Zero-shot Image Editing with Reference Imitation
2406.07547
1
0
Abstract
Image editing serves as a practical yet challenging task considering the diverse demands from users, where one of the hardest parts is to precisely describe how the edited image should look like. In this work, we present a new form of editing, termed imitative editing, to help users exercise their creativity more conveniently. Concretely, to edit an image region of interest, users are free to directly draw inspiration from some in-the-wild references (e.g., some relative pictures come across online), without having to cope with the fit between the reference and the source. Such a design requires the system to automatically figure out what to expect from the reference to perform the editing. For this purpose, we propose a generative training framework, dubbed MimicBrush, which randomly selects two frames from a video clip, masks some regions of one frame, and learns to recover the masked regions using the information from the other frame. That way, our model, developed from a diffusion prior, is able to capture the semantic correspondence between separate images in a self-supervised manner. We experimentally show the effectiveness of our method under various test cases as well as its superiority over existing alternatives. We also construct a benchmark to facilitate further research.
Create account to get full access
Overview
- This paper introduces a novel approach for zero-shot image editing using reference imitation.
- The method allows users to edit images by providing a reference image that illustrates the desired editing effect, rather than relying on complex instructions or manual adjustments.
- The system is able to learn the editing operations from the reference image and apply them to the target image in a zero-shot manner, without any additional training.
Plain English Explanation
The research paper presents a new way to edit images without needing special training or complex instructions. Typically, when you want to edit an image, you might have to follow detailed steps or use specialized software. This new method is different - instead of complicated instructions, you can simply provide a reference image that shows the kind of edits you want to make.
The system learns from the reference image and then applies those edits to your target image. So it's like you're imitating the changes made in the reference image. This "zero-shot" approach means the system doesn't need any additional training - it can figure out how to do the edits just from the reference you provide.
The key advantage is that it's much more intuitive and accessible for regular users, who may not be experts in photo editing software. By using a visual reference as a guide, the system can make the desired changes without the user having to manually edit the image themselves. This could be helpful for tasks like retouching photos, adding special effects, or even making consistent edits across a series of images.
Technical Explanation
The paper introduces a novel image editing framework called Zero-shot Image Editing with Reference Imitation (ZEIR). The core idea is to leverage a reference image that illustrates the desired editing effect, and use it to guide the editing of a target image in a zero-shot manner.
The ZEIR architecture consists of three main components:
- Reference Encoder: This module encodes the reference image into a latent representation that captures the editing operations.
- Target Encoder: This module encodes the target image that the user wants to edit.
- Editing Transformer: This module takes the latent representations from the reference and target encoders, and applies the inferred editing operations to the target image.
The key innovation is that the system can perform the desired image edits without any additional training or fine-tuning, simply by imitating the reference image. This "zero-shot" capability is enabled by the Editing Transformer, which learns to map the latent representations of the reference and target images to the appropriate editing operations.
The authors evaluate ZEIR on a variety of image editing tasks, including photo retouching, style transfer, and object manipulation. The results demonstrate that ZEIR can achieve high-quality editing results that are on par with or even surpass those produced by supervised methods.
Critical Analysis
The ZEIR approach represents a promising step towards more intuitive and accessible image editing tools. By allowing users to provide a visual reference as guidance, it avoids the need for complex instructions or manual adjustments, which can be a significant barrier for non-expert users.
However, the paper does acknowledge some limitations of the current approach. For example, the system may struggle with highly complex or unusual editing operations that are not well-represented in the training data. There is also the potential for unintended biases or artifacts to be introduced if the reference images used are not carefully curated.
Additionally, while the zero-shot capability is a notable strength, it may come at the cost of reduced flexibility or control compared to more traditional editing tools. Users may have less fine-grained control over the individual editing operations applied to the image.
Future research could explore ways to further expand the range of supported editing operations, perhaps by incorporating more advanced techniques like disrupting style mimicry attacks or learnable regions. Addressing these challenges could help make ZEIR and similar approaches even more powerful and versatile for a wide range of image editing tasks.
Conclusion
The Zero-shot Image Editing with Reference Imitation (ZEIR) approach presented in this paper offers a novel and promising solution for more intuitive and accessible image editing. By allowing users to guide the editing process using a reference image, rather than relying on complex instructions or manual adjustments, ZEIR represents a significant step forward in making sophisticated image editing capabilities available to a broader audience.
While the current implementation has some limitations, the underlying concept of leveraging visual references to drive zero-shot editing operations holds great potential. As the field of AI-powered image editing continues to evolve, approaches like ZEIR could play a key role in democratizing access to powerful creative tools and enabling more people to express their artistic vision through digital imagery.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Disrupting Style Mimicry Attacks on Video Imagery
Josephine Passananti, Stanley Wu, Shawn Shan, Haitao Zheng, Ben Y. Zhao
0
0
Generative AI models are often used to perform mimicry attacks, where a pretrained model is fine-tuned on a small sample of images to learn to mimic a specific artist of interest. While researchers have introduced multiple anti-mimicry protection tools (Mist, Glaze, Anti-Dreambooth), recent evidence points to a growing trend of mimicry models using videos as sources of training data. This paper presents our experiences exploring techniques to disrupt style mimicry on video imagery. We first validate that mimicry attacks can succeed by training on individual frames extracted from videos. We show that while anti-mimicry tools can offer protection when applied to individual frames, this approach is vulnerable to an adaptive countermeasure that removes protection by exploiting randomness in optimization results of consecutive (nearly-identical) frames. We develop a new, tool-agnostic framework that segments videos into short scenes based on frame-level similarity, and use a per-scene optimization baseline to remove inter-frame randomization while reducing computational cost. We show via both image level metrics and an end-to-end user study that the resulting protection restores protection against mimicry (including the countermeasure). Finally, we develop another adaptive countermeasure and find that it falls short against our framework.
5/14/2024
🖼️
Text-Driven Image Editing via Learnable Regions
Yuanze Lin, Yi-Wen Chen, Yi-Hsuan Tsai, Lu Jiang, Ming-Hsuan Yang
0
0
Language has emerged as a natural interface for image editing. In this paper, we introduce a method for region-based image editing driven by textual prompts, without the need for user-provided masks or sketches. Specifically, our approach leverages an existing pre-trained text-to-image model and introduces a bounding box generator to identify the editing regions that are aligned with the textual prompts. We show that this simple approach enables flexible editing that is compatible with current image generation models, and is able to handle complex prompts featuring multiple objects, complex sentences, or lengthy paragraphs. We conduct an extensive user study to compare our method against state-of-the-art methods. The experiments demonstrate the competitive performance of our method in manipulating images with high fidelity and realism that correspond to the provided language descriptions. Our project webpage can be found at: https://yuanze-lin.me/LearnableRegions_page.
4/4/2024
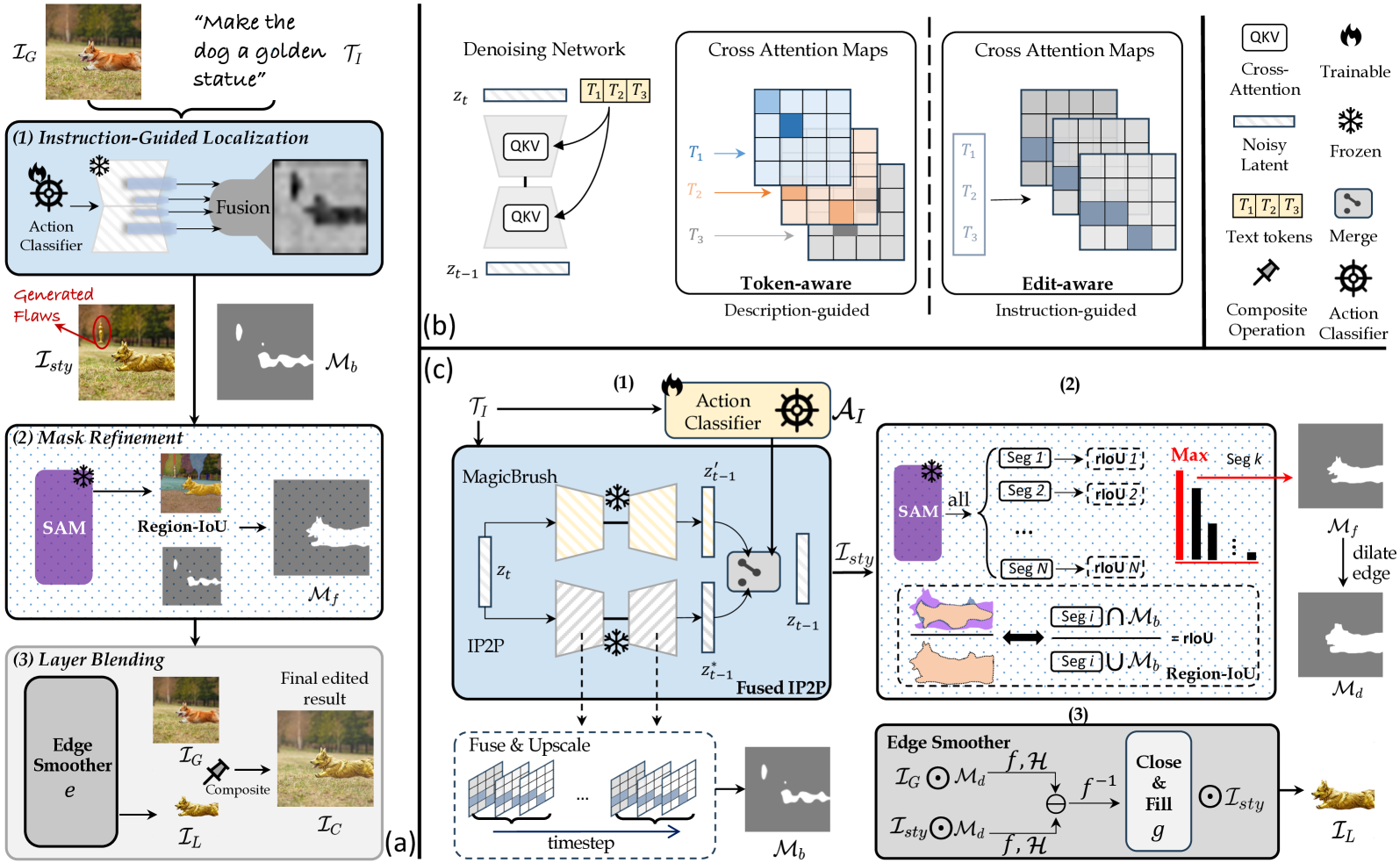
ZONE: Zero-Shot Instruction-Guided Local Editing
Shanglin Li, Bohan Zeng, Yutang Feng, Sicheng Gao, Xuhui Liu, Jiaming Liu, Li Lin, Xu Tang, Yao Hu, Jianzhuang Liu, Baochang Zhang
0
0
Recent advances in vision-language models like Stable Diffusion have shown remarkable power in creative image synthesis and editing.However, most existing text-to-image editing methods encounter two obstacles: First, the text prompt needs to be carefully crafted to achieve good results, which is not intuitive or user-friendly. Second, they are insensitive to local edits and can irreversibly affect non-edited regions, leaving obvious editing traces. To tackle these problems, we propose a Zero-shot instructiON-guided local image Editing approach, termed ZONE. We first convert the editing intent from the user-provided instruction (e.g., make his tie blue) into specific image editing regions through InstructPix2Pix. We then propose a Region-IoU scheme for precise image layer extraction from an off-the-shelf segment model. We further develop an edge smoother based on FFT for seamless blending between the layer and the image.Our method allows for arbitrary manipulation of a specific region with a single instruction while preserving the rest. Extensive experiments demonstrate that our ZONE achieves remarkable local editing results and user-friendliness, outperforming state-of-the-art methods. Code is available at https://github.com/lsl001006/ZONE.
4/15/2024

I2VEdit: First-Frame-Guided Video Editing via Image-to-Video Diffusion Models
Wenqi Ouyang, Yi Dong, Lei Yang, Jianlou Si, Xingang Pan
0
0
The remarkable generative capabilities of diffusion models have motivated extensive research in both image and video editing. Compared to video editing which faces additional challenges in the time dimension, image editing has witnessed the development of more diverse, high-quality approaches and more capable software like Photoshop. In light of this gap, we introduce a novel and generic solution that extends the applicability of image editing tools to videos by propagating edits from a single frame to the entire video using a pre-trained image-to-video model. Our method, dubbed I2VEdit, adaptively preserves the visual and motion integrity of the source video depending on the extent of the edits, effectively handling global edits, local edits, and moderate shape changes, which existing methods cannot fully achieve. At the core of our method are two main processes: Coarse Motion Extraction to align basic motion patterns with the original video, and Appearance Refinement for precise adjustments using fine-grained attention matching. We also incorporate a skip-interval strategy to mitigate quality degradation from auto-regressive generation across multiple video clips. Experimental results demonstrate our framework's superior performance in fine-grained video editing, proving its capability to produce high-quality, temporally consistent outputs.
5/28/2024