Zero-Shot Stance Detection using Contextual Data Generation with LLMs

0
🔎
Sign in to get full access
Overview
- This paper proposes a novel approach to zero-shot stance detection using large language models (LLMs) to generate contextual data for training.
- The method aims to overcome the challenge of limited training data for stance detection, particularly in low-resource domains.
- The authors leverage the powerful text generation capabilities of LLMs to create synthetic training samples that capture the nuances of stance expression.
Plain English Explanation
In the context of online discussions and social media, stance detection is the task of identifying an individual's position or opinion on a particular topic. However, building effective stance detection models often requires a large amount of labeled training data, which can be difficult and time-consuming to obtain, especially for niche or emerging topics.
To address this challenge, the researchers in this paper developed a novel approach that uses large language models (LLMs) - powerful AI systems trained on vast amounts of text data - to generate synthetic training samples for stance detection. The key idea is that LLMs can be prompted to produce contextual text that reflects different stances on a given topic, effectively expanding the available training data without requiring manual annotation.
By leveraging this contextual data generation technique, the researchers were able to train stance detection models that can perform well even in zero-shot settings, where no labeled training data is available for a specific topic. This represents an important advancement in the field, as it can enable stance detection in a wider range of real-world applications where labeled data is scarce.
Technical Explanation
The paper presents a zero-shot stance detection approach that leverages large language models (LLMs) to generate synthetic training data. The key components of the methodology are:
-
Data Generation: The researchers use prompting techniques to guide LLMs, such as GPT-3, to generate contextual text that reflects different stances on a given topic. This allows them to create a diverse set of training samples without the need for manual annotation.
-
Stance Classifier: The generated training data is then used to fine-tune a stance detection model, such as a transformer-based multi-modal stance detection architecture. This enables the model to learn the nuances of stance expression from the synthetic data.
-
Zero-Shot Evaluation: The trained stance detection model is evaluated on target domains where no labeled training data is available. The researchers demonstrate the model's ability to generalize and perform well in these zero-shot settings.
The researchers evaluate their approach on several stance detection benchmarks, including datasets related to social media and cross-lingual scenarios. The results show that the proposed method outperforms traditional supervised learning approaches in zero-shot settings, highlighting the effectiveness of using LLMs for data-efficient stance detection.
Critical Analysis
The paper presents a compelling approach to address the challenge of limited training data for stance detection. By leveraging the powerful text generation capabilities of LLMs, the researchers are able to create synthetic training samples that capture the nuances of stance expression, which is a significant contribution to the field.
However, the paper does not extensively discuss the potential biases that may be introduced by the LLM-generated data, which could impact the model's performance and fairness. Additionally, the evaluation is limited to a few benchmark datasets, and it would be valuable to see how the approach translates to real-world applications with more diverse and complex stance-related scenarios.
Further research could explore ways to enhance the quality and diversity of the generated training data, perhaps by incorporating additional techniques for data alignment or multi-modal information. Investigating the model's interpretability and the factors that influence its stance detection performance would also be valuable for understanding and improving the approach.
Conclusion
This paper presents a novel zero-shot stance detection method that leverages large language models to generate synthetic training data. By overcoming the limitation of scarce labeled data, the proposed approach enables effective stance detection in a wide range of real-world scenarios, including low-resource domains. The results demonstrate the potential of this data-efficient technique to advance the field of stance detection and facilitate its application in various social and political discourse analysis tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
0
Zero-Shot Stance Detection using Contextual Data Generation with LLMs
Ghazaleh Mahmoudi, Babak Behkamkia, Sauleh Eetemadi
Stance detection, the classification of attitudes expressed in a text towards a specific topic, is vital for applications like fake news detection and opinion mining. However, the scarcity of labeled data remains a challenge for this task. To address this problem, we propose Dynamic Model Adaptation with Contextual Data Generation (DyMoAdapt) that combines Few-Shot Learning and Large Language Models. In this approach, we aim to fine-tune an existing model at test time. We achieve this by generating new topic-specific data using GPT-3. This method could enhance performance by allowing the adaptation of the model to new topics. However, the results did not increase as we expected. Furthermore, we introduce the Multi Generated Topic VAST (MGT-VAST) dataset, which extends VAST using GPT-3. In this dataset, each context is associated with multiple topics, allowing the model to understand the relationship between contexts and various potential topics
Read more5/21/2024
🔎
0
Stance Detection on Social Media with Fine-Tuned Large Language Models
.Ilker Gul, R'emi Lebret, Karl Aberer
Stance detection, a key task in natural language processing, determines an author's viewpoint based on textual analysis. This study evaluates the evolution of stance detection methods, transitioning from early machine learning approaches to the groundbreaking BERT model, and eventually to modern Large Language Models (LLMs) such as ChatGPT, LLaMa-2, and Mistral-7B. While ChatGPT's closed-source nature and associated costs present challenges, the open-source models like LLaMa-2 and Mistral-7B offers an encouraging alternative. Initially, our research focused on fine-tuning ChatGPT, LLaMa-2, and Mistral-7B using several publicly available datasets. Subsequently, to provide a comprehensive comparison, we assess the performance of these models in zero-shot and few-shot learning scenarios. The results underscore the exceptional ability of LLMs in accurately detecting stance, with all tested models surpassing existing benchmarks. Notably, LLaMa-2 and Mistral-7B demonstrate remarkable efficiency and potential for stance detection, despite their smaller sizes compared to ChatGPT. This study emphasizes the potential of LLMs in stance detection and calls for more extensive research in this field.
Read more4/19/2024
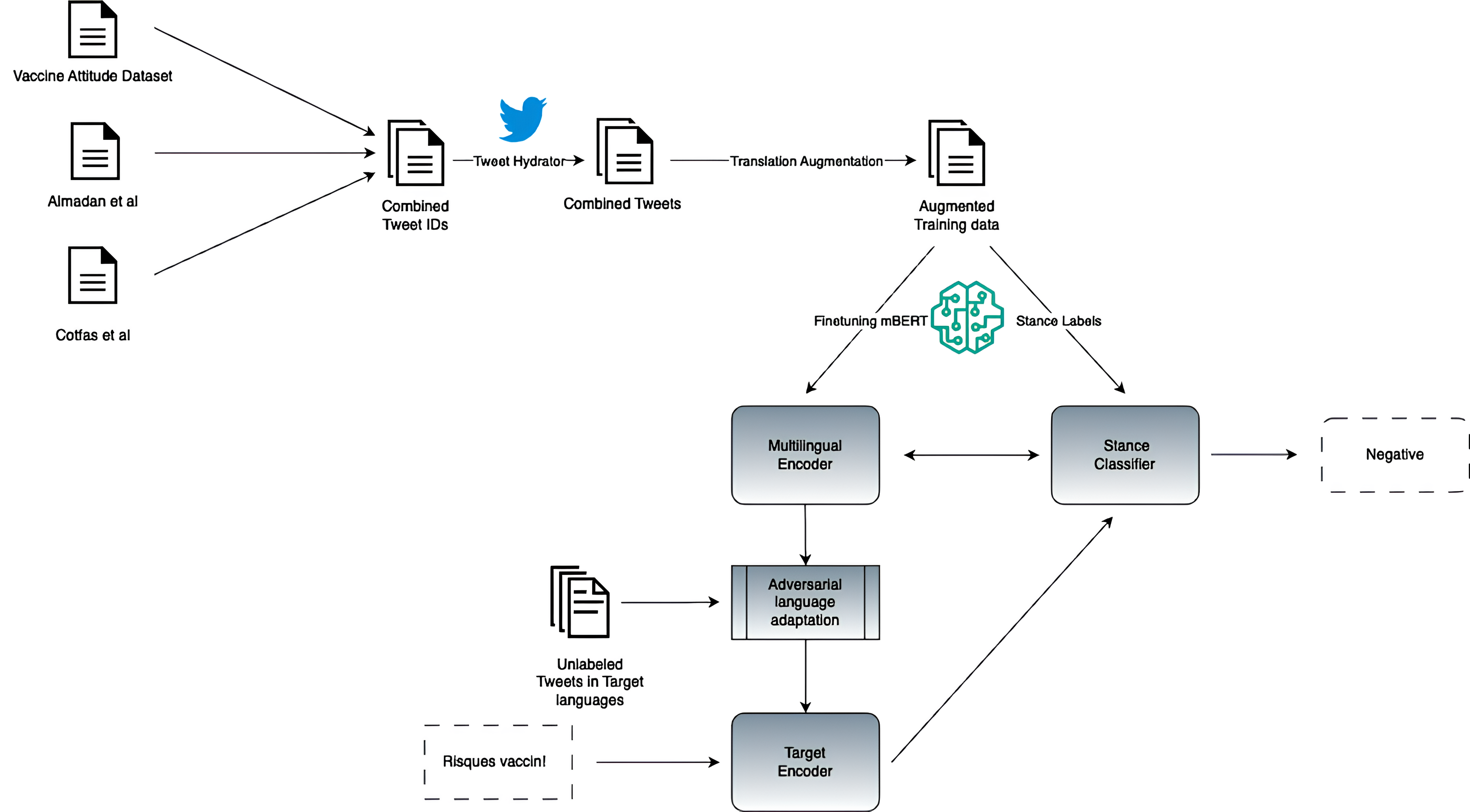
0
Zero-shot Cross-lingual Stance Detection via Adversarial Language Adaptation
Bharathi A, Arkaitz Zubiaga
Stance detection has been widely studied as the task of determining if a social media post is positive, negative or neutral towards a specific issue, such as support towards vaccines. Research in stance detection has however often been limited to a single language and, where more than one language has been studied, research has focused on few-shot settings, overlooking the challenges of developing a zero-shot cross-lingual stance detection model. This paper makes the first such effort by introducing a novel approach to zero-shot cross-lingual stance detection, Multilingual Translation-Augmented BERT (MTAB), aiming to enhance the performance of a cross-lingual classifier in the absence of explicit training data for target languages. Our technique employs translation augmentation to improve zero-shot performance and pairs it with adversarial learning to further boost model efficacy. Through experiments on datasets labeled for stance towards vaccines in four languages English, German, French, Italian. We demonstrate the effectiveness of our proposed approach, showcasing improved results in comparison to a strong baseline model as well as ablated versions of our model. Our experiments demonstrate the effectiveness of model components, not least the translation-augmented data as well as the adversarial learning component, to the improved performance of the model. We have made our source code accessible on GitHub.
Read more4/23/2024

0
The Power of LLM-Generated Synthetic Data for Stance Detection in Online Political Discussions
Stefan Sylvius Wagner, Maike Behrendt, Marc Ziegele, Stefan Harmeling
Stance detection holds great potential for enhancing the quality of online political discussions, as it has shown to be useful for summarizing discussions, detecting misinformation, and evaluating opinion distributions. Usually, transformer-based models are used directly for stance detection, which require large amounts of data. However, the broad range of debate questions in online political discussion creates a variety of possible scenarios that the model is faced with and thus makes data acquisition for model training difficult. In this work, we show how to leverage LLM-generated synthetic data to train and improve stance detection agents for online political discussions:(i) We generate synthetic data for specific debate questions by prompting a Mistral-7B model and show that fine-tuning with the generated synthetic data can substantially improve the performance of stance detection. (ii) We examine the impact of combining synthetic data with the most informative samples from an unlabelled dataset. First, we use the synthetic data to select the most informative samples, second, we combine both these samples and the synthetic data for fine-tuning. This approach reduces labelling effort and consistently surpasses the performance of the baseline model that is trained with fully labeled data. Overall, we show in comprehensive experiments that LLM-generated data greatly improves stance detection performance for online political discussions.
Read more6/19/2024