Zero-Shot Video Semantic Segmentation based on Pre-Trained Diffusion Models

0

Sign in to get full access
Overview
- This paper proposes a zero-shot video semantic segmentation approach that leverages pre-trained diffusion models.
- It aims to enable video segmentation without any task-specific training, by transferring knowledge from pre-trained diffusion models.
- The method is designed to be efficient and scalable, addressing the challenges of video segmentation in the absence of labeled data.
Plain English Explanation
The researchers have developed a new way to automatically identify and label different objects and regions in video footage, without requiring any special training on that specific video data. Instead, their approach takes advantage of "diffusion models" - a type of AI model that has been pre-trained on large amounts of general visual data.
By tapping into the knowledge stored in these pre-trained diffusion models, the researchers' method can perform "zero-shot" video segmentation - meaning it can analyze and label the contents of a video, even if it has never seen that particular video before. This is a notable advance, as most video segmentation techniques require extensive training on labeled video data, which can be time-consuming and expensive to obtain.
The key innovation here is that the researchers have found a way to efficiently transfer the visual understanding encoded in pre-trained diffusion models to the task of video segmentation. This allows their approach to be both effective and scalable, opening up new possibilities for automating video analysis in a wide range of applications, from autonomous vehicles to video production and surveillance.
Technical Explanation
The paper introduces a novel zero-shot video semantic segmentation method that leverages the knowledge captured in pre-trained diffusion models. Diffusion models are a class of generative AI models that have shown impressive performance on various visual tasks, and the researchers hypothesize that the rich visual understanding encoded in these models can be effectively transferred to the video segmentation domain.
The proposed approach, dubbed Zero-Shot Video Semantic Segmentation based on Pre-Trained Diffusion Models, consists of three key components:
- Diffusion-based Video Encoding: The method encodes video frames using a pre-trained diffusion model, capturing their high-level visual representation.
- Attention-based Video Aggregation: An attention-based module aggregates the per-frame visual representations into a compact video-level feature.
- Zero-Shot Video Segmentation: The video-level feature is then used to generate pixel-level semantic segmentation masks for the input video, without any task-specific training.
The researchers evaluate their method on several video segmentation benchmarks, including Cityscapes and DAVIS, and demonstrate its effectiveness in zero-shot settings, outperforming previous state-of-the-art approaches. They also show the versatility of their method by extending it to zero-shot text-driven video segmentation, as seen in VidEdit.
The success of this work highlights the potential of leveraging pre-trained diffusion models for advancing video understanding tasks, particularly in scenarios where labeled data is scarce. The proposed approach paves the way for more efficient and scalable video analysis solutions, with potential applications in areas like medical image segmentation and zero-shot image-to-text generation.
Critical Analysis
The paper presents a compelling approach to zero-shot video semantic segmentation, demonstrating the power of transferring knowledge from pre-trained diffusion models. However, the authors acknowledge several limitations and potential areas for further research:
-
Dependence on Pre-Trained Models: The performance of the proposed method is inherently tied to the capabilities of the pre-trained diffusion models used. Improvements in the underlying diffusion models could further enhance the zero-shot segmentation results.
-
Generalization across Domains: While the method shows promising results on the evaluated benchmarks, its ability to generalize to diverse video domains and real-world scenarios remains to be thoroughly investigated.
-
Computational Efficiency: The paper does not provide a detailed analysis of the computational cost and inference time of the proposed approach, which could be an important consideration for real-time or resource-constrained applications.
-
Potential Biases: As with any AI system, the zero-shot segmentation outputs may inherit biases present in the pre-trained diffusion models, which could lead to undesirable or unfair results in certain contexts.
Further research could explore ways to address these limitations, such as by developing more robust and adaptable diffusion-based video encoding methods, investigating techniques to improve cross-domain generalization, and analyzing the computational efficiency and potential biases of the proposed approach.
Conclusion
This paper presents a innovative zero-shot video semantic segmentation method that leverages the visual understanding captured in pre-trained diffusion models. By transferring knowledge from these powerful generative AI models, the proposed approach is able to perform effective video segmentation without any task-specific training, addressing the challenge of scarce labeled video data.
The key contributions of this work include the diffusion-based video encoding, attention-based video aggregation, and the zero-shot segmentation pipeline, which collectively enable scalable and efficient video analysis. The demonstrated results on benchmark datasets showcase the potential of this approach to advance the field of video understanding and unlock new applications, such as in autonomous vehicles, video production, and medical imaging.
While the paper highlights several promising directions, further research is needed to address the identified limitations and expand the method's capabilities. Ultimately, this work represents an important step towards more accessible and versatile video analysis solutions, with broad implications for various industries and research domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Zero-Shot Video Semantic Segmentation based on Pre-Trained Diffusion Models
Qian Wang, Abdelrahman Eldesokey, Mohit Mendiratta, Fangneng Zhan, Adam Kortylewski, Christian Theobalt, Peter Wonka
We introduce the first zero-shot approach for Video Semantic Segmentation (VSS) based on pre-trained diffusion models. A growing research direction attempts to employ diffusion models to perform downstream vision tasks by exploiting their deep understanding of image semantics. Yet, the majority of these approaches have focused on image-related tasks like semantic correspondence and segmentation, with less emphasis on video tasks such as VSS. Ideally, diffusion-based image semantic segmentation approaches can be applied to videos in a frame-by-frame manner. However, we find their performance on videos to be subpar due to the absence of any modeling of temporal information inherent in the video data. To this end, we tackle this problem and introduce a framework tailored for VSS based on pre-trained image and video diffusion models. We propose building a scene context model based on the diffusion features, where the model is autoregressively updated to adapt to scene changes. This context model predicts per-frame coarse segmentation maps that are temporally consistent. To refine these maps further, we propose a correspondence-based refinement strategy that aggregates predictions temporally, resulting in more confident predictions. Finally, we introduce a masked modulation approach to upsample the coarse maps to the full resolution at a high quality. Experiments show that our proposed approach outperforms existing zero-shot image semantic segmentation approaches significantly on various VSS benchmarks without any training or fine-tuning. Moreover, it rivals supervised VSS approaches on the VSPW dataset despite not being explicitly trained for VSS.
Read more5/28/2024
🤷
0
Diffuse, Attend, and Segment: Unsupervised Zero-Shot Segmentation using Stable Diffusion
Junjiao Tian, Lavisha Aggarwal, Andrea Colaco, Zsolt Kira, Mar Gonzalez-Franco
Producing quality segmentation masks for images is a fundamental problem in computer vision. Recent research has explored large-scale supervised training to enable zero-shot segmentation on virtually any image style and unsupervised training to enable segmentation without dense annotations. However, constructing a model capable of segmenting anything in a zero-shot manner without any annotations is still challenging. In this paper, we propose to utilize the self-attention layers in stable diffusion models to achieve this goal because the pre-trained stable diffusion model has learned inherent concepts of objects within its attention layers. Specifically, we introduce a simple yet effective iterative merging process based on measuring KL divergence among attention maps to merge them into valid segmentation masks. The proposed method does not require any training or language dependency to extract quality segmentation for any images. On COCO-Stuff-27, our method surpasses the prior unsupervised zero-shot SOTA method by an absolute 26% in pixel accuracy and 17% in mean IoU. The project page is at url{https://sites.google.com/view/diffseg/home}.
Read more4/3/2024
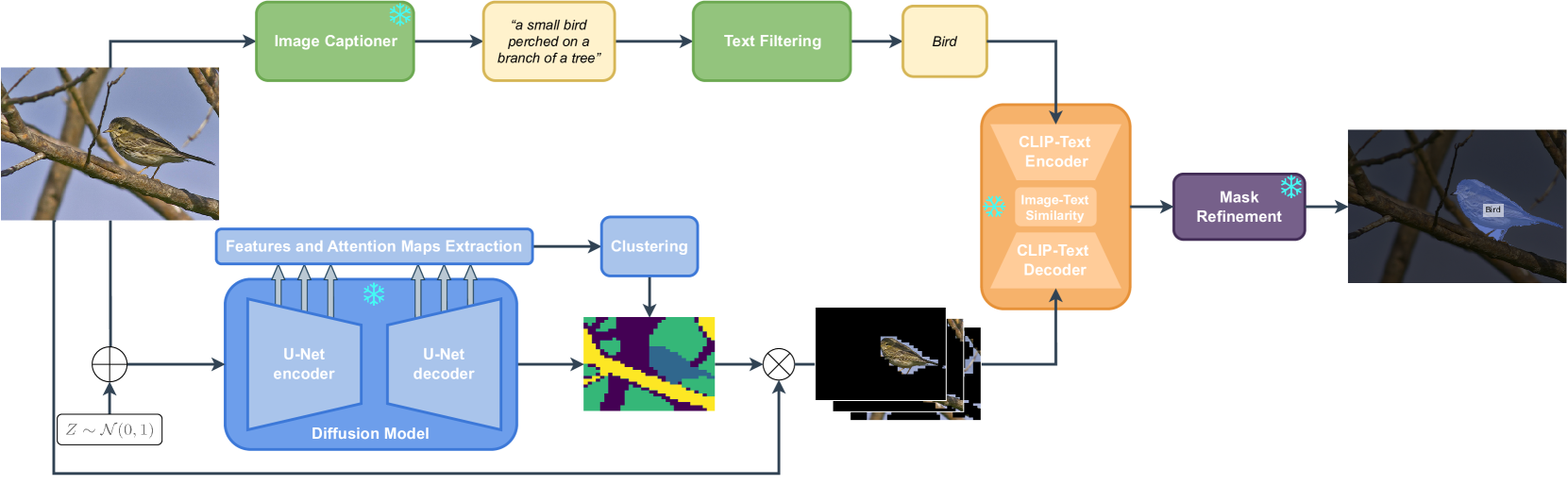
0
FreeSeg-Diff: Training-Free Open-Vocabulary Segmentation with Diffusion Models
Barbara Toniella Corradini, Mustafa Shukor, Paul Couairon, Guillaume Couairon, Franco Scarselli, Matthieu Cord
Foundation models have exhibited unprecedented capabilities in tackling many domains and tasks. Models such as CLIP are currently widely used to bridge cross-modal representations, and text-to-image diffusion models are arguably the leading models in terms of realistic image generation. Image generative models are trained on massive datasets that provide them with powerful internal spatial representations. In this work, we explore the potential benefits of such representations, beyond image generation, in particular, for dense visual prediction tasks. We focus on the task of image segmentation, which is traditionally solved by training models on closed-vocabulary datasets, with pixel-level annotations. To avoid the annotation cost or training large diffusion models, we constraint our setup to be zero-shot and training-free. In a nutshell, our pipeline leverages different and relatively small-sized, open-source foundation models for zero-shot open-vocabulary segmentation. The pipeline is as follows: the image is passed to both a captioner model (i.e. BLIP) and a diffusion model (i.e., Stable Diffusion Model) to generate a text description and visual representation, respectively. The features are clustered and binarized to obtain class agnostic masks for each object. These masks are then mapped to a textual class, using the CLIP model to support open-vocabulary. Finally, we add a refinement step that allows to obtain a more precise segmentation mask. Our approach (dubbed FreeSeg-Diff), which does not rely on any training, outperforms many training-based approaches on both Pascal VOC and COCO datasets. In addition, we show very competitive results compared to the recent weakly-supervised segmentation approaches. We provide comprehensive experiments showing the superiority of diffusion model features compared to other pretrained models. Project page: https://bcorrad.github.io/freesegdiff/
Read more4/1/2024

0
Exploring Pre-trained Text-to-Video Diffusion Models for Referring Video Object Segmentation
Zixin Zhu, Xuelu Feng, Dongdong Chen, Junsong Yuan, Chunming Qiao, Gang Hua
In this paper, we explore the visual representations produced from a pre-trained text-to-video (T2V) diffusion model for video understanding tasks. We hypothesize that the latent representation learned from a pretrained generative T2V model encapsulates rich semantics and coherent temporal correspondences, thereby naturally facilitating video understanding. Our hypothesis is validated through the classic referring video object segmentation (R-VOS) task. We introduce a novel framework, termed VD-IT, tailored with dedicatedly designed components built upon a fixed pretrained T2V model. Specifically, VD-IT uses textual information as a conditional input, ensuring semantic consistency across time for precise temporal instance matching. It further incorporates image tokens as supplementary textual inputs, enriching the feature set to generate detailed and nuanced masks. Besides, instead of using the standard Gaussian noise, we propose to predict the video-specific noise with an extra noise prediction module, which can help preserve the feature fidelity and elevates segmentation quality. Through extensive experiments, we surprisingly observe that fixed generative T2V diffusion models, unlike commonly used video backbones (e.g., Video Swin Transformer) pretrained with discriminative image/video pre-tasks, exhibit better potential to maintain semantic alignment and temporal consistency. On existing standard benchmarks, our VD-IT achieves highly competitive results, surpassing many existing state-of-the-art methods. The code is available at https://github.com/buxiangzhiren/VD-IT.
Read more7/9/2024