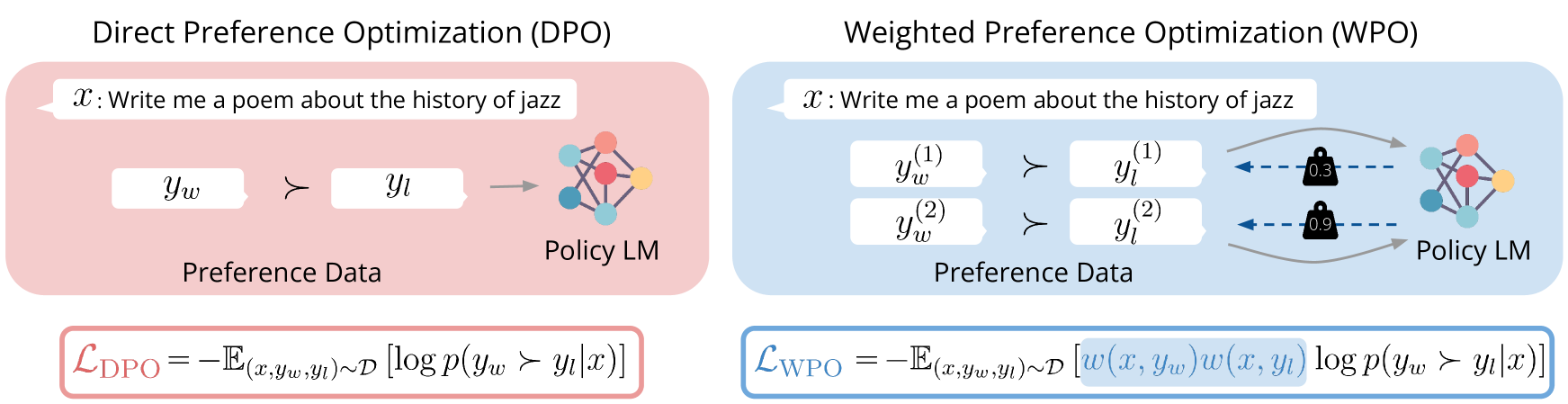
WPO: Enhancing RLHF with Weighted Preference Optimization
Wenxuan Zhou, Ravi Agrawal, Shujian Zhang, Sathish Reddy Indurthi, Sanqiang Zhao, Kaiqiang Song, Silei Xu, Chenguang Zhu
0
0
Reinforcement learning from human feedback (RLHF) is a promising solution to align large language models (LLMs) more closely with human values. Off-policy preference optimization, where the preference data is obtained from other models, is widely adopted due to its cost efficiency and scalability. However, off-policy preference optimization often suffers from a distributional gap between the policy used for data collection and the target policy, leading to suboptimal optimization. In this paper, we propose a novel strategy to mitigate this problem by simulating on-policy learning with off-policy preference data. Our Weighted Preference Optimization (WPO) method adapts off-policy data to resemble on-policy data more closely by reweighting preference pairs according to their probability under the current policy. This method not only addresses the distributional gap problem but also enhances the optimization process without incurring additional costs. We validate our method on instruction following benchmarks including Alpaca Eval 2 and MT-bench. WPO not only outperforms Direct Preference Optimization (DPO) by up to 5.6% on Alpaca Eval 2 but also establishes a remarkable length-controlled winning rate against GPT-4-turbo of 48.6% based on Llama-3-8B-Instruct, making it the strongest 8B model on the leaderboard. We will release the code and models at https://github.com/wzhouad/WPO.
6/18/2024
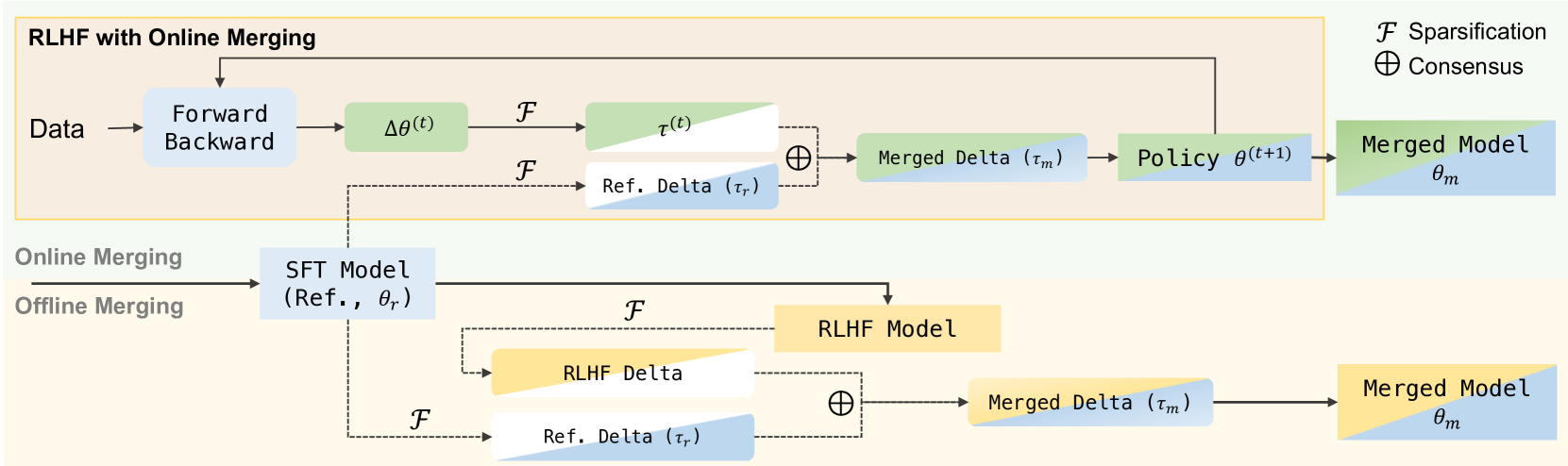
Online Merging Optimizers for Boosting Rewards and Mitigating Tax in Alignment
Keming Lu, Bowen Yu, Fei Huang, Yang Fan, Runji Lin, Chang Zhou
0
0
Effectively aligning Large Language Models (LLMs) with human-centric values while preventing the degradation of abilities acquired through Pre-training and Supervised Fine-tuning (SFT) poses a central challenge in Reinforcement Learning from Human Feedback (RLHF). In this paper, we first discover that interpolating RLHF and SFT model parameters can adjust the trade-off between human preference and basic capabilities, thereby reducing the alignment tax at the cost of alignment reward. Inspired by this, we propose integrating the RL policy and SFT models at each optimization step in RLHF to continuously regulate the training direction, introducing the Online Merging Optimizer. Specifically, we merge gradients with the parameter differences between SFT and pretrained models, effectively steering the gradient towards maximizing rewards in the direction of SFT optimization. We demonstrate that our optimizer works well with different LLM families, such as Qwen and LLaMA, across various model sizes ranging from 1.8B to 8B, various RLHF algorithms like DPO and KTO, and existing model merging methods. It significantly enhances alignment reward while mitigating alignment tax, achieving higher overall performance across 14 benchmarks.
5/29/2024
Improving Reward-Conditioned Policies for Multi-Armed Bandits using Normalized Weight Functions
Kai Xu, Farid Tajaddodianfar, Ben Allison
0
0
Recently proposed reward-conditioned policies (RCPs) offer an appealing alternative in reinforcement learning. Compared with policy gradient methods, policy learning in RCPs is simpler since it is based on supervised learning, and unlike value-based methods, it does not require optimization in the action space to take actions. However, for multi-armed bandit (MAB) problems, we find that RCPs are slower to converge and have inferior expected rewards at convergence, compared with classic methods such as the upper confidence bound and Thompson sampling. In this work, we show that the performance of RCPs can be enhanced by constructing policies through the marginalization of rewards using normalized weight functions, whose sum or integral equal $1$, although the function values may be negative. We refer to this technique as generalized marginalization, whose advantage is that negative weights for policies conditioned on low rewards can make the resulting policies more distinct from them. Strategies to perform generalized marginalization in MAB with discrete action spaces are studied. Through simulations, we demonstrate that the proposed technique improves RCPs and makes them competitive with classic methods, showing superior performance on challenging MABs with large action spaces and sparse reward signals.
6/18/2024

Contrastive Policy Gradient: Aligning LLMs on sequence-level scores in a supervised-friendly fashion
Yannis Flet-Berliac, Nathan Grinsztajn, Florian Strub, Eugene Choi, Chris Cremer, Arash Ahmadian, Yash Chandak, Mohammad Gheshlaghi Azar, Olivier Pietquin, Matthieu Geist
0
0
Reinforcement Learning (RL) has been used to finetune Large Language Models (LLMs) using a reward model trained from preference data, to better align with human judgment. The recently introduced direct alignment methods, which are often simpler, more stable, and computationally lighter, can more directly achieve this. However, these approaches cannot optimize arbitrary rewards, and the preference-based ones are not the only rewards of interest for LLMs (eg., unit tests for code generation or textual entailment for summarization, among others). RL-finetuning is usually done with a variation of policy gradient, which calls for on-policy or near-on-policy samples, requiring costly generations. We introduce Contrastive Policy Gradient, or CoPG, a simple and mathematically principled new RL algorithm that can estimate the optimal policy even from off-policy data. It can be seen as an off-policy policy gradient approach that does not rely on important sampling techniques and highlights the importance of using (the right) state baseline. We show this approach to generalize the direct alignment method IPO (identity preference optimization) and classic policy gradient. We experiment with the proposed CoPG on a toy bandit problem to illustrate its properties, as well as for finetuning LLMs on a summarization task, using a learned reward function considered as ground truth for the purpose of the experiments.
6/28/2024