Will the Real Linda Please Stand up...to Large Language Models? Examining the Representativeness Heuristic in LLMs
2404.01461
0
0

Abstract
Although large language models (LLMs) have demonstrated remarkable proficiency in understanding text and generating human-like text, they may exhibit biases acquired from training data in doing so. Specifically, LLMs may be susceptible to a common cognitive trap in human decision-making called the representativeness heuristic. This is a concept in psychology that refers to judging the likelihood of an event based on how closely it resembles a well-known prototype or typical example versus considering broader facts or statistical evidence. This work investigates the impact of the representativeness heuristic on LLM reasoning. We created ReHeAT (Representativeness Heuristic AI Testing), a dataset containing a series of problems spanning six common types of representativeness heuristics. Experiments reveal that four LLMs applied to REHEAT all exhibited representativeness heuristic biases. We further identify that the model's reasoning steps are often incorrectly based on a stereotype rather than the problem's description. Interestingly, the performance improves when adding a hint in the prompt to remind the model of using its knowledge. This suggests the uniqueness of the representativeness heuristic compared to traditional biases. It can occur even when LLMs possess the correct knowledge while failing in a cognitive trap. This highlights the importance of future research focusing on the representativeness heuristic in model reasoning and decision-making and on developing solutions to address it.
Create account to get full access
Overview
- This paper examines how large language models (LLMs) can be influenced by the representativeness heuristic, a cognitive bias where people judge the probability of an event based on how representative it is of a broader category.
- The researchers use the famous "Linda problem" as a case study to explore this phenomenon in LLMs.
- They find that LLMs exhibit similar biases to humans when presented with the Linda problem, even though the models have no direct experience of the world.
- This suggests that the representativeness heuristic may be an inherent feature of how LLMs process and reason about information.
Plain English Explanation
The paper looks at a well-known cognitive bias called the representativeness heuristic and how it affects large language models (LLMs) - the powerful AI systems that power many of today's conversational assistants and text generation tools.
The representativeness heuristic is a mental shortcut where people judge the probability of something based on how "representative" it is of a broader category, rather than objectively analyzing the probabilities involved. A classic example is the "Linda problem" - if you're told that "Linda is 31 years old, single, outspoken, and very bright. She majored in philosophy. As a student, she was deeply concerned with issues of discrimination and social justice, and participated in anti-nuclear demonstrations," people tend to judge it as more likely that Linda is a bank teller and a feminist than just a bank teller, even though the latter is the statistically more probable outcome.
The researchers found that large language models exhibit a similar bias when presented with the Linda problem. Even though the models have no direct experience of the world, they still seem to be influenced by this representativeness heuristic and make the same "mistakes" in probability judgments that humans do.
This suggests that the representativeness heuristic may be a fundamental part of how these powerful language models process and reason about information, rather than just a byproduct of human psychology. It raises important questions about the inner workings of LLMs and how we can ensure they make decisions in a more objective, unbiased way.
Technical Explanation
The key focus of this paper is examining the influence of the representativeness heuristic on large language models (LLMs). The representativeness heuristic is a cognitive bias where people judge the probability of an event based on how representative it is of a broader category, rather than objectively analyzing the actual probabilities involved.
The researchers used the classic "Linda problem" as a case study to explore this phenomenon in LLMs. In the Linda problem, participants are given a description of a woman (Linda) that aligns with stereotypes of a feminist, and then asked to judge whether it is more likely that Linda is a bank teller or a bank teller who is also a feminist. Despite the latter being statistically more probable, people tend to judge the feminist option as more likely due to the representativeness heuristic.
The researchers tested several state-of-the-art LLMs, including GPT-3, on variations of the Linda problem. They found that the LLMs exhibited a similar bias to humans, rating the "bank teller and feminist" option as more probable than the "bank teller" option, even though logically the latter should be more likely.
This suggests that the representativeness heuristic may be an inherent feature of how LLMs process and reason about information, rather than just a byproduct of human psychology. The models have no direct experience of the world, yet they seem to be influenced by the same cognitive biases that affect human decision-making.
The findings raise important questions about the inner workings of LLMs and the need to better understand how these powerful systems arrive at their conclusions. Addressing biases like the representativeness heuristic will be crucial as LLMs become more widely deployed in high-stakes decision-making contexts.
Critical Analysis
The paper provides a thorough and well-designed exploration of the representativeness heuristic in large language models. The researchers' use of the classic Linda problem as a case study is a smart choice, as it allows them to directly compare the biases exhibited by LLMs to the well-documented biases of human decision-makers.
One potential limitation of the study is the reliance on a single task (the Linda problem) to assess the representativeness heuristic in LLMs. While this provides a useful starting point, it would be valuable to see if the same biases manifest in a wider range of probability judgments and decision-making scenarios.
Additionally, the paper does not delve deeply into the potential mechanisms underlying the representativeness heuristic in LLMs. While the authors speculate that it may be an inherent feature of how these models process information, further research is needed to fully understand the cognitive processes at play.
It would also be interesting to see if there are any techniques or architectural modifications that could help mitigate the influence of the representativeness heuristic in LLMs. The authors mention the importance of addressing such biases as these models become more widely deployed, and exploring potential solutions would be a valuable next step.
Overall, this is a well-executed study that sheds important light on the limitations and biases of large language models. The findings underscore the need for continued scrutiny and improvement of these powerful AI systems as they become increasingly integrated into our daily lives.
Conclusion
This paper presents a compelling investigation into how the representativeness heuristic, a well-known cognitive bias, can influence the decision-making of large language models (LLMs). By using the classic Linda problem as a case study, the researchers demonstrate that even LLMs with no direct experience of the world can exhibit similar biases to human decision-makers when it comes to probability judgments.
The discovery that the representativeness heuristic may be an inherent feature of how LLMs process information, rather than just a byproduct of human psychology, raises important questions about the inner workings of these powerful AI systems. As LLMs become more widely deployed in high-stakes contexts, addressing such biases will be crucial to ensuring they make objective, reliable decisions.
This paper contributes valuable insights to the ongoing efforts to understand and improve large language models. By shedding light on the deep-rooted cognitive biases that can influence even the most advanced AI systems, it underscores the importance of continued research and vigilance in this rapidly evolving field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
Bayesian Statistical Modeling with Predictors from LLMs
Michael Franke, Polina Tsvilodub, Fausto Carcassi
0
0
State of the art large language models (LLMs) have shown impressive performance on a variety of benchmark tasks and are increasingly used as components in larger applications, where LLM-based predictions serve as proxies for human judgements or decision. This raises questions about the human-likeness of LLM-derived information, alignment with human intuition, and whether LLMs could possibly be considered (parts of) explanatory models of (aspects of) human cognition or language use. To shed more light on these issues, we here investigate the human-likeness of LLMs' predictions for multiple-choice decision tasks from the perspective of Bayesian statistical modeling. Using human data from a forced-choice experiment on pragmatic language use, we find that LLMs do not capture the variance in the human data at the item-level. We suggest different ways of deriving full distributional predictions from LLMs for aggregate, condition-level data, and find that some, but not all ways of obtaining condition-level predictions yield adequate fits to human data. These results suggests that assessment of LLM performance depends strongly on seemingly subtle choices in methodology, and that LLMs are at best predictors of human behavior at the aggregate, condition-level, for which they are, however, not designed to, or usually used to, make predictions in the first place.
6/14/2024
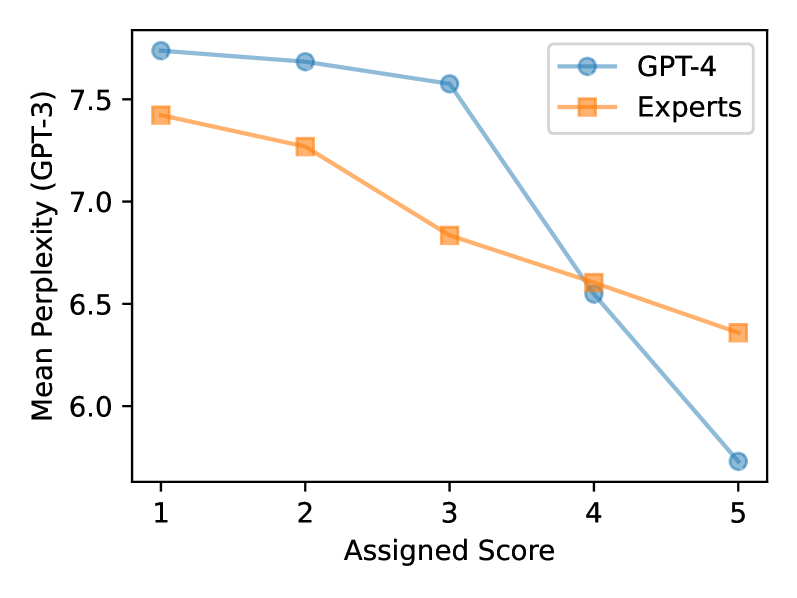
Large Language Models are Inconsistent and Biased Evaluators
Rickard Stureborg, Dimitris Alikaniotis, Yoshi Suhara
0
0
The zero-shot capability of Large Language Models (LLMs) has enabled highly flexible, reference-free metrics for various tasks, making LLM evaluators common tools in NLP. However, the robustness of these LLM evaluators remains relatively understudied; existing work mainly pursued optimal performance in terms of correlating LLM scores with human expert scores. In this paper, we conduct a series of analyses using the SummEval dataset and confirm that LLMs are biased evaluators as they: (1) exhibit familiarity bias-a preference for text with lower perplexity, (2) show skewed and biased distributions of ratings, and (3) experience anchoring effects for multi-attribute judgments. We also found that LLMs are inconsistent evaluators, showing low inter-sample agreement and sensitivity to prompt differences that are insignificant to human understanding of text quality. Furthermore, we share recipes for configuring LLM evaluators to mitigate these limitations. Experimental results on the RoSE dataset demonstrate improvements over the state-of-the-art LLM evaluators.
5/6/2024
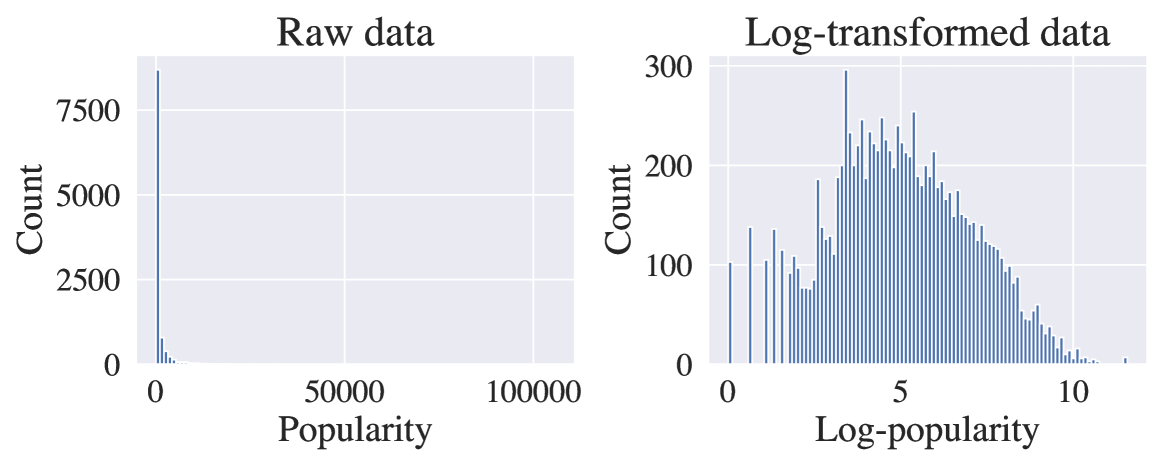
Large Language Models as Recommender Systems: A Study of Popularity Bias
Jan Malte Lichtenberg, Alexander Buchholz, Pola Schwobel
0
0
The issue of popularity bias -- where popular items are disproportionately recommended, overshadowing less popular but potentially relevant items -- remains a significant challenge in recommender systems. Recent advancements have seen the integration of general-purpose Large Language Models (LLMs) into the architecture of such systems. This integration raises concerns that it might exacerbate popularity bias, given that the LLM's training data is likely dominated by popular items. However, it simultaneously presents a novel opportunity to address the bias via prompt tuning. Our study explores this dichotomy, examining whether LLMs contribute to or can alleviate popularity bias in recommender systems. We introduce a principled way to measure popularity bias by discussing existing metrics and proposing a novel metric that fulfills a series of desiderata. Based on our new metric, we compare a simple LLM-based recommender to traditional recommender systems on a movie recommendation task. We find that the LLM recommender exhibits less popularity bias, even without any explicit mitigation.
6/4/2024
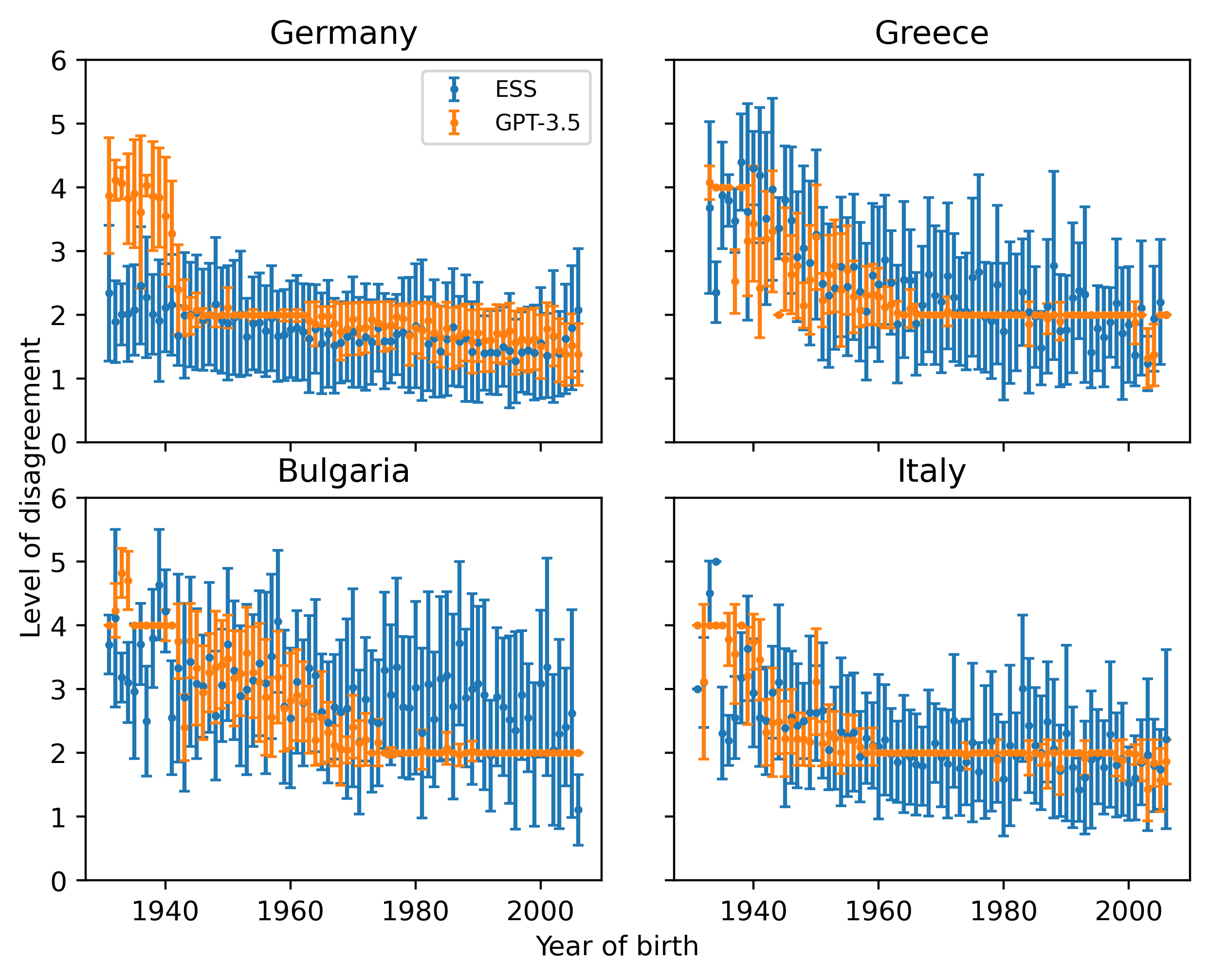
Are Large Language Models Chameleons?
Mingmeng Geng, Sihong He, Roberto Trotta
0
0
Do large language models (LLMs) have their own worldviews and personality tendencies? Simulations in which an LLM was asked to answer subjective questions were conducted more than 1 million times. Comparison of the responses from different LLMs with real data from the European Social Survey (ESS) suggests that the effect of prompts on bias and variability is fundamental, highlighting major cultural, age, and gender biases. Methods for measuring the difference between LLMs and survey data are discussed, such as calculating weighted means and a new proposed measure inspired by Jaccard similarity. We conclude that it is important to analyze the robustness and variability of prompts before using LLMs to model individual decisions or collective behavior, as their imitation abilities are approximate at best.
5/30/2024