What's in a Name? Beyond Class Indices for Image Recognition

0
🖼️
Sign in to get full access
Overview
- Existing machine learning models excel at image object recognition, but they only learn to map images to predefined class indices without revealing the actual semantic meaning of the objects.
- Vision-language models like CLIP can assign semantic class names to unseen objects in a 'zero-shot' manner, but they are provided a pre-defined set of candidate names at test-time.
- This paper proposes a new approach that tasks a vision-language model with assigning class names to images given a large, unconstrained vocabulary of categories as prior information.
- The method leverages non-parametric methods to establish meaningful relationships between images, allowing the model to automatically narrow down the pool of candidate names.
- The paper investigates the potential of incorporating additional textual features to enhance clustering performance.
Plain English Explanation
Traditional machine learning models for image object recognition are very good at identifying objects in images and assigning them to predefined categories. However, these models don't actually understand the semantic meaning of the objects they're identifying - they just match the image to a number representing a class.
In contrast, vision-language models like CLIP can assign actual words or class names to objects in 'zero-shot' fashion, meaning they can recognize objects they weren't specifically trained on. But these models are still limited to a predefined set of class names they can choose from.
This paper proposes a new approach that gives the vision-language model a much larger, unconstrained vocabulary of potential class names to choose from. The key idea is to use non-parametric methods to group similar images together and then have the model vote on the most appropriate class name for each group. This allows the model to go beyond the predefined classes and come up with its own semantic labels for the objects.
Additionally, the researchers explore using the vision and text encoders in CLIP to retrieve relevant textual information that can further inform the clustering and class assignment process. This helps the model make more meaningful connections between the images and the appropriate class names.
The paper evaluates this approach in both unsupervised and partially supervised settings, across different levels of granularity for the class name vocabulary. Remarkably, the method leads to around a 50% improvement over baseline methods on the ImageNet dataset in the unsupervised setting.
Technical Explanation
The key technical elements of the paper are:
-
Non-parametric clustering: The researchers use non-parametric methods to establish meaningful relationships between images, allowing the model to automatically narrow down the pool of candidate class names. This involves iteratively clustering the data and employing a voting mechanism to determine the most suitable class names.
-
Textual feature incorporation: The paper explores the potential of incorporating additional textual features to enhance the clustering performance. Specifically, the researchers use the CLIP vision and text encoders to retrieve relevant texts from an external database, which can provide supplementary semantic information to inform the clustering process.
-
Unsupervised and partially supervised settings: The proposed approach is evaluated in both unsupervised and partially supervised settings, as well as with a coarse-grained and fine-grained search space as the unconstrained dictionary of class names.
The core insight is that by leveraging the rich semantic understanding of vision-language models and combining it with non-parametric clustering techniques, the model can assign meaningful class names to images, even when given a large, unconstrained vocabulary of potential labels. The additional textual features help the model make more informed decisions about the appropriate class names.
Critical Analysis
The paper presents a promising approach to addressing the limitations of existing image recognition models, but there are a few potential caveats and areas for further research:
-
Scalability and computational complexity: While the non-parametric clustering approach is powerful, it may become computationally expensive as the size of the dataset and vocabulary of class names grows. The researchers should investigate ways to improve the scalability of the method.
-
Robustness and generalization: The paper evaluates the approach on the ImageNet dataset, but it would be valuable to see how it performs on a wider range of datasets and real-world applications. Assessing the robustness and generalization capabilities of the method is an important area for further research.
-
Interpretability and explainability: While the proposed approach can assign meaningful class names to objects, the process by which the model arrives at these decisions is not fully transparent. Exploring ways to make the model's reasoning more interpretable and explainable could be a valuable direction for future work.
-
Comparison to human-level performance: The paper does not provide a direct comparison between the model's performance and human-level object recognition and classification abilities. Understanding how the approach compares to human cognition could provide valuable insights.
Overall, the paper presents an innovative and promising approach to open-vocabulary image classification that leverages the strengths of vision-language models and non-parametric clustering. Further research to address the identified limitations and explore the broader implications of this work could lead to significant advancements in the field of machine perception and visual understanding.
Conclusion
This paper proposes a novel approach to open-vocabulary image classification that tasks a vision-language model with assigning class names to images given a large, unconstrained vocabulary of potential labels. By leveraging non-parametric clustering techniques and incorporating additional textual features, the model can automatically determine the most suitable class names for each image, going beyond the predefined set of options in traditional image recognition models.
The key contribution of this work is the ability to imbue vision-language models with a deeper semantic understanding of the objects they observe, rather than just mapping them to predefined class indices. This represents an important step towards more human-like visual understanding and could have significant implications for a wide range of applications, from object detection to zero-shot learning and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
What's in a Name? Beyond Class Indices for Image Recognition
Kai Han, Xiaohu Huang, Yandong Li, Sagar Vaze, Jie Li, Xuhui Jia
Existing machine learning models demonstrate excellent performance in image object recognition after training on a large-scale dataset under full supervision. However, these models only learn to map an image to a predefined class index, without revealing the actual semantic meaning of the object in the image. In contrast, vision-language models like CLIP are able to assign semantic class names to unseen objects in a 'zero-shot' manner, though they are once again provided a pre-defined set of candidate names at test-time. In this paper, we reconsider the recognition problem and task a vision-language model with assigning class names to images given only a large (essentially unconstrained) vocabulary of categories as prior information. We leverage non-parametric methods to establish meaningful relationships between images, allowing the model to automatically narrow down the pool of candidate names. Our proposed approach entails iteratively clustering the data and employing a voting mechanism to determine the most suitable class names. Additionally, we investigate the potential of incorporating additional textual features to enhance clustering performance. To achieve this, we employ the CLIP vision and text encoders to retrieve relevant texts from an external database, which can provide supplementary semantic information to inform the clustering process. Furthermore, we tackle this problem both in unsupervised and partially supervised settings, as well as with a coarse-grained and fine-grained search space as the unconstrained dictionary. Remarkably, our method leads to a roughly 50% improvement over the baseline on ImageNet in the unsupervised setting.
Read more7/30/2024
0
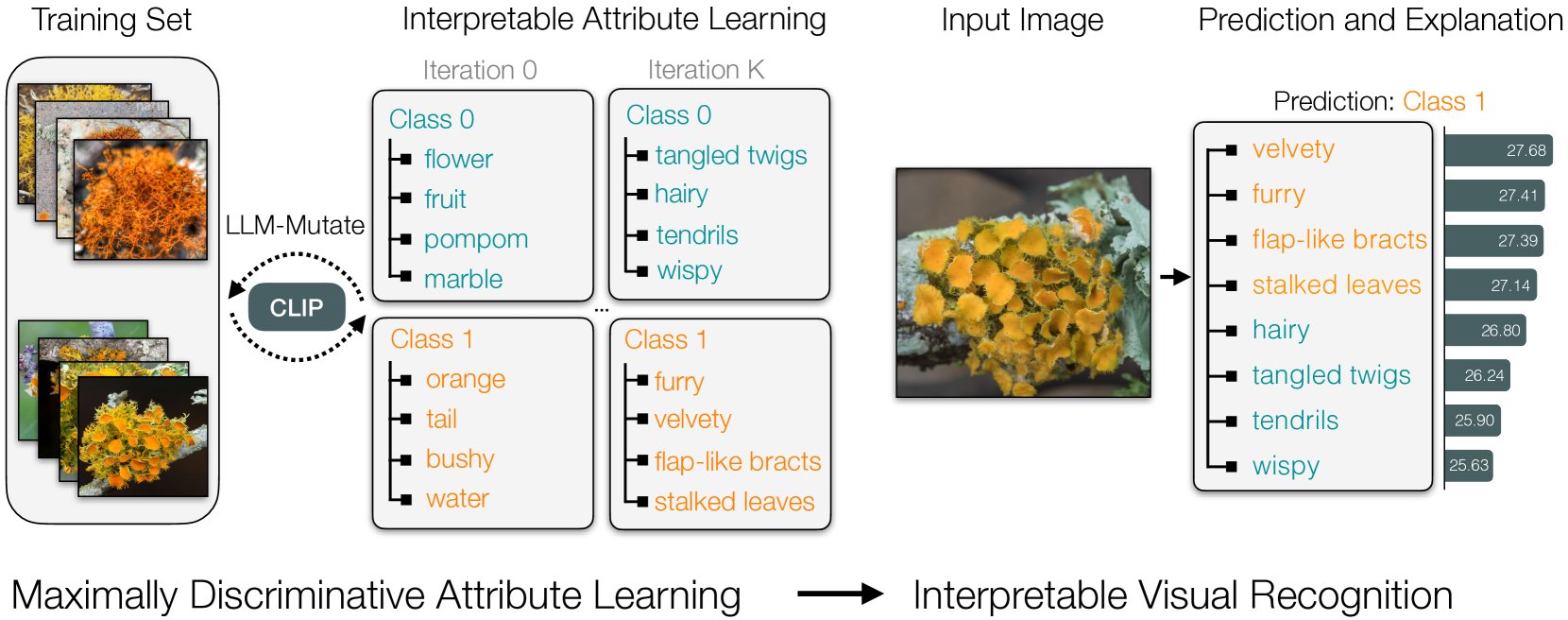
Evolving Interpretable Visual Classifiers with Large Language Models
Mia Chiquier, Utkarsh Mall, Carl Vondrick
Multimodal pre-trained models, such as CLIP, are popular for zero-shot classification due to their open-vocabulary flexibility and high performance. However, vision-language models, which compute similarity scores between images and class labels, are largely black-box, with limited interpretability, risk for bias, and inability to discover new visual concepts not written down. Moreover, in practical settings, the vocabulary for class names and attributes of specialized concepts will not be known, preventing these methods from performing well on images uncommon in large-scale vision-language datasets. To address these limitations, we present a novel method that discovers interpretable yet discriminative sets of attributes for visual recognition. We introduce an evolutionary search algorithm that uses a large language model and its in-context learning abilities to iteratively mutate a concept bottleneck of attributes for classification. Our method produces state-of-the-art, interpretable fine-grained classifiers. We outperform the latest baselines by 18.4% on five fine-grained iNaturalist datasets and by 22.2% on two KikiBouba datasets, despite the baselines having access to privileged information about class names.
Read more4/16/2024

0
Unconstrained Open Vocabulary Image Classification: Zero-Shot Transfer from Text to Image via CLIP Inversion
Philipp Allgeuer, Kyra Ahrens, Stefan Wermter
We introduce NOVIC, an innovative uNconstrained Open Vocabulary Image Classifier that uses an autoregressive transformer to generatively output classification labels as language. Leveraging the extensive knowledge of CLIP models, NOVIC harnesses the embedding space to enable zero-shot transfer from pure text to images. Traditional CLIP models, despite their ability for open vocabulary classification, require an exhaustive prompt of potential class labels, restricting their application to images of known content or context. To address this, we propose an object decoder model that is trained on a large-scale 92M-target dataset of templated object noun sets and LLM-generated captions to always output the object noun in question. This effectively inverts the CLIP text encoder and allows textual object labels to be generated directly from image-derived embedding vectors, without requiring any a priori knowledge of the potential content of an image. The trained decoders are tested on a mix of manually and web-curated datasets, as well as standard image classification benchmarks, and achieve fine-grained prompt-free prediction scores of up to 87.5%, a strong result considering the model must work for any conceivable image and without any contextual clues.
Read more7/19/2024
🔎
0
Incremental Object Detection with CLIP
Ziyue Huang, Yupeng He, Qingjie Liu, Yunhong Wang
In contrast to the incremental classification task, the incremental detection task is characterized by the presence of data ambiguity, as an image may have differently labeled bounding boxes across multiple continuous learning stages. This phenomenon often impairs the model's ability to effectively learn new classes. However, existing research has paid less attention to the forward compatibility of the model, which limits its suitability for incremental learning. To overcome this obstacle, we propose leveraging a visual-language model such as CLIP to generate text feature embeddings for different class sets, which enhances the feature space globally. We then employ super-classes to replace the unavailable novel classes in the early learning stage to simulate the incremental scenario. Finally, we utilize the CLIP image encoder to accurately identify potential objects. We incorporate the finely recognized detection boxes as pseudo-annotations into the training process, thereby further improving the detection performance. We evaluate our approach on various incremental learning settings using the PASCAL VOC 2007 dataset, and our approach outperforms state-of-the-art methods, particularly for recognizing the new classes.
Read more7/10/2024