xLSTM-UNet can be an Effective 2D & 3D Medical Image Segmentation Backbone with Vision-LSTM (ViL) better than its Mamba Counterpart

1

Sign in to get full access
Overview
- This paper presents a new model called xLSTM-UNet, which combines an extended Long Short-Term Memory (xLSTM) module with a UNet architecture for effective 2D and 3D medical image segmentation.
- The authors compare xLSTM-UNet to a previous model called Vision-Mamba (ViM-UNet), which uses a Mamba state-space model for sequential learning.
- The results show that xLSTM-UNet outperforms ViM-UNet in both 2D and 3D medical image segmentation tasks, demonstrating the effectiveness of the xLSTM module as a backbone.
Plain English Explanation
The paper introduces a new deep learning model called xLSTM-UNet that is designed to be an effective tool for segmenting medical images, both in 2D and 3D. Segmentation is the process of dividing an image into distinct regions or objects, which is an important task in medical imaging for tasks like identifying tumors or other anatomical structures.
The key innovation in xLSTM-UNet is the use of an extended Long Short-Term Memory (xLSTM) module, which is a type of recurrent neural network that can capture long-range dependencies in sequential data. The xLSTM module is combined with a UNet architecture, which is a well-known model for image segmentation that uses an encoder-decoder structure.
The authors compare xLSTM-UNet to an earlier model called ViM-UNet, which uses a different type of sequential modeling called a Mamba state-space model. Their experiments show that xLSTM-UNet outperforms ViM-UNet in both 2D and 3D medical image segmentation tasks, indicating that the xLSTM module is a more effective backbone for this type of problem.
Overall, this research demonstrates the potential of xLSTM-UNet as a powerful tool for medical image analysis, with applications in areas like disease diagnosis, treatment planning, and monitoring disease progression.
Technical Explanation
The paper introduces a new deep learning model called xLSTM-UNet, which combines an extended Long Short-Term Memory (xLSTM) module with a UNet architecture for effective 2D and 3D medical image segmentation. The authors compare the performance of xLSTM-UNet to a previous model called ViM-UNet, which uses a Mamba state-space model for sequential learning.
The key components of the xLSTM-UNet model are:
- xLSTM Module: The extended LSTM module is a type of recurrent neural network that can capture long-range dependencies in sequential data, which is important for modeling the complex spatial and temporal relationships in medical images.
- UNet Architecture: The UNet architecture is a well-established model for image segmentation tasks, which uses an encoder-decoder structure to extract and combine features at multiple scales.
The authors evaluate the performance of xLSTM-UNet and ViM-UNet on both 2D and 3D medical image segmentation tasks, using publicly available datasets. The results show that xLSTM-UNet outperforms ViM-UNet in terms of segmentation accuracy, demonstrating the effectiveness of the xLSTM module as a backbone for this type of problem.
Critical Analysis
The paper provides a thorough evaluation of the xLSTM-UNet model and its performance compared to the ViM-UNet baseline. However, there are a few potential limitations and areas for further research:
-
Dataset Diversity: The experiments were conducted on a limited number of medical imaging datasets, primarily focused on brain and cardiac imaging. It would be valuable to evaluate the model's performance on a wider range of medical imaging tasks and datasets to assess its generalizability.
-
Computational Efficiency: The paper does not provide detailed information about the computational complexity and resource requirements of the xLSTM-UNet model. As medical imaging applications often require real-time or low-latency processing, the model's efficiency should be considered.
-
Explainability: Deep learning models, including xLSTM-UNet, can be challenging to interpret and understand the underlying decision-making processes. Incorporating more explainable AI techniques could enhance the model's transparency and trustworthiness for medical professionals.
-
Comparison to Other Approaches: While the comparison to ViM-UNet is useful, it would be beneficial to benchmark xLSTM-UNet against other state-of-the-art medical image segmentation models, such as Seg-LSTM or Vision-LSTM, to better understand its relative performance.
Overall, the xLSTM-UNet model shows promise as a powerful tool for medical image segmentation, but further research and development may be needed to address the potential limitations and ensure its widespread adoption in clinical settings.
Conclusion
In this paper, the authors present a new deep learning model called xLSTM-UNet that combines an extended Long Short-Term Memory (xLSTM) module with a UNet architecture for effective 2D and 3D medical image segmentation. The results demonstrate that xLSTM-UNet outperforms a previous model called ViM-UNet, which uses a Mamba state-space model for sequential learning.
The key contribution of this work is the development of the xLSTM-UNet model, which leverages the long-range sequential modeling capabilities of the xLSTM module to enhance the performance of the UNet architecture in medical image segmentation tasks. This research highlights the potential of xLSTM-UNet as a powerful tool for various medical imaging applications, such as disease diagnosis, treatment planning, and monitoring disease progression.
While the paper provides a thorough evaluation of the model, there are opportunities for further research to address potential limitations, such as exploring the model's performance on a wider range of medical imaging datasets, assessing its computational efficiency, and investigating more explainable AI techniques. Nonetheless, this work represents an important step forward in the development of advanced deep learning models for medical image analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
1
xLSTM-UNet can be an Effective 2D & 3D Medical Image Segmentation Backbone with Vision-LSTM (ViL) better than its Mamba Counterpart
Tianrun Chen, Chaotao Ding, Lanyun Zhu, Tao Xu, Deyi Ji, Ying Zang, Zejian Li
Convolutional Neural Networks (CNNs) and Vision Transformers (ViT) have been pivotal in biomedical image segmentation, yet their ability to manage long-range dependencies remains constrained by inherent locality and computational overhead. To overcome these challenges, in this technical report, we first propose xLSTM-UNet, a UNet structured deep learning neural network that leverages Vision-LSTM (xLSTM) as its backbone for medical image segmentation. xLSTM is a recently proposed as the successor of Long Short-Term Memory (LSTM) networks and have demonstrated superior performance compared to Transformers and State Space Models (SSMs) like Mamba in Neural Language Processing (NLP) and image classification (as demonstrated in Vision-LSTM, or ViL implementation). Here, xLSTM-UNet we designed extend the success in biomedical image segmentation domain. By integrating the local feature extraction strengths of convolutional layers with the long-range dependency capturing abilities of xLSTM, xLSTM-UNet offers a robust solution for comprehensive image analysis. We validate the efficacy of xLSTM-UNet through experiments. Our findings demonstrate that xLSTM-UNet consistently surpasses the performance of leading CNN-based, Transformer-based, and Mamba-based segmentation networks in multiple datasets in biomedical segmentation including organs in abdomen MRI, instruments in endoscopic images, and cells in microscopic images. With comprehensive experiments performed, this technical report highlights the potential of xLSTM-based architectures in advancing biomedical image analysis in both 2D and 3D. The code, models, and datasets are publicly available at href{http://tianrun-chen.github.io/xLSTM-UNet/}{http://tianrun-chen.github.io/xLSTM-Unet/}
Read more7/2/2024
👀
0
Are Vision xLSTM Embedded UNet More Reliable in Medical 3D Image Segmentation?
Pallabi Dutta, Soham Bose, Swalpa Kumar Roy, Sushmita Mitra
The advancement of developing efficient medical image segmentation has evolved from initial dependence on Convolutional Neural Networks (CNNs) to the present investigation of hybrid models that combine CNNs with Vision Transformers. Furthermore, there is an increasing focus on creating architectures that are both high-performing in medical image segmentation tasks and computationally efficient to be deployed on systems with limited resources. Although transformers have several advantages like capturing global dependencies in the input data, they face challenges such as high computational and memory complexity. This paper investigates the integration of CNNs and Vision Extended Long Short-Term Memory (Vision-xLSTM) models by introducing a novel approach called UVixLSTM. The Vision-xLSTM blocks captures temporal and global relationships within the patches extracted from the CNN feature maps. The convolutional feature reconstruction path upsamples the output volume from the Vision-xLSTM blocks to produce the segmentation output. Our primary objective is to propose that Vision-xLSTM forms a reliable backbone for medical image segmentation tasks, offering excellent segmentation performance and reduced computational complexity. UVixLSTM exhibits superior performance compared to state-of-the-art networks on the publicly-available Synapse dataset. Code is available at: https://github.com/duttapallabi2907/UVixLSTM
Read more6/26/2024
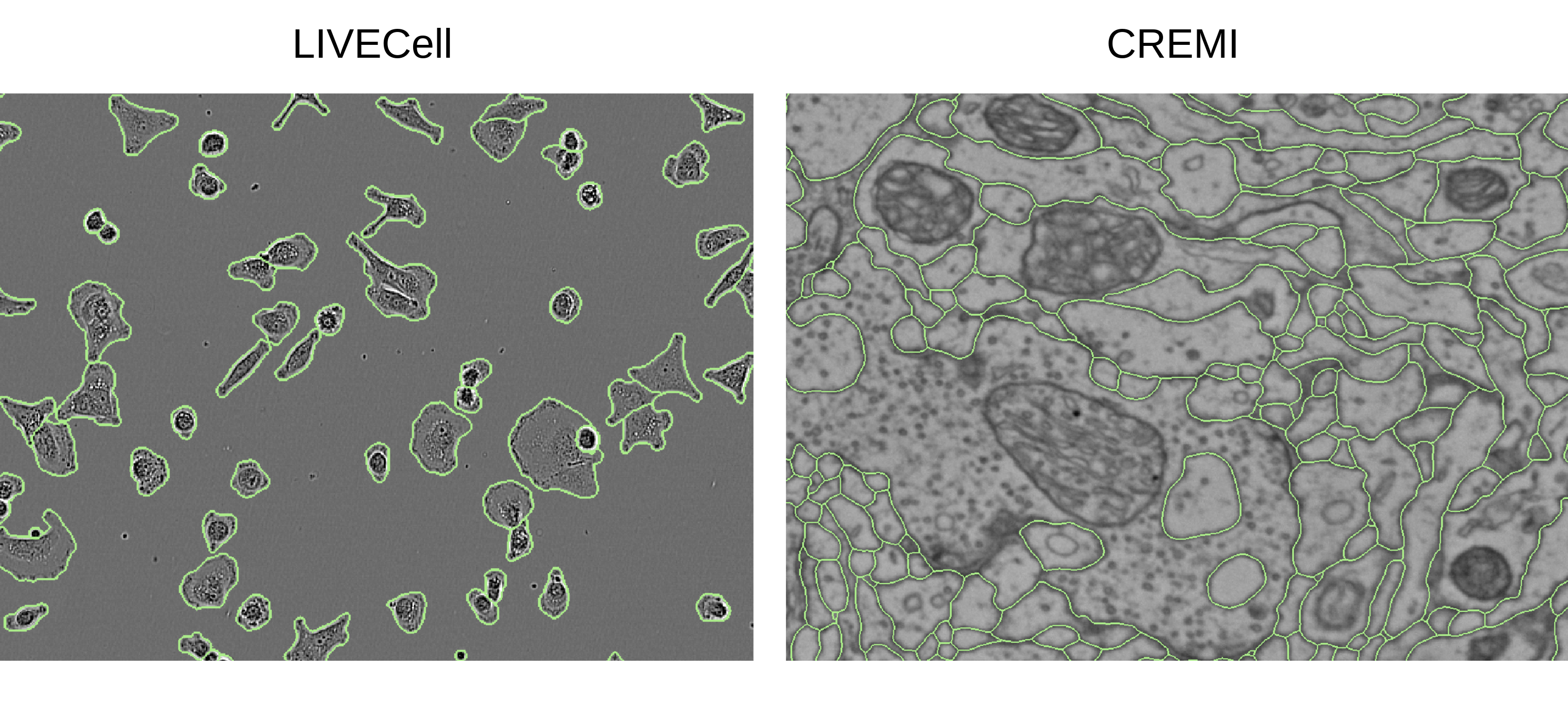
0
ViM-UNet: Vision Mamba for Biomedical Segmentation
Anwai Archit, Constantin Pape
CNNs, most notably the UNet, are the default architecture for biomedical segmentation. Transformer-based approaches, such as UNETR, have been proposed to replace them, benefiting from a global field of view, but suffering from larger runtimes and higher parameter counts. The recent Vision Mamba architecture offers a compelling alternative to transformers, also providing a global field of view, but at higher efficiency. Here, we introduce ViM-UNet, a novel segmentation architecture based on it and compare it to UNet and UNETR for two challenging microscopy instance segmentation tasks. We find that it performs similarly or better than UNet, depending on the task, and outperforms UNETR while being more efficient. Our code is open source and documented at https://github.com/constantinpape/torch-em/blob/main/vimunet.md.
Read more5/16/2024
🚀
0
Seg-LSTM: Performance of xLSTM for Semantic Segmentation of Remotely Sensed Images
Qinfeng Zhu, Yuanzhi Cai, Lei Fan
Recent advancements in autoregressive networks with linear complexity have driven significant research progress, demonstrating exceptional performance in large language models. A representative model is the Extended Long Short-Term Memory (xLSTM), which incorporates gating mechanisms and memory structures, performing comparably to Transformer architectures in long-sequence language tasks. Autoregressive networks such as xLSTM can utilize image serialization to extend their application to visual tasks such as classification and segmentation. Although existing studies have demonstrated Vision-LSTM's impressive results in image classification, its performance in image semantic segmentation remains unverified. Our study represents the first attempt to evaluate the effectiveness of Vision-LSTM in the semantic segmentation of remotely sensed images. This evaluation is based on a specifically designed encoder-decoder architecture named Seg-LSTM, and comparisons with state-of-the-art segmentation networks. Our study found that Vision-LSTM's performance in semantic segmentation was limited and generally inferior to Vision-Transformers-based and Vision-Mamba-based models in most comparative tests. Future research directions for enhancing Vision-LSTM are recommended. The source code is available from https://github.com/zhuqinfeng1999/Seg-LSTM.
Read more6/21/2024