WayveScenes101: A Dataset and Benchmark for Novel View Synthesis in Autonomous Driving

0

Sign in to get full access
Overview
- The paper presents a new dataset, called WayveScenes101, for evaluating novel view synthesis in autonomous driving scenarios.
- Novel view synthesis is the task of generating new images of a scene from different viewpoints, which is important for applications like self-driving cars.
- The dataset contains over 100,000 panoramic images captured from cameras mounted on vehicles, providing diverse driving scenes across different environments and weather conditions.
- The authors also propose a novel view synthesis benchmark to evaluate the performance of machine learning models on this task using the WayveScenes101 dataset.
Plain English Explanation
The researchers have created a new dataset called WayveScenes101 that can be used to train and test machine learning models for generating new images of driving scenes from different perspectives. This is a key capability for self-driving cars, as they need to be able to understand the world around them from various viewpoints to navigate safely.
The dataset contains over 100,000 panoramic images captured from cameras mounted on vehicles driving in diverse environments and weather conditions. This provides a rich and varied set of driving scenes for models to learn from and be evaluated on.
The authors have also defined a benchmark for assessing the performance of novel view synthesis models using the WayveScenes101 dataset. This will allow researchers to compare the effectiveness of different approaches and track progress in this important area of autonomous driving technology.
Technical Explanation
The paper introduces a new large-scale dataset called WayveScenes101 for evaluating novel view synthesis in the context of autonomous driving. The dataset contains over 100,000 panoramic images captured from cameras mounted on vehicles, providing a diverse set of driving scenes across different environments, weather conditions, and times of day.
The authors propose a novel view synthesis benchmark to evaluate the performance of machine learning models on this task using the WayveScenes101 dataset. The benchmark includes multiple evaluation metrics to assess the quality and fidelity of the synthesized views compared to ground-truth images.
The dataset and benchmark are designed to advance research in 3D scene understanding and view synthesis for autonomous driving applications, where being able to accurately predict and generate new views of the environment is crucial for safe navigation and decision-making.
Critical Analysis
The WayveScenes101 dataset and benchmark represent a valuable contribution to the field of autonomous driving, providing a standardized evaluation platform for novel view synthesis techniques. The dataset's diversity and scale make it a robust testbed for assessing the performance of machine learning models in this domain.
One potential limitation of the dataset is that it focuses on panoramic images, which may not fully capture the depth and spatial information required for some view synthesis approaches. Incorporating additional sensor modalities, such as depth maps or 3D point clouds, could further enhance the dataset's utility.
Furthermore, the paper does not provide detailed insights into the factors that influence the performance of novel view synthesis models on the benchmark. Analyzing the impact of specific scene characteristics, environmental conditions, or model architectures could yield useful insights for advancing the state-of-the-art in this area.
Conclusion
The WayveScenes101 dataset and benchmark represent an important step forward in the development of novel view synthesis capabilities for autonomous driving. By providing a large-scale and diverse dataset, along with a standardized evaluation framework, the authors have created a valuable resource for the research community to drive progress in this critical aspect of self-driving car technology. Continued advancements in this field could lead to improved environmental awareness, safer navigation, and more robust decision-making for autonomous vehicles.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
WayveScenes101: A Dataset and Benchmark for Novel View Synthesis in Autonomous Driving
Jannik Zurn, Paul Gladkov, Sof'ia Dudas, Fergal Cotter, Sofi Toteva, Jamie Shotton, Vasiliki Simaiaki, Nikhil Mohan
We present WayveScenes101, a dataset designed to help the community advance the state of the art in novel view synthesis that focuses on challenging driving scenes containing many dynamic and deformable elements with changing geometry and texture. The dataset comprises 101 driving scenes across a wide range of environmental conditions and driving scenarios. The dataset is designed for benchmarking reconstructions on in-the-wild driving scenes, with many inherent challenges for scene reconstruction methods including image glare, rapid exposure changes, and highly dynamic scenes with significant occlusion. Along with the raw images, we include COLMAP-derived camera poses in standard data formats. We propose an evaluation protocol for evaluating models on held-out camera views that are off-axis from the training views, specifically testing the generalisation capabilities of methods. Finally, we provide detailed metadata for all scenes, including weather, time of day, and traffic conditions, to allow for a detailed model performance breakdown across scene characteristics. Dataset and code are available at https://github.com/wayveai/wayve_scenes.
Read more7/12/2024

0
XLD: A Cross-Lane Dataset for Benchmarking Novel Driving View Synthesis
Hao Li, Ming Yuan, Yan Zhang, Chenming Wu, Chen Zhao, Chunyu Song, Haocheng Feng, Errui Ding, Dingwen Zhang, Jingdong Wang
Thoroughly testing autonomy systems is crucial in the pursuit of safe autonomous driving vehicles. It necessitates creating safety-critical scenarios that go beyond what can be safely collected from real-world data, as many of these scenarios occur infrequently on public roads. However, the evaluation of most existing NVS methods relies on sporadic sampling of image frames from the training data, comparing the rendered images with ground truth images using metrics. Unfortunately, this evaluation protocol falls short of meeting the actual requirements in closed-loop simulations. Specifically, the true application demands the capability to render novel views that extend beyond the original trajectory (such as cross-lane views), which are challenging to capture in the real world. To address this, this paper presents a novel driving view synthesis dataset and benchmark specifically designed for autonomous driving simulations. This dataset is unique as it includes testing images captured by deviating from the training trajectory by 1-4 meters. It comprises six sequences encompassing various time and weather conditions. Each sequence contains 450 training images, 150 testing images, and their corresponding camera poses and intrinsic parameters. Leveraging this novel dataset, we establish the first realistic benchmark for evaluating existing NVS approaches under front-only and multi-camera settings. The experimental findings underscore the significant gap that exists in current approaches, revealing their inadequate ability to fulfill the demanding prerequisites of cross-lane or closed-loop simulation. Our dataset is released publicly at the project page: https://3d-aigc.github.io/XLD/.
Read more6/28/2024
0
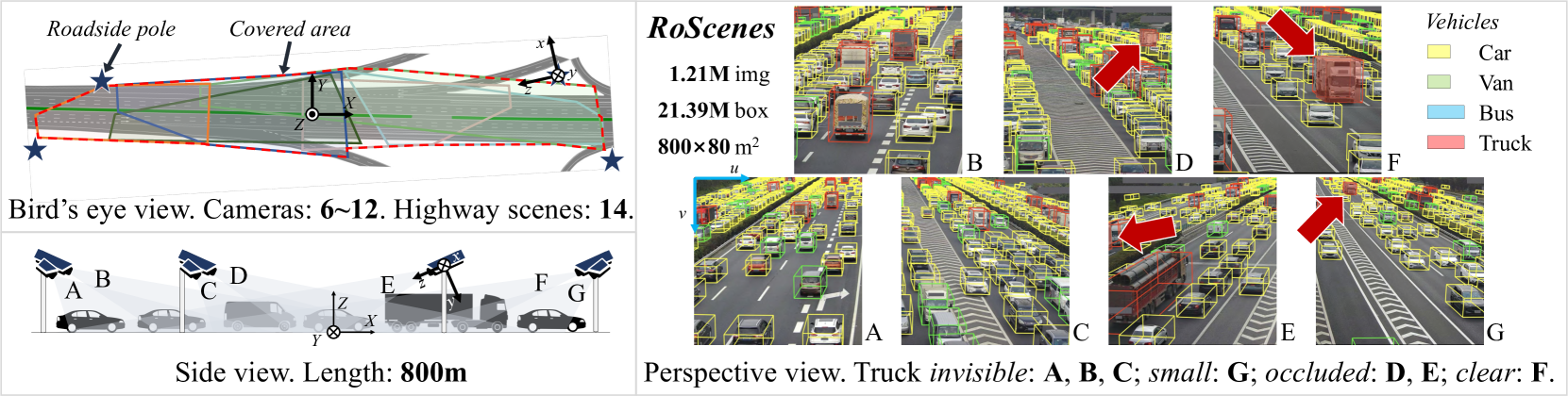
RoScenes: A Large-scale Multi-view 3D Dataset for Roadside Perception
Xiaosu Zhu, Hualian Sheng, Sijia Cai, Bing Deng, Shaopeng Yang, Qiao Liang, Ken Chen, Lianli Gao, Jingkuan Song, Jieping Ye
We introduce RoScenes, the largest multi-view roadside perception dataset, which aims to shed light on the development of vision-centric Bird's Eye View (BEV) approaches for more challenging traffic scenes. The highlights of RoScenes include significantly large perception area, full scene coverage and crowded traffic. More specifically, our dataset achieves surprising 21.13M 3D annotations within 64,000 $m^2$. To relieve the expensive costs of roadside 3D labeling, we present a novel BEV-to-3D joint annotation pipeline to efficiently collect such a large volume of data. After that, we organize a comprehensive study for current BEV methods on RoScenes in terms of effectiveness and efficiency. Tested methods suffer from the vast perception area and variation of sensor layout across scenes, resulting in performance levels falling below expectations. To this end, we propose RoBEV that incorporates feature-guided position embedding for effective 2D-3D feature assignment. With its help, our method outperforms state-of-the-art by a large margin without extra computational overhead on validation set. Our dataset and devkit will be made available at https://github.com/xiaosu-zhu/RoScenes.
Read more7/8/2024

0
360 in the Wild: Dataset for Depth Prediction and View Synthesis
Kibaek Park, Francois Rameau, Jaesik Park, In So Kweon
The large abundance of perspective camera datasets facilitated the emergence of novel learning-based strategies for various tasks, such as camera localization, single image depth estimation, or view synthesis. However, panoramic or omnidirectional image datasets, including essential information, such as pose and depth, are mostly made with synthetic scenes. In this work, we introduce a large scale 360$^{circ}$ videos dataset in the wild. This dataset has been carefully scraped from the Internet and has been captured from various locations worldwide. Hence, this dataset exhibits very diversified environments (e.g., indoor and outdoor) and contexts (e.g., with and without moving objects). Each of the 25K images constituting our dataset is provided with its respective camera's pose and depth map. We illustrate the relevance of our dataset for two main tasks, namely, single image depth estimation and view synthesis.
Read more7/8/2024