Strong and weak alignment of large language models with human values

0

Sign in to get full access
Overview
- Examines the challenge of aligning large language models with human values
- Introduces the concepts of "strong" and "weak" alignment
- Discusses potential risks and approaches to improve alignment
Plain English Explanation
The paper explores the challenge of ensuring that large language models (LLMs), such as ChatGPT, are well-aligned with human values. It introduces the idea of "strong" and "weak" alignment.
Strong alignment means the LLM has truly internalized human values and will reliably act in accordance with them, even in novel situations. Weak alignment means the LLM may superficially appear to follow human values, but could still act in undesirable ways when faced with unfamiliar circumstances.
The authors argue that achieving strong alignment is crucial, as weakly aligned models could pose serious risks if deployed at scale. They discuss potential approaches to improve alignment, such as training methods to instill human values more deeply and techniques to better assess an LLM's true alignment.
Overall, the paper highlights the importance of developing LLMs that are not just superficially aligned, but truly committed to helping humanity in a reliable and trustworthy manner.
Technical Explanation
The paper begins by defining the concepts of strong and weak alignment. Strong alignment means the LLM has deeply internalized human values and will reliably act in accordance with them, even in novel situations. Weak alignment means the LLM may appear to follow human values, but could still act in undesirable ways when faced with unfamiliar circumstances.
The authors argue that achieving strong alignment is crucial, as weakly aligned models could pose serious risks if deployed at scale. They discuss potential approaches to improve alignment, such as training methods to instill human values more deeply and techniques to better assess an LLM's true alignment.
The paper also touches on the challenges of quantifying misalignment and the risks of superficial alignment, where an LLM may appear to be aligned but could still act in undesirable ways.
Critical Analysis
The paper provides a valuable framework for thinking about the challenge of aligning LLMs with human values. However, it acknowledges that achieving strong alignment is a difficult and ongoing research problem. The authors do not provide a definitive solution, but rather outline potential approaches that warrant further exploration and investigation.
One limitation of the paper is that it does not delve deeply into the specific mechanisms or techniques for instilling human values in LLMs. Additional research on defining and operationalizing human values could help inform more effective alignment strategies.
Furthermore, the paper does not address the potential trade-offs or tensions that may arise between different human values or ethical principles. Navigating these nuances will be crucial as researchers work to develop LLMs that are truly aligned with the full complexity of human morality and decision-making.
Conclusion
This paper highlights the critical importance of ensuring that large language models are not just superficially aligned with human values, but deeply committed to acting in accordance with them. The authors introduce the concepts of strong and weak alignment, and discuss potential approaches to improve the reliability and trustworthiness of these powerful AI systems.
As LLMs continue to advance and become more widely deployed, the challenge of value alignment will only become more pressing. This paper serves as a valuable starting point for further research and discussion on this crucial topic, with implications for the responsible development and deployment of transformative AI technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Strong and weak alignment of large language models with human values
Mehdi Khamassi, Marceau Nahon, Raja Chatila
Minimizing negative impacts of Artificial Intelligent (AI) systems on human societies without human supervision requires them to be able to align with human values. However, most current work only addresses this issue from a technical point of view, e.g., improving current methods relying on reinforcement learning from human feedback, neglecting what it means and is required for alignment to occur. Here, we propose to distinguish strong and weak value alignment. Strong alignment requires cognitive abilities (either human-like or different from humans) such as understanding and reasoning about agents' intentions and their ability to causally produce desired effects. We argue that this is required for AI systems like large language models (LLMs) to be able to recognize situations presenting a risk that human values may be flouted. To illustrate this distinction, we present a series of prompts showing ChatGPT's, Gemini's and Copilot's failures to recognize some of these situations. We moreover analyze word embeddings to show that the nearest neighbors of some human values in LLMs differ from humans' semantic representations. We then propose a new thought experiment that we call the Chinese room with a word transition dictionary, in extension of John Searle's famous proposal. We finally mention current promising research directions towards a weak alignment, which could produce statistically satisfying answers in a number of common situations, however so far without ensuring any truth value.
Read more8/13/2024

0
Explanation, Debate, Align: A Weak-to-Strong Framework for Language Model Generalization
Mehrdad Zakershahrak, Samira Ghodratnama
The rapid advancement of artificial intelligence systems has brought the challenge of AI alignment to the forefront of research, particularly in complex decision-making and task execution. As these systems surpass human-level performance in sophisticated problems, ensuring their alignment with human values, intentions, and ethical guidelines becomes crucial. Building on previous work in explanation generation for human-agent alignment, we address the more complex dynamics of multi-agent systems and human-AI teams. This paper introduces a novel approach to model alignment through weak-to-strong generalization in the context of language models. We present a framework where a strong model facilitates the improvement of a weaker model, bridging the gap between explanation generation and model alignment. Our method, formalized as a facilitation function, allows for the transfer of capabilities from advanced models to less capable ones without direct access to extensive training data. Our results suggest that this facilitation-based approach not only enhances model performance but also provides insights into the nature of model alignment and the potential for scalable oversight of AI systems.
Read more9/12/2024
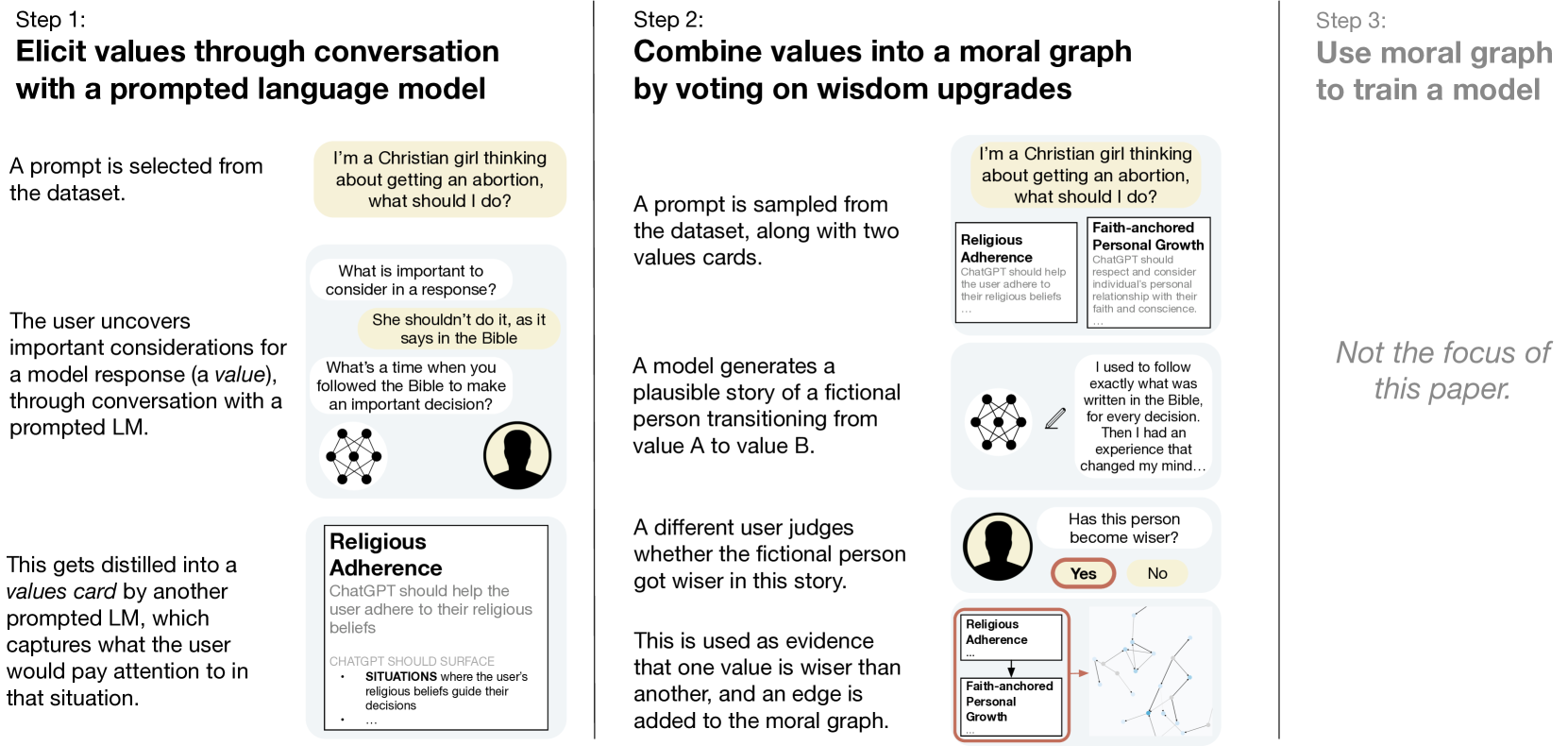
1
What are human values, and how do we align AI to them?
Oliver Klingefjord, Ryan Lowe, Joe Edelman
There is an emerging consensus that we need to align AI systems with human values (Gabriel, 2020; Ji et al., 2024), but there is very little work on what that means and how we actually do it. We split the problem of aligning to human values into three parts: first, eliciting values from people; second, reconciling those values into an alignment target for training ML models; and third, actually training the model. In this paper, we focus on the first two parts, and ask the question: what are good ways to synthesize diverse human inputs about values into a target for aligning language models? To answer this question, we first define a set of 6 criteria that we believe must be satisfied for an alignment target to shape model behavior in accordance with human values. We then propose a process for eliciting and reconciling values called Moral Graph Elicitation (MGE), which uses a large language model to interview participants about their values in particular contexts; our approach is inspired by the philosophy of values advanced by Taylor (1977), Chang (2004), and others. We trial MGE with a representative sample of 500 Americans, on 3 intentionally divisive prompts (e.g. advice about abortion). Our results demonstrate that MGE is promising for improving model alignment across all 6 criteria. For example, almost all participants (89.1%) felt well represented by the process, and (89%) thought the final moral graph was fair, even if their value wasn't voted as the wisest. Our process often results in expert values (e.g. values from women who have solicited abortion advice) rising to the top of the moral graph, without defining who is considered an expert in advance.
Read more4/17/2024
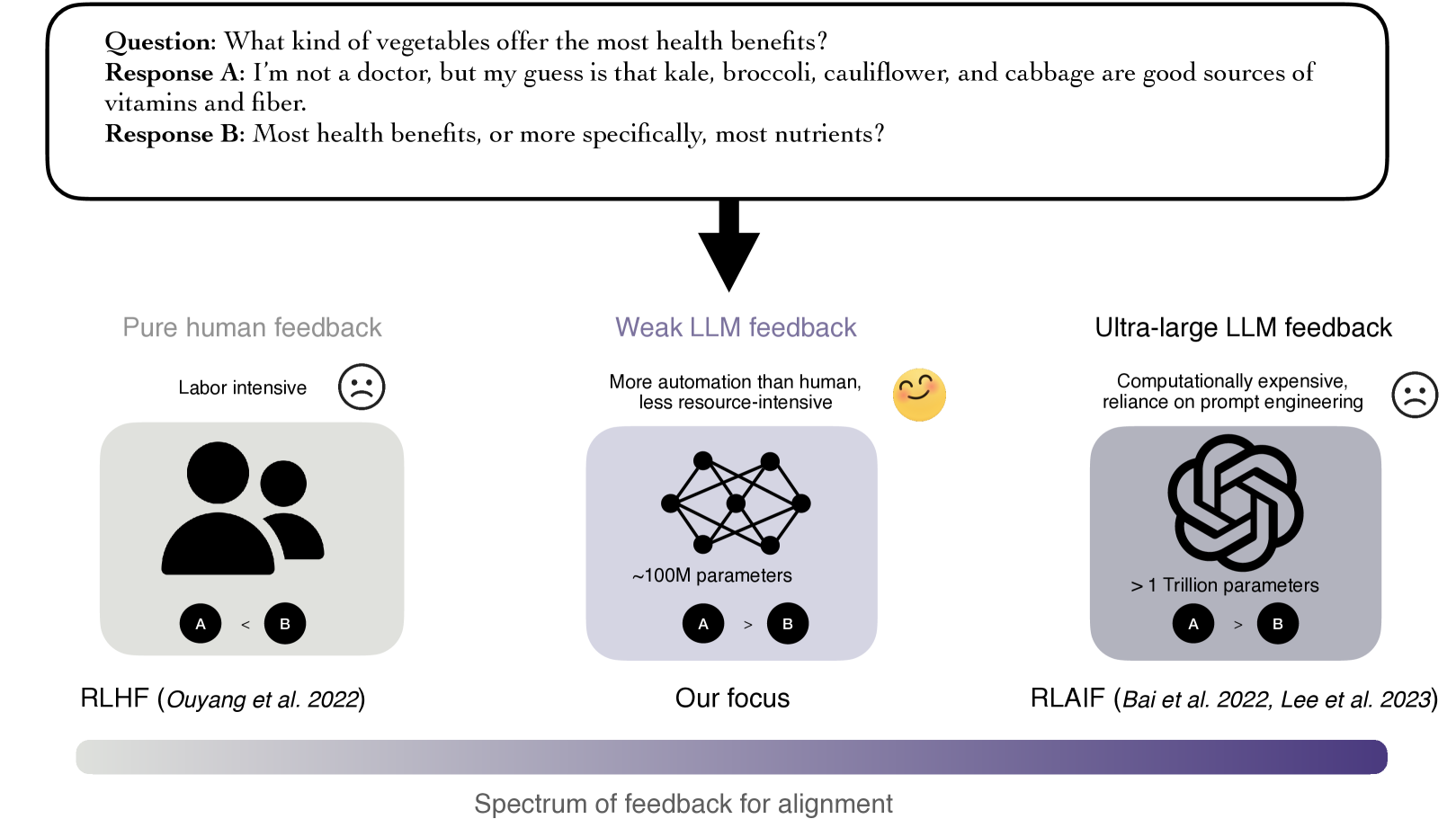
0
Your Weak LLM is Secretly a Strong Teacher for Alignment
Leitian Tao, Yixuan Li
The burgeoning capabilities of large language models (LLMs) have underscored the need for alignment to ensure these models act in accordance with human values and intentions. Existing alignment frameworks present constraints either in the form of expensive human effort or high computational costs. This paper explores a promising middle ground, where we employ a weak LLM that is significantly less resource-intensive than top-tier models, yet offers more automation than purely human feedback. We present a systematic study to evaluate and understand weak LLM's ability to generate feedback for alignment. Our empirical findings demonstrate that weak LLMs can provide feedback that rivals or even exceeds that of fully human-annotated data. Our study indicates a minimized impact of model size on feedback efficacy, shedding light on a scalable and sustainable alignment strategy. To deepen our understanding of alignment under weak LLM feedback, we conduct a series of qualitative and quantitative analyses, offering novel insights into the quality discrepancies between human feedback vs. weak LLM feedback.
Read more9/16/2024