XMainframe: A Large Language Model for Mainframe Modernization

2

Sign in to get full access
Overview
- This paper presents XMainframe, a large language model designed for mainframe modernization tasks.
- XMainframe is trained on a diverse dataset of mainframe code, documentation, and related text to enable better understanding and generation of mainframe-specific content.
- The model can be used for a variety of applications, such as code translation, software documentation generation, and automated refactoring.
Plain English Explanation
The paper introduces XMainframe, a large language model that has been specifically designed to work with mainframe computer systems. Mainframes are powerful, enterprise-level computers that are still widely used in industries like banking, insurance, and government.
Large language models are artificial intelligence systems that can understand and generate human language. XMainframe has been trained on a large dataset of mainframe-related content, including code, documentation, and other technical materials. This allows the model to better understand the unique language and concepts used in the mainframe world.
By using XMainframe, developers and IT professionals working on mainframe systems can benefit in several ways:
- Code Translation: The model can translate legacy mainframe code into more modern programming languages, making it easier to migrate and maintain these systems.
- Software Documentation: XMainframe can automatically generate high-quality documentation for mainframe software, saving time and improving the quality of these critical materials.
- Automated Refactoring: The model can analyze mainframe code and suggest improvements or optimizations, helping to modernize and improve the efficiency of these systems.
Overall, XMainframe represents an important advance in the field of large language models for code generation and software engineering, with the potential to significantly improve the maintenance and evolution of mainframe systems.
Technical Explanation
The researchers behind XMainframe developed a large language model specifically tailored for the mainframe computing domain. They trained the model on a diverse dataset of mainframe-related text, including code, technical documentation, and other relevant materials.
The model architecture is based on the transformer design, which has been shown to be effective for a variety of natural language processing tasks. The researchers used techniques like unsupervised pretraining and fine-tuning to optimize the model's performance on mainframe-specific tasks.
Through extensive evaluation, the researchers demonstrated that XMainframe outperforms generic language models on a variety of mainframe-related benchmarks, including code translation, documentation generation, and automated refactoring. The model's strong performance is attributed to its specialized training on mainframe-centric data, which allows it to better capture the nuances and complexities of this domain.
Critical Analysis
The researchers have taken a thoughtful and well-designed approach to developing XMainframe, a large language model specifically tailored for the mainframe computing domain. By focusing on this niche but important area, they have the potential to make significant contributions to the ongoing efforts to modernize and maintain mainframe systems.
One potential limitation of the research is the scope of the dataset used to train the model. While the researchers claim it is diverse, it would be valuable to understand the breadth and depth of the data sources, as well as any biases or gaps that may exist. Additionally, the researchers could have provided more details on the specific techniques used for pretraining and fine-tuning the model, which could help inform future research in this area.
Furthermore, the researchers could have explored the potential ethical implications of their work, particularly around the use of AI-generated code and documentation in mission-critical mainframe systems. Ensuring the reliability, security, and transparency of these AI-powered tools will be essential as they become more widely adopted.
Overall, the XMainframe research represents an important step forward in the application of large language models to software engineering challenges, and the researchers should be commended for their innovative approach. As the field of AI-powered mainframe modernization continues to evolve, it will be crucial to address the technical, ethical, and practical considerations that come with the deployment of these powerful technologies.
Conclusion
The XMainframe paper presents a novel large language model designed specifically for the mainframe computing domain. By training the model on a diverse dataset of mainframe-related content, the researchers have developed a powerful tool that can significantly improve the maintenance and evolution of these critical enterprise systems.
The potential applications of XMainframe, such as code translation, software documentation generation, and automated refactoring, could have a transformative impact on the way that mainframe systems are developed and maintained. As the adoption of large language models continues to grow in the software engineering field, the XMainframe research represents an important milestone in the ongoing efforts to leverage these powerful AI technologies to address the unique challenges of the mainframe ecosystem.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
2
XMainframe: A Large Language Model for Mainframe Modernization
Anh T. V. Dau, Hieu Trung Dao, Anh Tuan Nguyen, Hieu Trung Tran, Phong X. Nguyen, Nghi D. Q. Bui
Mainframe operating systems, despite their inception in the 1940s, continue to support critical sectors like finance and government. However, these systems are often viewed as outdated, requiring extensive maintenance and modernization. Addressing this challenge necessitates innovative tools that can understand and interact with legacy codebases. To this end, we introduce XMainframe, a state-of-the-art large language model (LLM) specifically designed with knowledge of mainframe legacy systems and COBOL codebases. Our solution involves the creation of an extensive data collection pipeline to produce high-quality training datasets, enhancing XMainframe's performance in this specialized domain. Additionally, we present MainframeBench, a comprehensive benchmark for assessing mainframe knowledge, including multiple-choice questions, question answering, and COBOL code summarization. Our empirical evaluations demonstrate that XMainframe consistently outperforms existing state-of-the-art LLMs across these tasks. Specifically, XMainframe achieves 30% higher accuracy than DeepSeek-Coder on multiple-choice questions, doubles the BLEU score of Mixtral-Instruct 8x7B on question answering, and scores six times higher than GPT-3.5 on COBOL summarization. Our work highlights the potential of XMainframe to drive significant advancements in managing and modernizing legacy systems, thereby enhancing productivity and saving time for software developers.
Read more8/27/2024
1
L2MAC: Large Language Model Automatic Computer for Extensive Code Generation
Samuel Holt, Max Ruiz Luyten, Mihaela van der Schaar
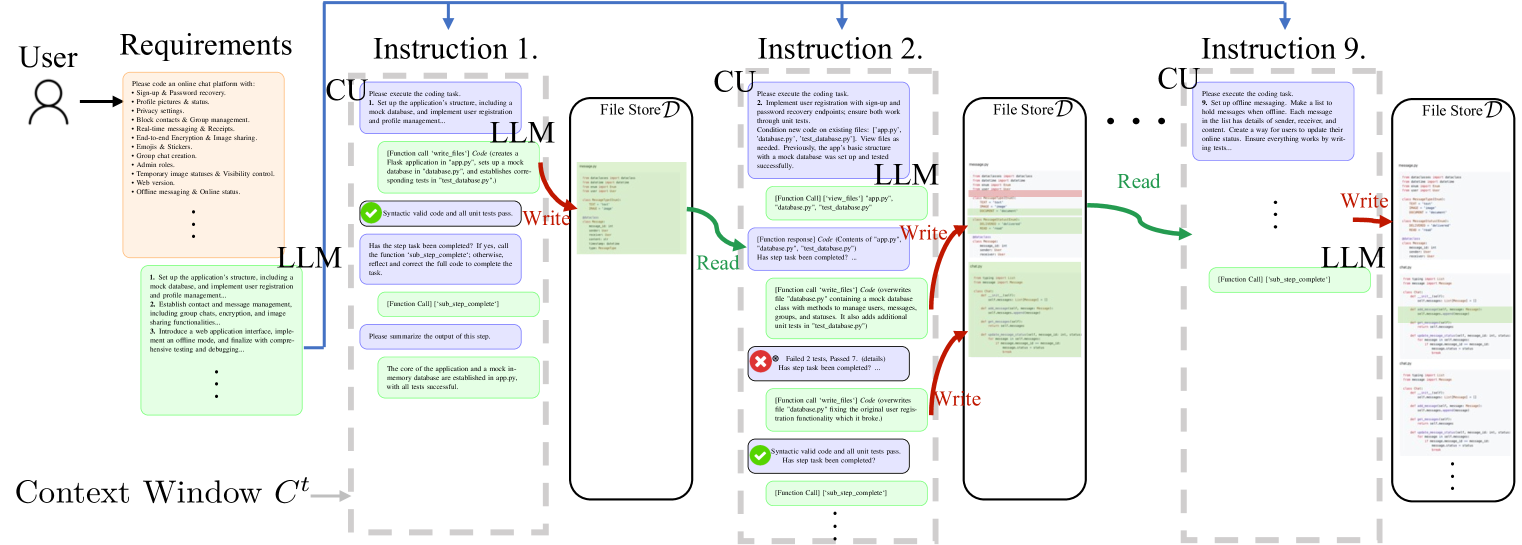
Transformer-based large language models (LLMs) are constrained by the fixed context window of the underlying transformer architecture, hindering their ability to produce long and coherent outputs. Memory-augmented LLMs are a promising solution, but current approaches cannot handle long output generation tasks since they (1) only focus on reading memory and reduce its evolution to the concatenation of new memories or (2) use very specialized memories that cannot adapt to other domains. This paper presents L2MAC, the first practical LLM-based general-purpose stored-program automatic computer (von Neumann architecture) framework, an LLM-based multi-agent system, for long and consistent output generation. Its memory has two components: the instruction registry, which is populated with a prompt program to solve the user-given task, and a file store, which will contain the final and intermediate outputs. Each instruction in turn is executed by a separate LLM agent, whose context is managed by a control unit capable of precise memory reading and writing to ensure effective interaction with the file store. These components enable L2MAC to generate extensive outputs, bypassing the constraints of the finite context window while producing outputs that fulfill a complex user-specified task. We empirically demonstrate that L2MAC achieves state-of-the-art performance in generating large codebases for system design tasks, significantly outperforming other coding methods in implementing the detailed user-specified task; we show that L2MAC works for general-purpose extensive text-based tasks, such as writing an entire book; and we provide valuable insights into L2MAC's performance improvement over existing methods.
Read more4/11/2024

0
A Survey on Large Language Models for Code Generation
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, Sunghun Kim
Large Language Models (LLMs) have garnered remarkable advancements across diverse code-related tasks, known as Code LLMs, particularly in code generation that generates source code with LLM from natural language descriptions. This burgeoning field has captured significant interest from both academic researchers and industry professionals due to its practical significance in software development, e.g., GitHub Copilot. Despite the active exploration of LLMs for a variety of code tasks, either from the perspective of natural language processing (NLP) or software engineering (SE) or both, there is a noticeable absence of a comprehensive and up-to-date literature review dedicated to LLM for code generation. In this survey, we aim to bridge this gap by providing a systematic literature review that serves as a valuable reference for researchers investigating the cutting-edge progress in LLMs for code generation. We introduce a taxonomy to categorize and discuss the recent developments in LLMs for code generation, covering aspects such as data curation, latest advances, performance evaluation, and real-world applications. In addition, we present a historical overview of the evolution of LLMs for code generation and offer an empirical comparison using the widely recognized HumanEval and MBPP benchmarks to highlight the progressive enhancements in LLM capabilities for code generation. We identify critical challenges and promising opportunities regarding the gap between academia and practical development. Furthermore, we have established a dedicated resource website (https://codellm.github.io) to continuously document and disseminate the most recent advances in the field.
Read more6/4/2024

0
CodexGraph: Bridging Large Language Models and Code Repositories via Code Graph Databases
Xiangyan Liu, Bo Lan, Zhiyuan Hu, Yang Liu, Zhicheng Zhang, Fei Wang, Michael Shieh, Wenmeng Zhou
Large Language Models (LLMs) excel in stand-alone code tasks like HumanEval and MBPP, but struggle with handling entire code repositories. This challenge has prompted research on enhancing LLM-codebase interaction at a repository scale. Current solutions rely on similarity-based retrieval or manual tools and APIs, each with notable drawbacks. Similarity-based retrieval often has low recall in complex tasks, while manual tools and APIs are typically task-specific and require expert knowledge, reducing their generalizability across diverse code tasks and real-world applications. To mitigate these limitations, we introduce CodexGraph, a system that integrates LLM agents with graph database interfaces extracted from code repositories. By leveraging the structural properties of graph databases and the flexibility of the graph query language, CodexGraph enables the LLM agent to construct and execute queries, allowing for precise, code structure-aware context retrieval and code navigation. We assess CodexGraph using three benchmarks: CrossCodeEval, SWE-bench, and EvoCodeBench. Additionally, we develop five real-world coding applications. With a unified graph database schema, CodexGraph demonstrates competitive performance and potential in both academic and real-world environments, showcasing its versatility and efficacy in software engineering. Our application demo: https://github.com/modelscope/modelscope-agent/tree/master/apps/codexgraph_agent.
Read more8/13/2024