Zero-Shot Stitching in Reinforcement Learning using Relative Representations
2404.12917
0
0
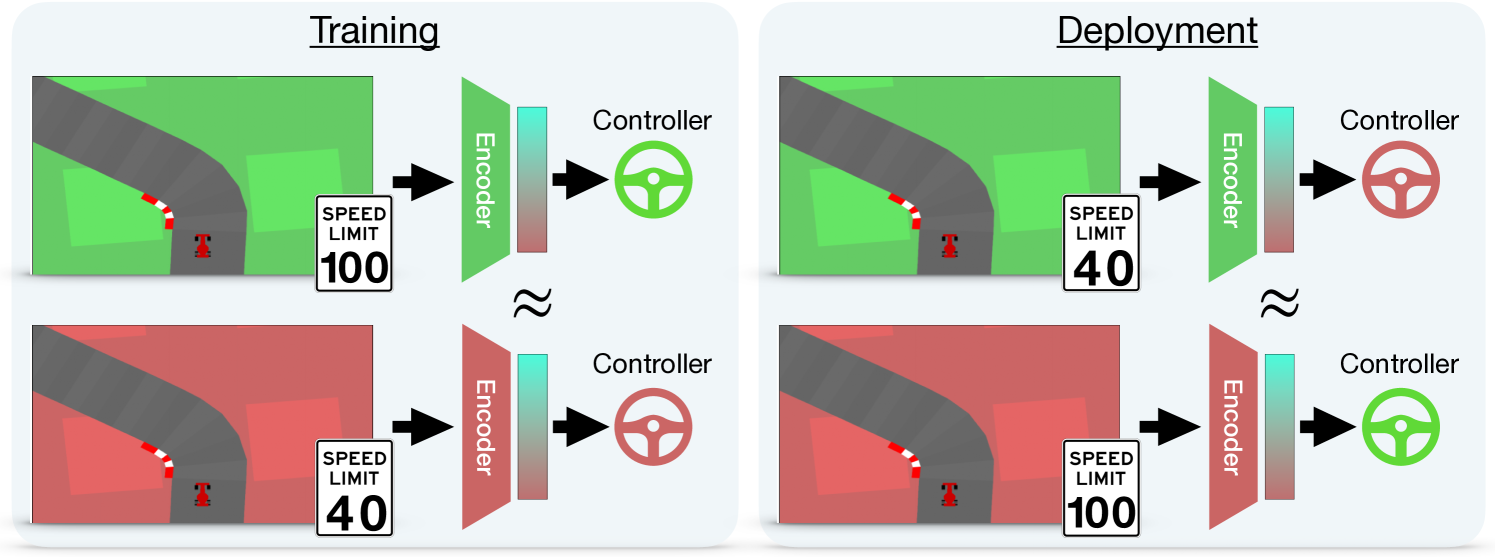
Abstract
Visual Reinforcement Learning is a popular and powerful framework that takes full advantage of the Deep Learning breakthrough. However, it is also known that variations in the input (e.g., different colors of the panorama due to the season of the year) or the task (e.g., changing the speed limit for a car to respect) could require complete retraining of the agents. In this work, we leverage recent developments in unifying latent representations to demonstrate that it is possible to combine the components of an agent, rather than retrain it from scratch. We build upon the recent relative representations framework and adapt it for Visual RL. This allows us to create completely new agents capable of handling environment-task combinations never seen during training. Our work paves the road toward a more accessible and flexible use of reinforcement learning.
Create account to get full access
Overview
- The paper introduces a novel approach for "zero-shot stitching" in reinforcement learning, which allows agents to learn and combine skills without explicit training on the combined task.
- The key idea is to use relative representations, where the agent learns to represent the environment in a way that focuses on changes and relations rather than absolute states.
- This allows the agent to more easily transfer and compose skills, rather than having to learn a completely new representation for each new task.
Plain English Explanation
The researchers have developed a new way for reinforcement learning agents to learn and combine different skills without having to be explicitly trained on the combined task. Typically, reinforcement learning agents are trained on a single specific task, and struggle to adapt that learning to new, related tasks.
The researchers' approach uses "relative representations", which means the agent learns to represent the environment in terms of the changes and relationships between different elements, rather than just memorizing the absolute states. This makes it easier for the agent to transfer what it has learned to new situations, and to combine different skills in novel ways.
For example, imagine a robot that has learned to turn on a light and to open a door. Normally, it would struggle to learn how to turn on the light and then open the door, because that's a new combined task. But with the relative representation approach, the robot can more easily learn to chain those two skills together, because it understands the relationship between turning on the light and opening the door, rather than just memorizing the specific states.
This "zero-shot stitching" capability could be very useful for building more flexible and adaptable reinforcement learning agents, that can quickly learn to handle new situations by recombining their existing skills in novel ways.
Technical Explanation
The key technical innovation in this paper is the use of relative representations for reinforcement learning. Instead of learning to represent the environment in terms of absolute states, the agent learns a representation that focuses on the changes and relations between different elements.
This is achieved through a specialized neural network architecture, where the agent maintains separate encodings for the current state and the previous state. By learning to predict the difference between these two representations, the agent develops a sense of how the environment is changing, rather than just memorizing static snapshots.
The authors demonstrate that this relative representation learning, combined with a stitching module that can compose different skills, enables zero-shot transfer to new tasks. The agent can apply its existing skills in novel combinations, without requiring any additional training on the combined task.
The authors evaluate this approach on a range of challenging reinforcement learning environments, including Recore, Inferring Behavior-Specific Context, and Robust Reinforcement Learning. They show significant improvements in zero-shot stitching performance compared to baseline approaches.
Critical Analysis
The authors have presented a compelling approach for enabling more flexible and composable reinforcement learning agents. The use of relative representations is a clever idea that could have broader applications beyond just zero-shot stitching.
However, the paper does not address some potential limitations and caveats. For example, it's unclear how well this approach would scale to extremely complex environments with a vast number of possible skills and combinations. The stitching module may struggle to handle exponentially growing combinatorial complexity.
Additionally, the paper focuses on simulated environments, and it's uncertain how well the relative representation learning would transfer to real-world robotic systems with all their inherent noise and uncertainty. Self-Training Large Language Models for improved visual understanding could be a relevant direction to explore.
Overall, this is a promising piece of research that advances the state-of-the-art in reinforcement learning generalization. Further work is needed to address the scalability and real-world applicability of the approach, but the core ideas could have a significant impact on the field.
Conclusion
In this paper, the researchers have introduced a novel approach for "zero-shot stitching" in reinforcement learning, which allows agents to learn and combine skills without explicit training on the combined task. The key innovation is the use of relative representations, where the agent learns to focus on changes and relations rather than absolute states.
This approach enables more flexible and adaptable reinforcement learning agents, that can quickly apply their existing skills in new situations by recombining them in novel ways. The authors demonstrate the effectiveness of their method on several challenging benchmarks, showing significant improvements in zero-shot stitching performance.
While the paper raises some important caveats and areas for further research, the core ideas behind relative representations and zero-shot stitching are highly promising and could have a transformative impact on the field of reinforcement learning, leading to more capable and versatile agents that can better handle the complexities of the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
Compositional Learning of Visually-Grounded Concepts Using Reinforcement
Zijun Lin, Haidi Azaman, M Ganesh Kumar, Cheston Tan
0
0
Children can rapidly generalize compositionally-constructed rules to unseen test sets. On the other hand, deep reinforcement learning (RL) agents need to be trained over millions of episodes, and their ability to generalize to unseen combinations remains unclear. Hence, we investigate the compositional abilities of RL agents, using the task of navigating to specified color-shape targets in synthetic 3D environments. First, we show that when RL agents are naively trained to navigate to target color-shape combinations, they implicitly learn to decompose the combinations, allowing them to (re-)compose these and succeed at held-out test combinations (compositional learning). Second, when agents are pretrained to learn invariant shape and color concepts (concept learning), the number of episodes subsequently needed for compositional learning decreased by 20 times. Furthermore, only agents trained on both concept and compositional learning could solve a more complex, out-of-distribution environment in zero-shot fashion. Finally, we verified that only text encoders pretrained on image-text datasets (e.g. CLIP) reduced the number of training episodes needed for our agents to demonstrate compositional learning, and also generalized to 5 unseen colors in zero-shot fashion. Overall, our results are the first to demonstrate that RL agents can be trained to implicitly learn concepts and compositionality, to solve more complex environments in zero-shot fashion.
5/6/2024
🏅
Vision-Language Models Provide Promptable Representations for Reinforcement Learning
William Chen, Oier Mees, Aviral Kumar, Sergey Levine
0
0
Humans can quickly learn new behaviors by leveraging background world knowledge. In contrast, agents trained with reinforcement learning (RL) typically learn behaviors from scratch. We thus propose a novel approach that uses the vast amounts of general and indexable world knowledge encoded in vision-language models (VLMs) pre-trained on Internet-scale data for embodied RL. We initialize policies with VLMs by using them as promptable representations: embeddings that encode semantic features of visual observations based on the VLM's internal knowledge and reasoning capabilities, as elicited through prompts that provide task context and auxiliary information. We evaluate our approach on visually-complex, long horizon RL tasks in Minecraft and robot navigation in Habitat. We find that our policies trained on embeddings from off-the-shelf, general-purpose VLMs outperform equivalent policies trained on generic, non-promptable image embeddings. We also find our approach outperforms instruction-following methods and performs comparably to domain-specific embeddings. Finally, we show that our approach can use chain-of-thought prompting to produce representations of common-sense semantic reasoning, improving policy performance in novel scenes by 1.5 times.
5/24/2024
Multi-view Disentanglement for Reinforcement Learning with Multiple Cameras
Mhairi Dunion, Stefano V. Albrecht
0
0
The performance of image-based Reinforcement Learning (RL) agents can vary depending on the position of the camera used to capture the images. Training on multiple cameras simultaneously, including a first-person egocentric camera, can leverage information from different camera perspectives to improve the performance of RL. However, hardware constraints may limit the availability of multiple cameras in real-world deployment. Additionally, cameras may become damaged in the real-world preventing access to all cameras that were used during training. To overcome these hardware constraints, we propose Multi-View Disentanglement (MVD), which uses multiple cameras to learn a policy that is robust to a reduction in the number of cameras to generalise to any single camera from the training set. Our approach is a self-supervised auxiliary task for RL that learns a disentangled representation from multiple cameras, with a shared representation that is aligned across all cameras to allow generalisation to a single camera, and a private representation that is camera-specific. We show experimentally that an RL agent trained on a single third-person camera is unable to learn an optimal policy in many control tasks; but, our approach, benefiting from multiple cameras during training, is able to solve the task using only the same single third-person camera.
6/24/2024

Learning Latent Dynamic Robust Representations for World Models
Ruixiang Sun, Hongyu Zang, Xin Li, Riashat Islam
0
0
Visual Model-Based Reinforcement Learning (MBRL) promises to encapsulate agent's knowledge about the underlying dynamics of the environment, enabling learning a world model as a useful planner. However, top MBRL agents such as Dreamer often struggle with visual pixel-based inputs in the presence of exogenous or irrelevant noise in the observation space, due to failure to capture task-specific features while filtering out irrelevant spatio-temporal details. To tackle this problem, we apply a spatio-temporal masking strategy, a bisimulation principle, combined with latent reconstruction, to capture endogenous task-specific aspects of the environment for world models, effectively eliminating non-essential information. Joint training of representations, dynamics, and policy often leads to instabilities. To further address this issue, we develop a Hybrid Recurrent State-Space Model (HRSSM) structure, enhancing state representation robustness for effective policy learning. Our empirical evaluation demonstrates significant performance improvements over existing methods in a range of visually complex control tasks such as Maniskill cite{gu2023maniskill2} with exogenous distractors from the Matterport environment. Our code is avaliable at https://github.com/bit1029public/HRSSM.
5/31/2024