ZoDi: Zero-Shot Domain Adaptation with Diffusion-Based Image Transfer

0

Sign in to get full access
Overview
- The paper introduces ZoDi, a zero-shot domain adaptation approach that uses diffusion-based image transfer to adapt a model trained on one dataset to a different, unseen dataset.
- ZoDi leverages the flexibility of diffusion models to generate realistic images that bridge the gap between the source and target domains.
- The method achieves strong performance on various segmentation tasks, outperforming existing zero-shot domain adaptation techniques.
Plain English Explanation
Zero-shot domain adaptation is a challenge in machine learning where you want to use a model trained on one dataset (the source domain) to perform well on a completely different dataset (the target domain), without any additional training on the target domain. [link to Zero-Shot Domain Adaptation] This is difficult because the distribution of the data in the source and target domains can be very different, leading to poor performance when the source model is applied directly to the target domain.
The key innovation in this paper is the use of [link to Diffusion Models] to bridge the gap between the source and target domains. Diffusion models are a type of generative model that can create realistic-looking images by gradually adding noise to an input image and then reversing the process to generate a new image. The authors use this property of diffusion models to generate images that combine characteristics of the source and target domains, effectively transferring the knowledge from the source model to the target domain.
The resulting ZoDi (Zero-shot Domain Adaptation with Diffusion-based Image Transfer) method is able to adapt a model trained on one dataset to perform well on a completely different dataset, without any additional training on the target domain. This is a significant advancement, as it allows machine learning models to be deployed more widely without the need for costly data collection and retraining in each new setting.
Technical Explanation
The core idea behind ZoDi is to leverage the power of diffusion models to generate images that bridge the gap between the source and target domains. The authors first train a segmentation model on the source domain. They then train a diffusion model to generate images that combine features of both the source and target domains.
To do this, they use a technique called cross-domain diffusion, where the diffusion model is trained on a mixture of images from both the source and target domains. This allows the diffusion model to learn the common features between the domains and generate images that exhibit characteristics of both.
The authors then use this cross-domain diffusion model to generate images that are used to fine-tune the segmentation model, effectively transferring the knowledge from the source domain to the target domain. This zero-shot adaptation approach is demonstrated on several segmentation tasks, where ZoDi outperforms existing zero-shot domain adaptation techniques.
Critical Analysis
The authors provide a thorough evaluation of ZoDi, demonstrating its effectiveness on a range of segmentation tasks. However, the paper does not address some potential limitations of the approach:
-
Scalability: While ZoDi shows promising results, it's unclear how well the method would scale to larger and more diverse target domains. The success of the approach may be limited by the ability of the diffusion model to effectively bridge the gap between the domains.
-
Interpretability: As with many deep learning approaches, the inner workings of ZoDi can be difficult to interpret. It's not always clear why the method succeeds or fails in specific cases, which can be a hindrance for real-world deployment.
-
Computational Complexity: Training both the segmentation model and the cross-domain diffusion model can be computationally expensive, which may limit the practicality of ZoDi for some applications.
Conclusion
The ZoDi approach presented in this paper represents a significant advancement in zero-shot domain adaptation, leveraging the power of diffusion models to effectively bridge the gap between source and target domains. The method's strong performance on various segmentation tasks suggests it could be a valuable tool for deploying machine learning models more widely without the need for costly data collection and retraining. However, further research is needed to address the potential limitations of scalability, interpretability, and computational complexity.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ZoDi: Zero-Shot Domain Adaptation with Diffusion-Based Image Transfer
Hiroki Azuma, Yusuke Matsui, Atsuto Maki
Deep learning models achieve high accuracy in segmentation tasks among others, yet domain shift often degrades the models' performance, which can be critical in real-world scenarios where no target images are available. This paper proposes a zero-shot domain adaptation method based on diffusion models, called ZoDi, which is two-fold by the design: zero-shot image transfer and model adaptation. First, we utilize an off-the-shelf diffusion model to synthesize target-like images by transferring the domain of source images to the target domain. In this we specifically try to maintain the layout and content by utilising layout-to-image diffusion models with stochastic inversion. Secondly, we train the model using both source images and synthesized images with the original segmentation maps while maximizing the feature similarity of images from the two domains to learn domain-robust representations. Through experiments we show benefits of ZoDi in the task of image segmentation over state-of-the-art methods. It is also more applicable than existing CLIP-based methods because it assumes no specific backbone or models, and it enables to estimate the model's performance without target images by inspecting generated images. Our implementation will be publicly available.
Read more9/26/2024
0
Zero-shot domain adaptation based on dual-level mix and contrast
Yu Zhe, Jun Sakuma
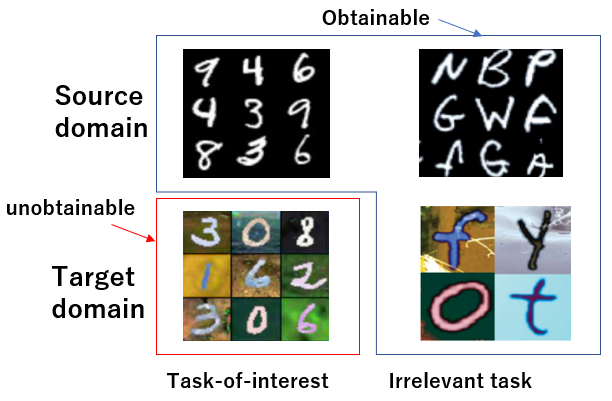
Zero-shot domain adaptation (ZSDA) is a domain adaptation problem in the situation that labeled samples for a target task (task of interest) are only available from the source domain at training time, but for a task different from the task of interest (irrelevant task), labeled samples are available from both source and target domains. In this situation, classical domain adaptation techniques can only learn domain-invariant features in the irrelevant task. However, due to the difference in sample distribution between the two tasks, domain-invariant features learned in the irrelevant task are biased and not necessarily domain-invariant in the task of interest. To solve this problem, this paper proposes a new ZSDA method to learn domain-invariant features with low task bias. To this end, we propose (1) data augmentation with dual-level mixups in both task and domain to fill the absence of target task-of-interest data, (2) an extension of domain adversarial learning to learn domain-invariant features with less task bias, and (3) a new dual-level contrastive learning method that enhances domain-invariance and less task biasedness of features. Experimental results show that our proposal achieves good performance on several benchmarks.
Read more6/28/2024
📊
0
Exploring Data Efficiency in Zero-Shot Learning with Diffusion Models
Zihan Ye, Shreyank N. Gowda, Xiaobo Jin, Xiaowei Huang, Haotian Xu, Yaochu Jin, Kaizhu Huang
Zero-Shot Learning (ZSL) aims to enable classifiers to identify unseen classes by enhancing data efficiency at the class level. This is achieved by generating image features from pre-defined semantics of unseen classes. However, most current approaches heavily depend on the number of samples from seen classes, i.e. they do not consider instance-level effectiveness. In this paper, we demonstrate that limited seen examples generally result in deteriorated performance of generative models. To overcome these challenges, we propose ZeroDiff, a Diffusion-based Generative ZSL model. This unified framework incorporates diffusion models to improve data efficiency at both the class and instance levels. Specifically, for instance-level effectiveness, ZeroDiff utilizes a forward diffusion chain to transform limited data into an expanded set of noised data. For class-level effectiveness, we design a two-branch generation structure that consists of a Diffusion-based Feature Generator (DFG) and a Diffusion-based Representation Generator (DRG). DFG focuses on learning and sampling the distribution of cross-entropy-based features, whilst DRG learns the supervised contrastive-based representation to boost the zero-shot capabilities of DFG. Additionally, we employ three discriminators to evaluate generated features from various aspects and introduce a Wasserstein-distance-based mutual learning loss to transfer knowledge among discriminators, thereby enhancing guidance for generation. Demonstrated through extensive experiments on three popular ZSL benchmarks, our ZeroDiff not only achieves significant improvements over existing ZSL methods but also maintains robust performance even with scarce training data. Code will be released upon acceptance.
Read more6/6/2024

0
Diffusion based Zero-shot Medical Image-to-Image Translation for Cross Modality Segmentation
Zihao Wang, Yingyu Yang, Yuzhou Chen, Tingting Yuan, Maxime Sermesant, Herve Delingette, Ona Wu
Cross-modality image segmentation aims to segment the target modalities using a method designed in the source modality. Deep generative models can translate the target modality images into the source modality, thus enabling cross-modality segmentation. However, a vast body of existing cross-modality image translation methods relies on supervised learning. In this work, we aim to address the challenge of zero-shot learning-based image translation tasks (extreme scenarios in the target modality is unseen in the training phase). To leverage generative learning for zero-shot cross-modality image segmentation, we propose a novel unsupervised image translation method. The framework learns to translate the unseen source image to the target modality for image segmentation by leveraging the inherent statistical consistency between different modalities for diffusion guidance. Our framework captures identical cross-modality features in the statistical domain, offering diffusion guidance without relying on direct mappings between the source and target domains. This advantage allows our method to adapt to changing source domains without the need for retraining, making it highly practical when sufficient labeled source domain data is not available. The proposed framework is validated in zero-shot cross-modality image segmentation tasks through empirical comparisons with influential generative models, including adversarial-based and diffusion-based models.
Read more4/11/2024