HAMMR: HierArchical MultiModal React agents for generic VQA
2404.05465
0
0
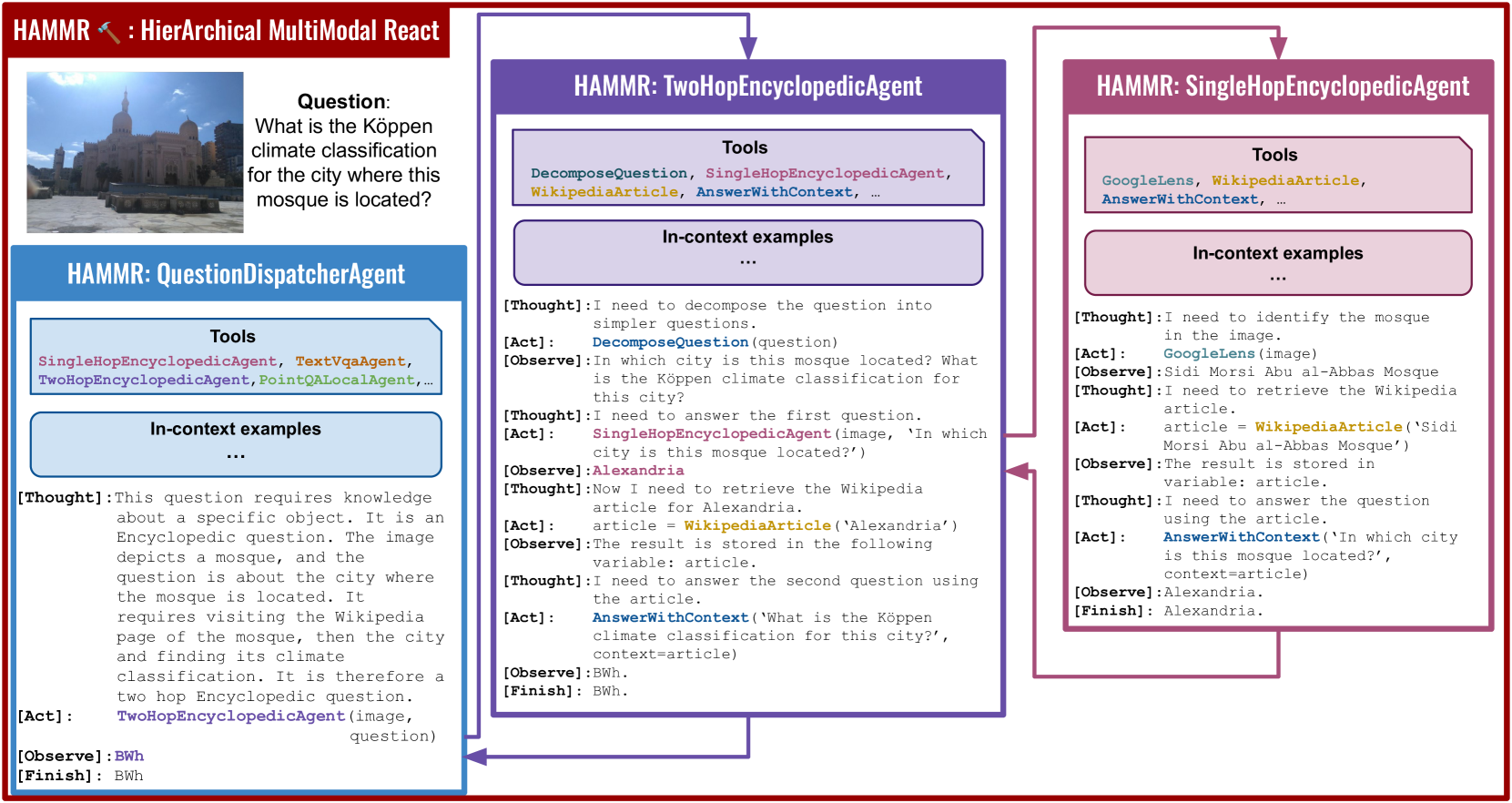
Abstract
Combining Large Language Models (LLMs) with external specialized tools (LLMs+tools) is a recent paradigm to solve multimodal tasks such as Visual Question Answering (VQA). While this approach was demonstrated to work well when optimized and evaluated for each individual benchmark, in practice it is crucial for the next generation of real-world AI systems to handle a broad range of multimodal problems. Therefore we pose the VQA problem from a unified perspective and evaluate a single system on a varied suite of VQA tasks including counting, spatial reasoning, OCR-based reasoning, visual pointing, external knowledge, and more. In this setting, we demonstrate that naively applying the LLM+tools approach using the combined set of all tools leads to poor results. This motivates us to introduce HAMMR: HierArchical MultiModal React. We start from a multimodal ReAct-based system and make it hierarchical by enabling our HAMMR agents to call upon other specialized agents. This enhances the compositionality of the LLM+tools approach, which we show to be critical for obtaining high accuracy on generic VQA. Concretely, on our generic VQA suite, HAMMR outperforms the naive LLM+tools approach by 19.5%. Additionally, HAMMR achieves state-of-the-art results on this task, outperforming the generic standalone PaLI-X VQA model by 5.0%.
Create account to get full access
Overview
- This paper introduces HAMMR, a hierarchical multimodal React-based framework for Visual Question Answering (VQA) tasks.
- HAMMR leverages large language models and multimodal neural networks to tackle generic VQA problems.
- The key components of HAMMR include a hierarchical reasoning module, a multimodal fusion module, and a modular architecture that allows for customization and extensibility.
Plain English Explanation
HAMMR is a new system that aims to help computers answer questions about images. It uses large language models and other AI technologies to understand the content of an image and then provide relevant answers to questions about it.
The key innovation in HAMMR is its hierarchical structure, which allows it to break down the question-answering process into smaller, more manageable steps. This helps the system better understand the nuances of the question and formulate a more accurate response.
HAMMR also has a modular design, which means its different components can be customized and expanded as needed. This flexibility allows the system to be tailored to different types of VQA tasks and potentially be applied to other multimodal AI applications as well.
Overall, HAMMR represents an interesting step forward in the field of multimodal large language models and their ability to interact with the world in more natural and intuitive ways.
Technical Explanation
The core of HAMMR is its hierarchical reasoning module, which breaks down the VQA task into a series of subtasks. This module first extracts relevant visual and textual features from the input, then uses a series of neural network layers to reason about the question and generate an answer.
The multimodal fusion module in HAMMR combines the visual and textual features in a way that enhances the system's understanding of the question and the image. This helps to overcome potential biases that can arise when using unimodal models.
HAMMR's modular architecture allows for the easy incorporation of different large language models and vision models, enabling the system to be customized for different VQA datasets and use cases. The authors demonstrate the effectiveness of this approach through experiments on several benchmark VQA datasets.
Critical Analysis
While HAMMR shows promising results, the paper does not provide a detailed analysis of the system's limitations or potential biases. It would be helpful to understand how the hierarchical reasoning and multimodal fusion modules may fail in certain cases, and what strategies could be employed to mitigate these issues.
Additionally, the authors do not discuss how HAMMR could be extended to other multimodal applications beyond VQA, such as robotic perception and planning. Exploring these avenues could further showcase the versatility and potential of the HAMMR framework.
Conclusion
Overall, HAMMR represents an interesting and promising approach to large language model-based AI agents for visual question answering. Its hierarchical reasoning and modular design offer advantages in terms of interpretability and flexibility, which could lead to more robust and adaptable multimodal AI systems in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Wiki-LLaVA: Hierarchical Retrieval-Augmented Generation for Multimodal LLMs
Davide Caffagni, Federico Cocchi, Nicholas Moratelli, Sara Sarto, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara
0
0
Multimodal LLMs are the natural evolution of LLMs, and enlarge their capabilities so as to work beyond the pure textual modality. As research is being carried out to design novel architectures and vision-and-language adapters, in this paper we concentrate on endowing such models with the capability of answering questions that require external knowledge. Our approach, termed Wiki-LLaVA, aims at integrating an external knowledge source of multimodal documents, which is accessed through a hierarchical retrieval pipeline. Relevant passages, using this approach, are retrieved from the external knowledge source and employed as additional context for the LLM, augmenting the effectiveness and precision of generated dialogues. We conduct extensive experiments on datasets tailored for visual question answering with external data and demonstrate the appropriateness of our approach.
5/24/2024

MM-PhyRLHF: Reinforcement Learning Framework for Multimodal Physics Question-Answering
Avinash Anand, Janak Kapuriya, Chhavi Kirtani, Apoorv Singh, Jay Saraf, Naman Lal, Jatin Kumar, Adarsh Raj Shivam, Astha Verma, Rajiv Ratn Shah, Roger Zimmermann
0
0
Recent advancements in LLMs have shown their significant potential in tasks like text summarization and generation. Yet, they often encounter difficulty while solving complex physics problems that require arithmetic calculation and a good understanding of concepts. Moreover, many physics problems include images that contain important details required to understand the problem's context. We propose an LMM-based chatbot to answer multimodal physics MCQs. For domain adaptation, we utilize the MM-PhyQA dataset comprising Indian high school-level multimodal physics problems. To improve the LMM's performance, we experiment with two techniques, RLHF (Reinforcement Learning from Human Feedback) and Image Captioning. In image captioning, we add a detailed explanation of the diagram in each image, minimizing hallucinations and image processing errors. We further explore the integration of Reinforcement Learning from Human Feedback (RLHF) methodology inspired by the ranking approach in RLHF to enhance the human-like problem-solving abilities of the models. The RLHF approach incorporates human feedback into the learning process of LLMs, improving the model's problem-solving skills, truthfulness, and reasoning capabilities, minimizing the hallucinations in the answers, and improving the quality instead of using vanilla-supervised fine-tuned models. We employ the LLaVA open-source model to answer multimodal physics MCQs and compare the performance with and without using RLHF.
4/22/2024
LaMI: Large Language Models for Multi-Modal Human-Robot Interaction
Chao Wang, Stephan Hasler, Daniel Tanneberg, Felix Ocker, Frank Joublin, Antonello Ceravola, Joerg Deigmoeller, Michael Gienger
0
0
This paper presents an innovative large language model (LLM)-based robotic system for enhancing multi-modal human-robot interaction (HRI). Traditional HRI systems relied on complex designs for intent estimation, reasoning, and behavior generation, which were resource-intensive. In contrast, our system empowers researchers and practitioners to regulate robot behavior through three key aspects: providing high-level linguistic guidance, creating atomic actions and expressions the robot can use, and offering a set of examples. Implemented on a physical robot, it demonstrates proficiency in adapting to multi-modal inputs and determining the appropriate manner of action to assist humans with its arms, following researchers' defined guidelines. Simultaneously, it coordinates the robot's lid, neck, and ear movements with speech output to produce dynamic, multi-modal expressions. This showcases the system's potential to revolutionize HRI by shifting from conventional, manual state-and-flow design methods to an intuitive, guidance-based, and example-driven approach. Supplementary material can be found at https://hri-eu.github.io/Lami/
4/12/2024

II-MMR: Identifying and Improving Multi-modal Multi-hop Reasoning in Visual Question Answering
Jihyung Kil, Farideh Tavazoee, Dongyeop Kang, Joo-Kyung Kim
0
0
Visual Question Answering (VQA) often involves diverse reasoning scenarios across Vision and Language (V&L). Most prior VQA studies, however, have merely focused on assessing the model's overall accuracy without evaluating it on different reasoning cases. Furthermore, some recent works observe that conventional Chain-of-Thought (CoT) prompting fails to generate effective reasoning for VQA, especially for complex scenarios requiring multi-hop reasoning. In this paper, we propose II-MMR, a novel idea to identify and improve multi-modal multi-hop reasoning in VQA. In specific, II-MMR takes a VQA question with an image and finds a reasoning path to reach its answer using two novel language promptings: (i) answer prediction-guided CoT prompt, or (ii) knowledge triplet-guided prompt. II-MMR then analyzes this path to identify different reasoning cases in current VQA benchmarks by estimating how many hops and what types (i.e., visual or beyond-visual) of reasoning are required to answer the question. On popular benchmarks including GQA and A-OKVQA, II-MMR observes that most of their VQA questions are easy to answer, simply demanding single-hop reasoning, whereas only a few questions require multi-hop reasoning. Moreover, while the recent V&L model struggles with such complex multi-hop reasoning questions even using the traditional CoT method, II-MMR shows its effectiveness across all reasoning cases in both zero-shot and fine-tuning settings.
6/4/2024