Scaling White-Box Transformers for Vision

0

Sign in to get full access
Overview
- Introduces a new approach for scaling white-box transformers for vision tasks
- Focuses on improving the efficiency and performance of transformer models for computer vision applications
- Explores architectural choices and training strategies to enable the scaling of transformer models to larger sizes
Plain English Explanation
This paper presents a new method for scaling up white-box transformer models to handle vision tasks more effectively. White-box transformers are a type of neural network architecture that has shown promise in various computer vision applications, but they can be computationally expensive and difficult to scale to larger sizes.
The researchers in this study explore different ways to make these transformer models more efficient and powerful, allowing them to be used for more complex vision tasks. They experiment with changes to the model architecture and the training process, aiming to find the best combination of elements that can enable transformers to work well at larger scales.
By scaling white-box transformers for vision, the researchers hope to unlock the full potential of this type of model and make it more practical for real-world computer vision problems, such as image recognition or masked completion. This could lead to more accurate and efficient vision models that can be deployed in a wider range of applications.
Technical Explanation
The paper explores several key techniques for scaling white-box transformers for vision tasks:
-
Architectural Choices: The researchers experiment with different design choices for the transformer model, such as the number of layers, the size of the attention heads, and the overall model size. They investigate how these architectural decisions impact the model's performance and efficiency.
-
Training Strategies: The team also explores various training strategies, including the use of horizontally scalable vision transformers and comparative analysis of transformer efficiency. These approaches aim to improve the model's ability to generalize and achieve higher accuracy on vision tasks.
-
Scaling Methodology: The researchers develop a systematic methodology for scaling up the white-box transformer models, evaluating the trade-offs between model size, computational cost, and performance. This allows them to identify the optimal configurations for different use cases and resource constraints.
Through their experiments and analysis, the authors provide valuable insights into the key factors that influence the scalability and performance of white-box transformers in computer vision applications. These findings can help guide the development of more efficient and powerful vision models based on transformer architectures.
Critical Analysis
The paper acknowledges some limitations and areas for further research:
- The experiments are primarily focused on image classification tasks, and the researchers suggest exploring the scaling of white-box transformers for other vision tasks, such as object detection or semantic segmentation.
- The training strategies and architectural choices explored in this study may not be universally optimal, and further research is needed to identify the most effective approaches for different types of vision problems and datasets.
- The computational and memory requirements of the scaled-up white-box transformers may still be a concern for certain real-world applications, especially on resource-constrained devices. Continued efforts to improve the efficiency of these models are necessary.
Overall, the paper presents a solid and well-designed study that advances the understanding of scaling white-box transformers for vision tasks. However, as with any research, there are opportunities for further exploration and refinement to address the remaining challenges and expand the practical applications of this technology.
Conclusion
The research presented in this paper demonstrates a promising approach for scaling up white-box transformers to handle more complex and demanding computer vision tasks. By exploring architectural choices, training strategies, and a systematic scaling methodology, the authors have made significant progress in unlocking the full potential of transformer models for vision applications.
The findings from this study can inform the development of more efficient and powerful vision models, which could have far-reaching implications for a wide range of real-world applications, from image recognition to autonomous driving and beyond. As the field of computer vision continues to evolve, this work on scaling white-box transformers represents an important step forward in advancing the state of the art.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Scaling White-Box Transformers for Vision
Jinrui Yang, Xianhang Li, Druv Pai, Yuyin Zhou, Yi Ma, Yaodong Yu, Cihang Xie
CRATE, a white-box transformer architecture designed to learn compressed and sparse representations, offers an intriguing alternative to standard vision transformers (ViTs) due to its inherent mathematical interpretability. Despite extensive investigations into the scaling behaviors of language and vision transformers, the scalability of CRATE remains an open question which this paper aims to address. Specifically, we propose CRATE-$alpha$, featuring strategic yet minimal modifications to the sparse coding block in the CRATE architecture design, and a light training recipe designed to improve the scalability of CRATE. Through extensive experiments, we demonstrate that CRATE-$alpha$ can effectively scale with larger model sizes and datasets. For example, our CRATE-$alpha$-B substantially outperforms the prior best CRATE-B model accuracy on ImageNet classification by 3.7%, achieving an accuracy of 83.2%. Meanwhile, when scaling further, our CRATE-$alpha$-L obtains an ImageNet classification accuracy of 85.1%. More notably, these model performance improvements are achieved while preserving, and potentially even enhancing the interpretability of learned CRATE models, as we demonstrate through showing that the learned token representations of increasingly larger trained CRATE-$alpha$ models yield increasingly higher-quality unsupervised object segmentation of images. The project page is https://rayjryang.github.io/CRATE-alpha/.
Read more6/4/2024
🗣️
1
White-Box Transformers via Sparse Rate Reduction: Compression Is All There Is?
Yaodong Yu, Sam Buchanan, Druv Pai, Tianzhe Chu, Ziyang Wu, Shengbang Tong, Hao Bai, Yuexiang Zhai, Benjamin D. Haeffele, Yi Ma
In this paper, we contend that a natural objective of representation learning is to compress and transform the distribution of the data, say sets of tokens, towards a low-dimensional Gaussian mixture supported on incoherent subspaces. The goodness of such a representation can be evaluated by a principled measure, called sparse rate reduction, that simultaneously maximizes the intrinsic information gain and extrinsic sparsity of the learned representation. From this perspective, popular deep network architectures, including transformers, can be viewed as realizing iterative schemes to optimize this measure. Particularly, we derive a transformer block from alternating optimization on parts of this objective: the multi-head self-attention operator compresses the representation by implementing an approximate gradient descent step on the coding rate of the features, and the subsequent multi-layer perceptron sparsifies the features. This leads to a family of white-box transformer-like deep network architectures, named CRATE, which are mathematically fully interpretable. We show, by way of a novel connection between denoising and compression, that the inverse to the aforementioned compressive encoding can be realized by the same class of CRATE architectures. Thus, the so-derived white-box architectures are universal to both encoders and decoders. Experiments show that these networks, despite their simplicity, indeed learn to compress and sparsify representations of large-scale real-world image and text datasets, and achieve performance very close to highly engineered transformer-based models: ViT, MAE, DINO, BERT, and GPT2. We believe the proposed computational framework demonstrates great potential in bridging the gap between theory and practice of deep learning, from a unified perspective of data compression. Code is available at: https://ma-lab-berkeley.github.io/CRATE .
Read more9/9/2024
🚀
0
Masked Completion via Structured Diffusion with White-Box Transformers
Druv Pai, Ziyang Wu, Sam Buchanan, Yaodong Yu, Yi Ma
Modern learning frameworks often train deep neural networks with massive amounts of unlabeled data to learn representations by solving simple pretext tasks, then use the representations as foundations for downstream tasks. These networks are empirically designed; as such, they are usually not interpretable, their representations are not structured, and their designs are potentially redundant. White-box deep networks, in which each layer explicitly identifies and transforms structures in the data, present a promising alternative. However, existing white-box architectures have only been shown to work at scale in supervised settings with labeled data, such as classification. In this work, we provide the first instantiation of the white-box design paradigm that can be applied to large-scale unsupervised representation learning. We do this by exploiting a fundamental connection between diffusion, compression, and (masked) completion, deriving a deep transformer-like masked autoencoder architecture, called CRATE-MAE, in which the role of each layer is mathematically fully interpretable: they transform the data distribution to and from a structured representation. Extensive empirical evaluations confirm our analytical insights. CRATE-MAE demonstrates highly promising performance on large-scale imagery datasets while using only ~30% of the parameters compared to the standard masked autoencoder with the same model configuration. The representations learned by CRATE-MAE have explicit structure and also contain semantic meaning. Code is available at https://github.com/Ma-Lab-Berkeley/CRATE .
Read more4/4/2024
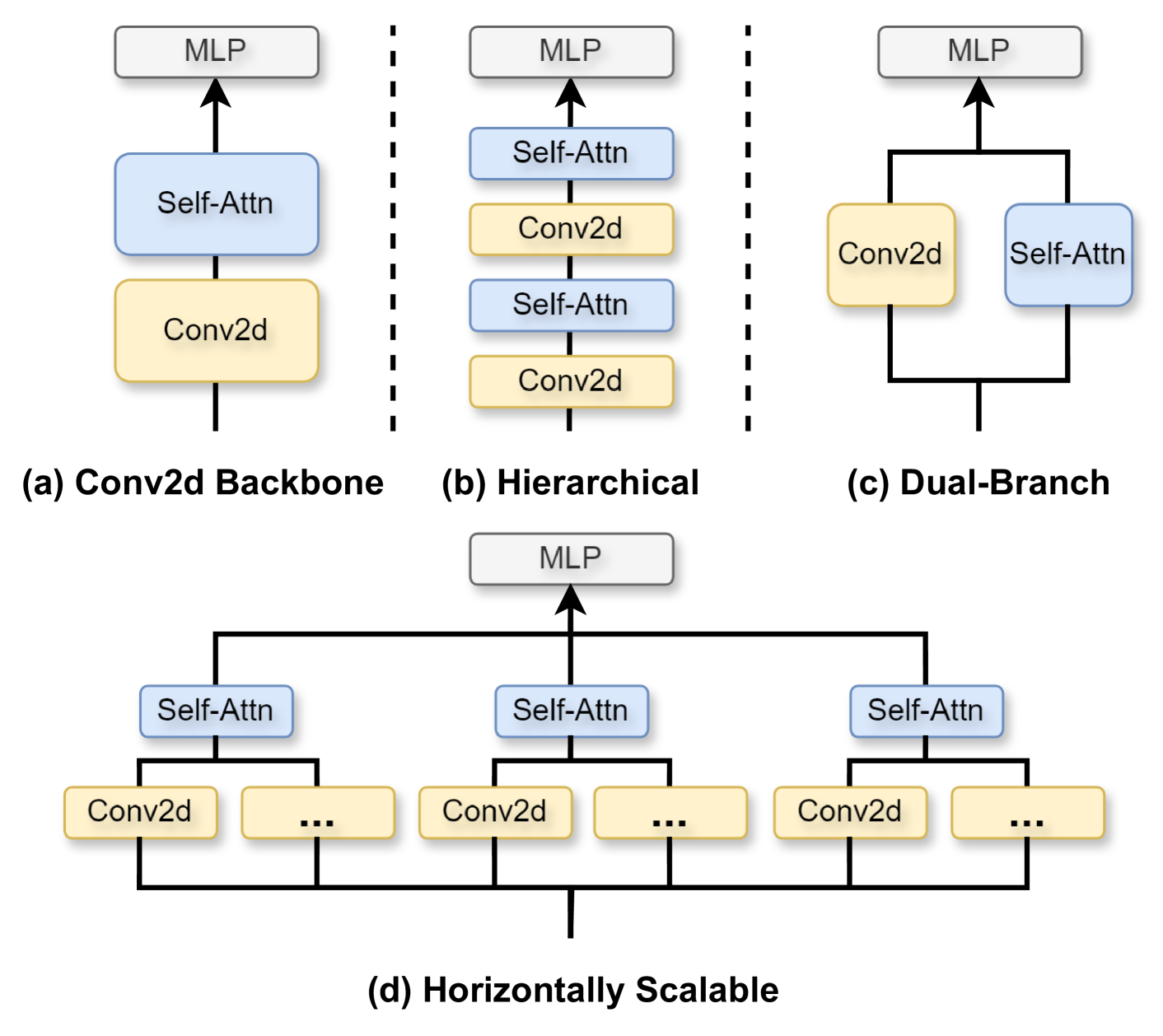
0
HSViT: Horizontally Scalable Vision Transformer
Chenhao Xu, Chang-Tsun Li, Chee Peng Lim, Douglas Creighton
Due to its deficiency in prior knowledge (inductive bias), Vision Transformer (ViT) requires pre-training on large-scale datasets to perform well. Moreover, the growing layers and parameters in ViT models impede their applicability to devices with limited computing resources. To mitigate the aforementioned challenges, this paper introduces a novel horizontally scalable vision transformer (HSViT) scheme. Specifically, a novel image-level feature embedding is introduced to ViT, where the preserved inductive bias allows the model to eliminate the need for pre-training while outperforming on small datasets. Besides, a novel horizontally scalable architecture is designed, facilitating collaborative model training and inference across multiple computing devices. The experimental results depict that, without pre-training, HSViT achieves up to 10% higher top-1 accuracy than state-of-the-art schemes on small datasets, while providing existing CNN backbones up to 3.1% improvement in top-1 accuracy on ImageNet. The code is available at https://github.com/xuchenhao001/HSViT.
Read more7/17/2024