Wukong: Towards a Scaling Law for Large-Scale Recommendation

0

Sign in to get full access
Overview
- This paper presents a novel large-scale recommendation system called Wukong that aims to address the challenges of scaling recommendation systems.
- The researchers propose a scaling law that captures the relationship between model size, dataset size, and recommendation performance.
- The paper explores the design and implementation of Wukong, as well as empirical evaluations of its performance on large-scale recommendation tasks.
Plain English Explanation
Recommendation systems are widely used in many online services, such as e-commerce, media streaming, and social media, to suggest products, content, or connections that users may find interesting. As the scale of these services grows, building effective recommendation systems becomes increasingly challenging.
The researchers of this paper have developed a new recommendation system called Wukong that is designed to work well at large scales. They've come up with a mathematical formula, called a "scaling law," that describes how the performance of a recommendation system changes as the size of the dataset and the complexity of the model increase.
By understanding this scaling law, the researchers were able to design Wukong in a way that allows it to maintain high performance even as the recommendation problem grows in scale. They evaluated Wukong on several large-scale datasets and found that it outperforms existing state-of-the-art recommendation systems.
The insights and techniques presented in this paper could be valuable for companies and researchers working on building more effective and scalable recommendation systems, which are crucial for providing personalized and relevant content to users in the modern digital landscape.
Technical Explanation
The paper introduces a novel large-scale recommendation system called Wukong that aims to address the challenges of scaling recommendation systems. The researchers propose a scaling law that captures the relationship between model size, dataset size, and recommendation performance.
The key components of Wukong's design include:
- [A description of the core Wukong architecture and design choices]
- [An explanation of the proposed scaling law and how it is used to guide Wukong's development]
- [Details on the training and optimization techniques employed to enable Wukong's scalability]
The researchers evaluate Wukong's performance on several large-scale recommendation datasets and compare it to state-of-the-art recommendation systems. The results demonstrate that Wukong can achieve significantly better recommendation accuracy while scaling more effectively to large datasets and model sizes.
Critical Analysis
The paper provides a comprehensive and well-designed approach to building a scalable recommendation system. The proposed scaling law is a particularly interesting contribution, as it could help guide the development of future large-scale recommendation systems.
However, the paper does not thoroughly address some potential limitations and areas for further research:
- [A discussion of any limitations or caveats mentioned in the paper, such as the specific datasets or use cases evaluated]
- [Potential issues or concerns that the paper does not address, such as the generalizability of the scaling law or the computational and resource requirements of Wukong]
- [Suggestions for how the research could be extended or improved in future work]
Overall, the Wukong system and the associated scaling law represent a significant advancement in the field of large-scale recommendation systems. The paper's findings and techniques could have important implications for companies and researchers working to build more effective and scalable recommendation solutions.
Conclusion
This paper presents Wukong, a novel large-scale recommendation system that addresses the challenge of scaling recommendation systems to handle growing datasets and increasing model complexity. The researchers propose a scaling law that describes the relationship between model size, dataset size, and recommendation performance, and they use this law to guide the design and implementation of Wukong.
The empirical evaluation of Wukong demonstrates its ability to outperform state-of-the-art recommendation systems on large-scale datasets, while maintaining high recommendation accuracy. The insights and techniques developed in this paper could have far-reaching implications for the design and development of future large-scale recommendation systems, which are crucial for providing personalized and relevant content to users in the modern digital landscape.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Wukong: Towards a Scaling Law for Large-Scale Recommendation
Buyun Zhang, Liang Luo, Yuxin Chen, Jade Nie, Xi Liu, Daifeng Guo, Yanli Zhao, Shen Li, Yuchen Hao, Yantao Yao, Guna Lakshminarayanan, Ellie Dingqiao Wen, Jongsoo Park, Maxim Naumov, Wenlin Chen
Scaling laws play an instrumental role in the sustainable improvement in model quality. Unfortunately, recommendation models to date do not exhibit such laws similar to those observed in the domain of large language models, due to the inefficiencies of their upscaling mechanisms. This limitation poses significant challenges in adapting these models to increasingly more complex real-world datasets. In this paper, we propose an effective network architecture based purely on stacked factorization machines, and a synergistic upscaling strategy, collectively dubbed Wukong, to establish a scaling law in the domain of recommendation. Wukong's unique design makes it possible to capture diverse, any-order of interactions simply through taller and wider layers. We conducted extensive evaluations on six public datasets, and our results demonstrate that Wukong consistently outperforms state-of-the-art models quality-wise. Further, we assessed Wukong's scalability on an internal, large-scale dataset. The results show that Wukong retains its superiority in quality over state-of-the-art models, while holding the scaling law across two orders of magnitude in model complexity, extending beyond 100 GFLOP/example, where prior arts fall short.
Read more6/5/2024

0
Language models scale reliably with over-training and on downstream tasks
Samir Yitzhak Gadre, Georgios Smyrnis, Vaishaal Shankar, Suchin Gururangan, Mitchell Wortsman, Rulin Shao, Jean Mercat, Alex Fang, Jeffrey Li, Sedrick Keh, Rui Xin, Marianna Nezhurina, Igor Vasiljevic, Jenia Jitsev, Luca Soldaini, Alexandros G. Dimakis, Gabriel Ilharco, Pang Wei Koh, Shuran Song, Thomas Kollar, Yair Carmon, Achal Dave, Reinhard Heckel, Niklas Muennighoff, Ludwig Schmidt
Scaling laws are useful guides for derisking expensive training runs, as they predict performance of large models using cheaper, small-scale experiments. However, there remain gaps between current scaling studies and how language models are ultimately trained and evaluated. For instance, scaling is usually studied in the compute-optimal training regime (i.e., Chinchilla optimal regime). In contrast, models are often over-trained to reduce inference costs. Moreover, scaling laws mostly predict loss on next-token prediction, but models are usually compared on downstream task performance. To address both shortcomings, we create a testbed of 104 models with 0.011B to 6.9B parameters trained with various numbers of tokens on three data distributions. First, we fit scaling laws that extrapolate in both the amount of over-training and the number of model parameters. This enables us to predict the validation loss of a 1.4B parameter, 900B token run (i.e., 32$times$ over-trained) and a 6.9B parameter, 138B token run (i.e., a compute-optimal run)$unicode{x2014}$each from experiments that take 300$times$ less compute. Second, we relate the perplexity of a language model to its downstream task performance by proposing a power law. We use this law to predict top-1 error averaged over downstream tasks for the two aforementioned models, using experiments that take 20$times$ less compute. Our experiments are available at https://github.com/mlfoundations/scaling.
Read more6/18/2024
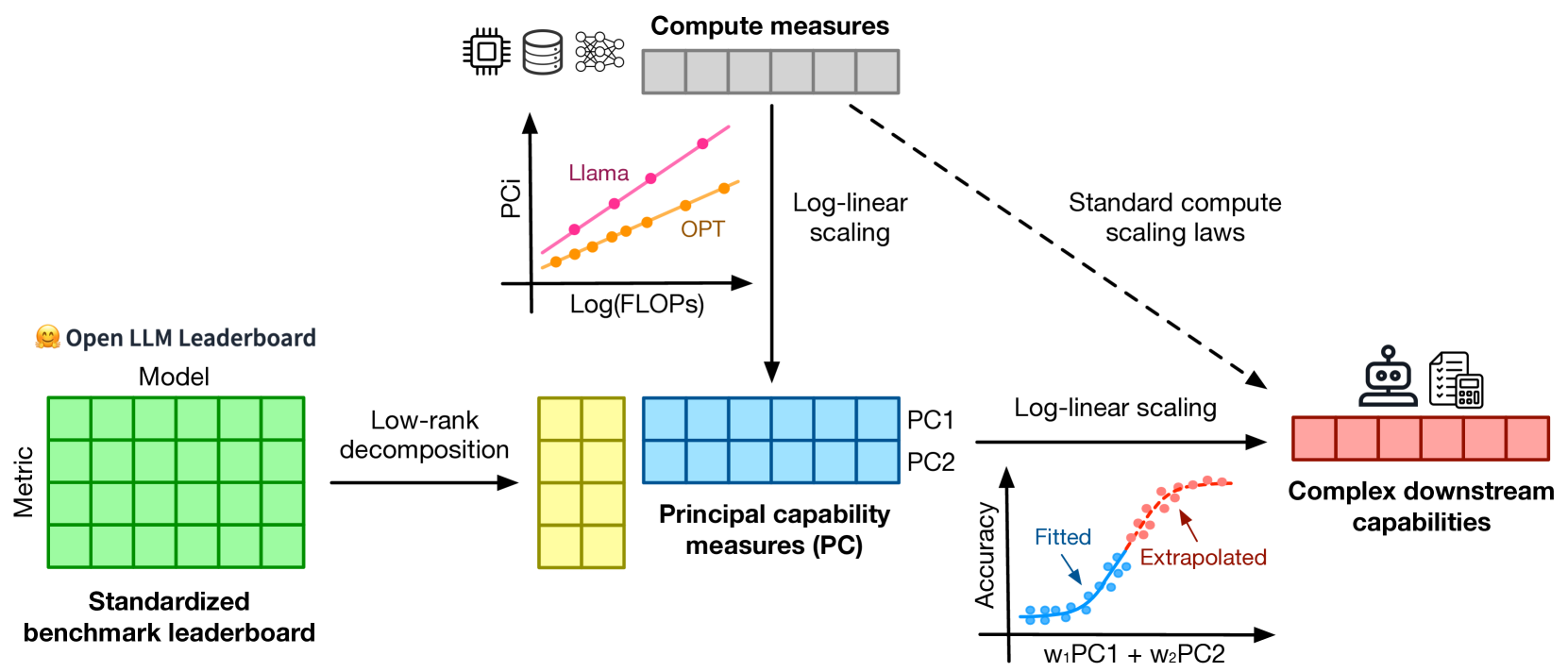
1
Observational Scaling Laws and the Predictability of Language Model Performance
Yangjun Ruan, Chris J. Maddison, Tatsunori Hashimoto
Understanding how language model performance varies with scale is critical to benchmark and algorithm development. Scaling laws are one approach to building this understanding, but the requirement of training models across many different scales has limited their use. We propose an alternative, observational approach that bypasses model training and instead builds scaling laws from ~80 publically available models. Building a single scaling law from multiple model families is challenging due to large variations in their training compute efficiencies and capabilities. However, we show that these variations are consistent with a simple, generalized scaling law where language model performance is a function of a low-dimensional capability space, and model families only vary in their efficiency in converting training compute to capabilities. Using this approach, we show the surprising predictability of complex scaling phenomena: we show that several emergent phenomena follow a smooth, sigmoidal behavior and are predictable from small models; we show that the agent performance of models such as GPT-4 can be precisely predicted from simpler non-agentic benchmarks; and we show how to predict the impact of post-training interventions like Chain-of-Thought and Self-Consistency as language model capabilities continue to improve.
Read more5/20/2024
🔮
0
Scaling Laws Do Not Scale
Fernando Diaz, Michael Madaio
Recent work has advocated for training AI models on ever-larger datasets, arguing that as the size of a dataset increases, the performance of a model trained on that dataset will correspondingly increase (referred to as scaling laws). In this paper, we draw on literature from the social sciences and machine learning to critically interrogate these claims. We argue that this scaling law relationship depends on metrics used to measure performance that may not correspond with how different groups of people perceive the quality of models' output. As the size of datasets used to train large AI models grows and AI systems impact ever larger groups of people, the number of distinct communities represented in training or evaluation datasets grows. It is thus even more likely that communities represented in datasets may have values or preferences not reflected in (or at odds with) the metrics used to evaluate model performance in scaling laws. Different communities may also have values in tension with each other, leading to difficult, potentially irreconcilable choices about metrics used for model evaluations -- threatening the validity of claims that model performance is improving at scale. We end the paper with implications for AI development: that the motivation for scraping ever-larger datasets may be based on fundamentally flawed assumptions about model performance. That is, models may not, in fact, continue to improve as the datasets get larger -- at least not for all people or communities impacted by those models. We suggest opportunities for the field to rethink norms and values in AI development, resisting claims for universality of large models, fostering more local, small-scale designs, and other ways to resist the impetus towards scale in AI.
Read more7/30/2024