What is Your Data Worth to GPT? LLM-Scale Data Valuation with Influence Functions
2405.13954
0
0
📊
Abstract
Large language models (LLMs) are trained on a vast amount of human-written data, but data providers often remain uncredited. In response to this issue, data valuation (or data attribution), which quantifies the contribution or value of each data to the model output, has been discussed as a potential solution. Nevertheless, applying existing data valuation methods to recent LLMs and their vast training datasets has been largely limited by prohibitive compute and memory costs. In this work, we focus on influence functions, a popular gradient-based data valuation method, and significantly improve its scalability with an efficient gradient projection strategy called LoGra that leverages the gradient structure in backpropagation. We then provide a theoretical motivation of gradient projection approaches to influence functions to promote trust in the data valuation process. Lastly, we lower the barrier to implementing data valuation systems by introducing LogIX, a software package that can transform existing training code into data valuation code with minimal effort. In our data valuation experiments, LoGra achieves competitive accuracy against more expensive baselines while showing up to 6,500x improvement in throughput and 5x reduction in GPU memory usage when applied to Llama3-8B-Instruct and the 1B-token dataset.
Create account to get full access
Overview
- Large language models (LLMs) are trained on vast amounts of human-written data, but data providers often remain uncredited.
- Data valuation, which quantifies the contribution or value of each data point to the model output, has been proposed as a potential solution.
- Applying existing data valuation methods to recent LLMs and their vast training datasets has been limited by high computational and memory costs.
Plain English Explanation
Large language models are artificial intelligence systems that are trained on a massive amount of text data, such as books, websites, and social media posts, in order to understand and generate human-like language. However, the individuals or organizations that provided the data used to train these models are often not properly credited or recognized for their contributions.
To address this issue, researchers have explored the idea of data valuation, which is a way to quantify the importance or "value" of each piece of data used to train a model. By understanding which data points had the greatest impact on the model's outputs, it may be possible to better acknowledge and compensate the sources of that data.
One popular method for data valuation is called influence functions, which uses the gradients (or slopes) of the model during training to determine the influence of each data point. However, applying this technique to the massive datasets used to train modern LLMs has been challenging due to the high computational and memory requirements.
In this study, the researchers developed a more efficient approach called "LoGra" (short for Localized Gradient), which uses a clever trick to significantly reduce the computational and memory demands of the influence function method. This allows the researchers to apply data valuation techniques to LLMs and their vast datasets in a more practical way.
Technical Explanation
The researchers focused on influence functions, a popular gradient-based data valuation method, and developed an efficient gradient projection strategy called LoGra to improve its scalability. LoGra leverages the gradient structure in backpropagation to reduce the computational and memory requirements of influence functions.
The researchers also provided a theoretical motivation for gradient projection approaches to influence functions, aiming to promote trust in the data valuation process. Additionally, they introduced LogIX, a software package that can transform existing training code into data valuation code with minimal effort, lowering the barrier to implementing data valuation systems.
In their experiments, the researchers applied LoGra to the Llama3-8B-Instruct model and a 1B-token dataset. LoGra achieved competitive accuracy against more expensive baselines while showing up to 6,500x improvement in throughput and 5x reduction in GPU memory usage.
Critical Analysis
The researchers acknowledged that their LoGra approach, while significantly more efficient than previous methods, still has some limitations. Specifically, the method relies on certain assumptions about the structure of the gradients, and it may not be as accurate as more computationally intensive approaches in all cases.
Additionally, the researchers noted that their experiments were conducted on a relatively small LLM (Llama3-8B-Instruct) and a 1B-token dataset, which may not fully reflect the challenges of applying data valuation to the truly massive models and datasets used in industry. Further research may be needed to validate the effectiveness of LoGra on larger-scale LLMs and datasets.
It's also worth considering whether the goal of data valuation itself is the optimal solution to the problem of data provider attribution. While the approach may help recognize the contributions of data sources, there are likely other ethical and practical considerations that should be taken into account when addressing the issue of data provenance and credit.
Conclusion
This study presents a significant advancement in the field of data valuation for large language models. By developing the LoGra technique, the researchers have made it more feasible to apply influence function-based data valuation methods to the vast datasets used to train modern LLMs. This could potentially lead to better recognition and attribution of the individuals and organizations that contribute to the development of these powerful AI systems.
However, as with any research, there are still challenges and limitations that need to be addressed. Continued exploration of data valuation techniques, as well as broader discussions around the ethical and practical considerations of AI data provenance, will be important for ensuring the responsible development and deployment of large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
Token-wise Influential Training Data Retrieval for Large Language Models
Huawei Lin, Jikai Long, Zhaozhuo Xu, Weijie Zhao
0
0
Given a Large Language Model (LLM) generation, how can we identify which training data led to this generation? In this paper, we proposed RapidIn, a scalable framework adapting to LLMs for estimating the influence of each training data. The proposed framework consists of two stages: caching and retrieval. First, we compress the gradient vectors by over 200,000x, allowing them to be cached on disk or in GPU/CPU memory. Then, given a generation, RapidIn efficiently traverses the cached gradients to estimate the influence within minutes, achieving over a 6,326x speedup. Moreover, RapidIn supports multi-GPU parallelization to substantially accelerate caching and retrieval. Our empirical result confirms the efficiency and effectiveness of RapidIn.
5/21/2024

Global Data Constraints: Ethical and Effectiveness Challenges in Large Language Model
Jin Yang, Zhiqiang Wang, Yanbin Lin, Zunduo Zhao
0
0
The efficacy and ethical integrity of large language models (LLMs) are profoundly influenced by the diversity and quality of their training datasets. However, the global landscape of data accessibility presents significant challenges, particularly in regions with stringent data privacy laws or limited open-source information. This paper examines the multifaceted challenges associated with acquiring high-quality training data for LLMs, focusing on data scarcity, bias, and low-quality content across various linguistic contexts. We highlight the technical and ethical implications of relying on publicly available but potentially biased or irrelevant data sources, which can lead to the generation of biased or hallucinatory content by LLMs. Through a series of evaluations using GPT-4 and GPT-4o, we demonstrate how these data constraints adversely affect model performance and ethical alignment. We propose and validate several mitigation strategies designed to enhance data quality and model robustness, including advanced data filtering techniques and ethical data collection practices. Our findings underscore the need for a proactive approach in developing LLMs that considers both the effectiveness and ethical implications of data constraints, aiming to foster the creation of more reliable and universally applicable AI systems.
6/18/2024
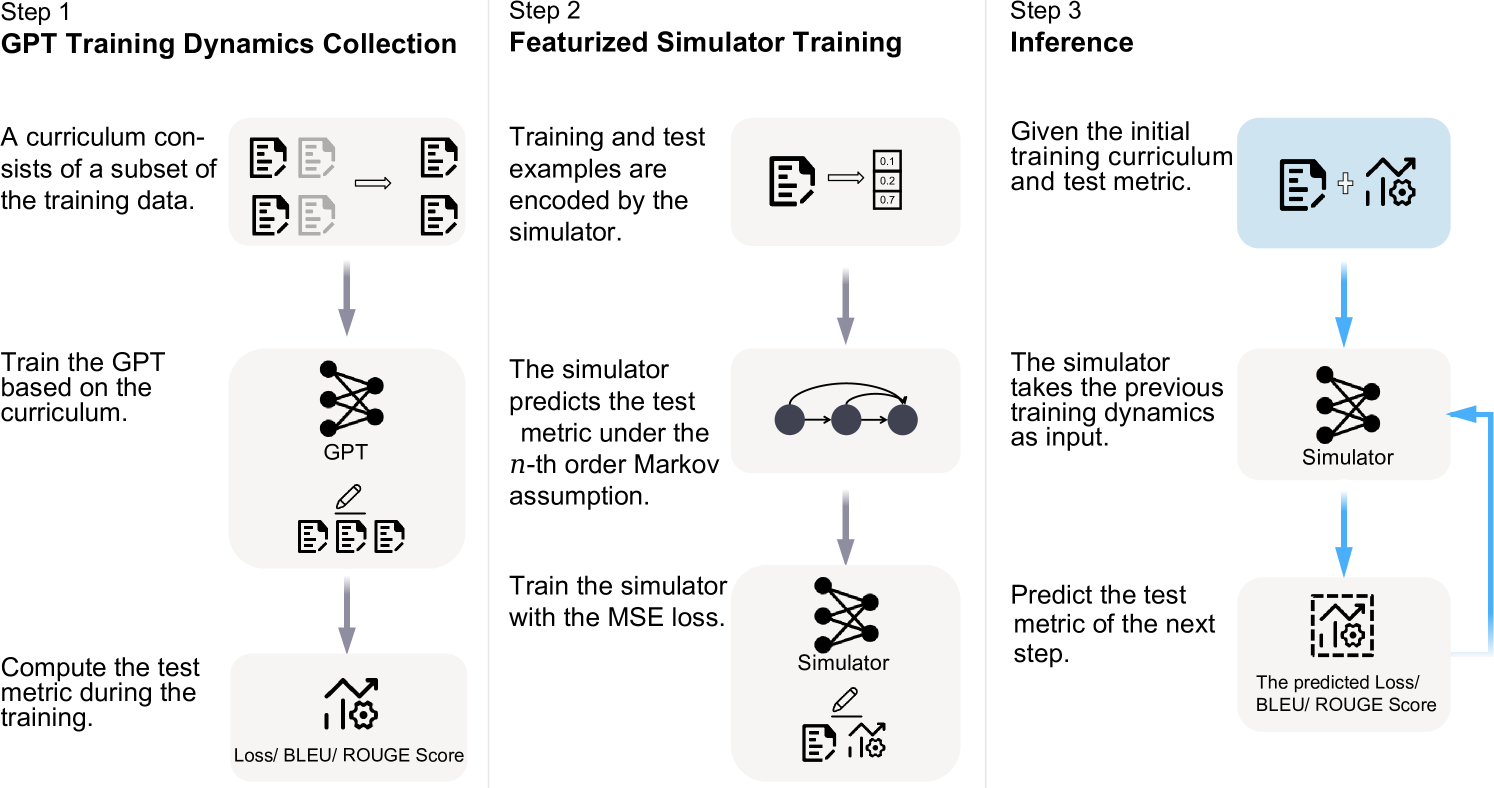
On Training Data Influence of GPT Models
Qingyi Liu, Yekun Chai, Shuohuan Wang, Yu Sun, Qiwei Peng, Keze Wang, Hua Wu
0
0
Amidst the rapid advancements in generative language models, the investigation of how training data shapes the performance of GPT models is still emerging. This paper presents GPTfluence, a novel approach that leverages a featurized simulation to assess the impact of training examples on the training dynamics of GPT models. Our approach not only traces the influence of individual training instances on performance trajectories, such as loss and other key metrics, on targeted test points but also enables a comprehensive comparison with existing methods across various training scenarios in GPT models, ranging from 14 million to 2.8 billion parameters, across a range of downstream tasks. Contrary to earlier methods that struggle with generalization to new data, GPTfluence introduces a parameterized simulation of training dynamics, demonstrating robust generalization capabilities to unseen training data. This adaptability is evident across both fine-tuning and instruction-tuning scenarios, spanning tasks in natural language understanding and generation. We will make our code and data publicly available.
4/17/2024

Towards Optimizing with Large Language Models
Pei-Fu Guo, Ying-Hsuan Chen, Yun-Da Tsai, Shou-De Lin
0
0
In this work, we conduct an assessment of the optimization capabilities of LLMs across various tasks and data sizes. Each of these tasks corresponds to unique optimization domains, and LLMs are required to execute these tasks with interactive prompting. That is, in each optimization step, the LLM generates new solutions from the past generated solutions with their values, and then the new solutions are evaluated and considered in the next optimization step. Additionally, we introduce three distinct metrics for a comprehensive assessment of task performance from various perspectives. These metrics offer the advantage of being applicable for evaluating LLM performance across a broad spectrum of optimization tasks and are less sensitive to variations in test samples. By applying these metrics, we observe that LLMs exhibit strong optimization capabilities when dealing with small-sized samples. However, their performance is significantly influenced by factors like data size and values, underscoring the importance of further research in the domain of optimization tasks for LLMs.
5/28/2024