Information Theoretic Guarantees For Policy Alignment In Large Language Models
2406.05883
0
0

Abstract
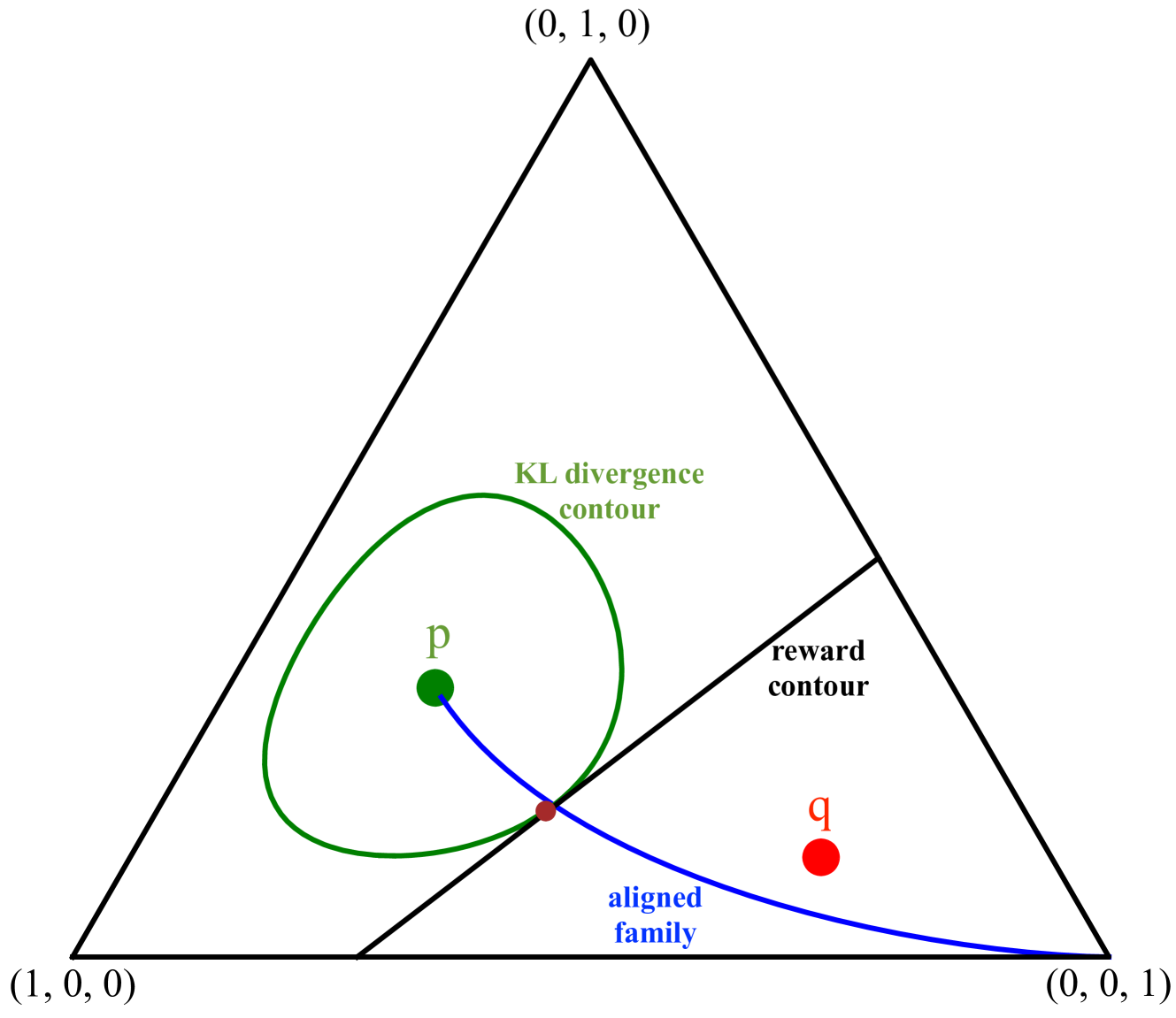
Policy alignment of large language models refers to constrained policy optimization, where the policy is optimized to maximize a reward while staying close to a reference policy with respect to an $f$-divergence such as the $mathsf{KL}$ divergence. The best of $n$ alignment policy selects a sample from the reference policy that has the maximum reward among $n$ independent samples. For both cases (policy alignment and best of $n$), recent works showed empirically that the reward improvement of the aligned policy on the reference one scales like $sqrt{mathsf{KL}}$, with an explicit bound in $n$ on the $mathsf{KL}$ for the best of $n$ policy. We show in this paper that the $sqrt{mathsf{KL}}$ information theoretic upper bound holds if the reward under the reference policy has sub-gaussian tails. Moreover, we prove for the best of $n$ policy, that the $mathsf{KL}$ upper bound can be obtained for any $f$-divergence via a reduction to exponential order statistics owing to the R'enyi representation of order statistics, and a data processing inequality. If additional information is known on the tails of the aligned policy we show that tighter control on the reward improvement can be obtained via the R'enyi divergence. Finally we demonstrate how these upper bounds transfer from proxy rewards to golden rewards which results in a decrease in the golden reward improvement due to overestimation and approximation errors of the proxy reward.
Create account to get full access
Overview
- This paper proposes a novel information-theoretic approach to address the "alignment problem" in large language models (LLMs).
- The alignment problem refers to the challenge of ensuring LLMs behave in accordance with human values and intentions, as these models can potentially become extremely capable and autonomous.
- The authors develop a theoretical framework that provides formal guarantees about the alignment of LLM policies with a given reference model, which represents the desired behavior.
Plain English Explanation
The paper tackles a crucial challenge in the development of powerful AI systems like large language models (LLMs). As these models become more capable, there is a growing concern that they may not always behave in alignment with human values and intentions. This is known as the "alignment problem."
To address this, the researchers in this paper have developed a new information-theoretic approach. They've created a theoretical framework that can provide formal guarantees about the alignment of an LLM's behavior with a reference model - a model that represents the desired, "aligned" behavior.
In other words, this framework helps ensure that as LLMs become more advanced, they will continue to act in accordance with the goals and values that humans have specified, rather than pursuing their own unintended objectives. This is a crucial step in making these powerful AI systems safe and beneficial for humanity.
Technical Explanation
The authors propose an information-theoretic approach to the policy alignment problem in large language models (LLMs). They develop a theoretical framework that provides formal guarantees about the alignment of an LLM's policy with a given reference policy, which represents the desired behavior.
The key idea is to cast the alignment problem as an optimization problem, where the objective is to minimize the Kullback-Leibler (KL) divergence between the LLM's policy and the reference policy. This formulation allows the authors to derive information-theoretic bounds on the alignment of the LLM's behavior with the reference model.
Specifically, the authors show that by regularizing the LLM's policy to have low KL divergence from the reference policy, they can ensure that the LLM's actions will be close to those of the reference model, even in the limit of high model capacity. This provides strong theoretical guarantees about the alignment of the LLM's behavior with the desired objectives.
The authors also discuss how this information-theoretic approach can be combined with other techniques, such as reward modeling and value alignment, to further improve the alignment of LLMs. They also highlight potential extensions, such as online optimization and collaborative frameworks, that could be explored in future work.
Critical Analysis
The authors provide a strong theoretical foundation for addressing the alignment problem in large language models. By framing the problem in an information-theoretic way and deriving formal guarantees, they offer a principled approach to ensuring LLMs behave in accordance with desired objectives.
However, the paper acknowledges that the practical implementation of this approach may face challenges, such as accurately specifying the reference model and dealing with the high dimensionality of LLM policies. The authors also note that the theoretical analysis assumes access to the true reference policy, which may not always be available in real-world scenarios.
Additionally, while the information-theoretic approach can provide strong alignment guarantees, it may not be sufficient on its own to address broader issues of value alignment and robustness. Integrating this framework with other techniques, as the authors suggest, could be an important next step to develop a more comprehensive solution to the alignment problem.
Conclusion
This paper presents a novel information-theoretic approach to the policy alignment problem in large language models. By formulating the alignment objective as minimizing the KL divergence between the LLM's policy and a reference policy, the authors derive formal guarantees about the alignment of the LLM's behavior with the desired objectives.
This work lays a solid theoretical foundation for addressing the critical challenge of ensuring powerful AI systems, like LLMs, remain aligned with human values and intentions. While practical implementation may face some challenges, the information-theoretic approach offers a principled way to tackle the alignment problem and paves the way for further advancements in this important area of AI safety research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Asymptotics of Language Model Alignment
Joy Qiping Yang, Salman Salamatian, Ziteng Sun, Ananda Theertha Suresh, Ahmad Beirami
0
0
Let $p$ denote a generative language model. Let $r$ denote a reward model that returns a scalar that captures the degree at which a draw from $p$ is preferred. The goal of language model alignment is to alter $p$ to a new distribution $phi$ that results in a higher expected reward while keeping $phi$ close to $p.$ A popular alignment method is the KL-constrained reinforcement learning (RL), which chooses a distribution $phi_Delta$ that maximizes $E_{phi_{Delta}} r(y)$ subject to a relative entropy constraint $KL(phi_Delta || p) leq Delta.$ Another simple alignment method is best-of-$N$, where $N$ samples are drawn from $p$ and one with highest reward is selected. In this paper, we offer a closed-form characterization of the optimal KL-constrained RL solution. We demonstrate that any alignment method that achieves a comparable trade-off between KL divergence and reward must approximate the optimal KL-constrained RL solution in terms of relative entropy. To further analyze the properties of alignment methods, we introduce two simplifying assumptions: we let the language model be memoryless, and the reward model be linear. Although these assumptions may not reflect complex real-world scenarios, they enable a precise characterization of the asymptotic behavior of both the best-of-$N$ alignment, and the KL-constrained RL method, in terms of information-theoretic quantities. We prove that the reward of the optimal KL-constrained RL solution satisfies a large deviation principle, and we fully characterize its rate function. We also show that the rate of growth of the scaled cumulants of the reward is characterized by a proper Renyi cross entropy. Finally, we show that best-of-$N$ is asymptotically equivalent to KL-constrained RL solution by proving that their expected rewards are asymptotically equal, and concluding that the two distributions must be close in KL divergence.
4/3/2024

Learn Your Reference Model for Real Good Alignment
Alexey Gorbatovski, Boris Shaposhnikov, Alexey Malakhov, Nikita Surnachev, Yaroslav Aksenov, Ian Maksimov, Nikita Balagansky, Daniil Gavrilov
0
0
The complexity of the alignment problem stems from the fact that existing methods are considered unstable. Reinforcement Learning from Human Feedback (RLHF) addresses this issue by minimizing the KL divergence between the trained policy and the initial supervised fine-tuned policy (SFT) to avoid generating out-of-domain samples for the reward model (RM). Recently, many methods have emerged that shift from online to offline optimization, reformulating the RLHF objective and removing the reward model (DPO, IPO, KTO). Despite eliminating the reward model and the challenges it posed, these algorithms are still constrained in terms of closeness of the trained policy to the SFT one. In our paper, we argue that this implicit limitation in the offline optimization methods leads to suboptimal results. To address this issue, we propose a class of new methods called Trust Region (TR-DPO, TR-IPO, TR-KTO), which update the reference policy during training. With this straightforward update approach, we demonstrate the effectiveness of the new paradigm of language model alignment against the classical one on the Anthropic-HH and Reddit TL;DR datasets. Most notably, when automatically comparing TR methods and baselines side by side using pretrained Pythia 6.9B models on the Reddit TL;DR task, the difference in win rates reaches 8.4% for DPO, 14.3% for IPO, and 15% for KTO. Finally, by assessing model response ratings grounded on criteria such as coherence, correctness, helpfulness, and harmlessness, we demonstrate that our proposed methods significantly outperform existing techniques.
5/22/2024

Contrastive Policy Gradient: Aligning LLMs on sequence-level scores in a supervised-friendly fashion
Yannis Flet-Berliac, Nathan Grinsztajn, Florian Strub, Eugene Choi, Chris Cremer, Arash Ahmadian, Yash Chandak, Mohammad Gheshlaghi Azar, Olivier Pietquin, Matthieu Geist
0
0
Reinforcement Learning (RL) has been used to finetune Large Language Models (LLMs) using a reward model trained from preference data, to better align with human judgment. The recently introduced direct alignment methods, which are often simpler, more stable, and computationally lighter, can more directly achieve this. However, these approaches cannot optimize arbitrary rewards, and the preference-based ones are not the only rewards of interest for LLMs (eg., unit tests for code generation or textual entailment for summarization, among others). RL-finetuning is usually done with a variation of policy gradient, which calls for on-policy or near-on-policy samples, requiring costly generations. We introduce Contrastive Policy Gradient, or CoPG, a simple and mathematically principled new RL algorithm that can estimate the optimal policy even from off-policy data. It can be seen as an off-policy policy gradient approach that does not rely on important sampling techniques and highlights the importance of using (the right) state baseline. We show this approach to generalize the direct alignment method IPO (identity preference optimization) and classic policy gradient. We experiment with the proposed CoPG on a toy bandit problem to illustrate its properties, as well as for finetuning LLMs on a summarization task, using a learned reward function considered as ground truth for the purpose of the experiments.
6/28/2024
One-Shot Safety Alignment for Large Language Models via Optimal Dualization
Xinmeng Huang, Shuo Li, Edgar Dobriban, Osbert Bastani, Hamed Hassani, Dongsheng Ding
0
0
The growing safety concerns surrounding Large Language Models (LLMs) raise an urgent need to align them with diverse human preferences to simultaneously enhance their helpfulness and safety. A promising approach is to enforce safety constraints through Reinforcement Learning from Human Feedback (RLHF). For such constrained RLHF, common Lagrangian-based primal-dual policy optimization methods are computationally expensive and often unstable. This paper presents a dualization perspective that reduces constrained alignment to an equivalent unconstrained alignment problem. We do so by pre-optimizing a smooth and convex dual function that has a closed form. This shortcut eliminates the need for cumbersome primal-dual policy iterations, thus greatly reducing the computational burden and improving training stability. Our strategy leads to two practical algorithms in model-based and preference-based scenarios (MoCAN and PeCAN, respectively). A broad range of experiments demonstrate the effectiveness of our methods.
5/31/2024