RVT-2: Learning Precise Manipulation from Few Demonstrations

0
Sign in to get full access
Overview
- This paper presents RVT-2, a novel approach for learning precise manipulation skills from a small number of demonstrations.
- The key idea is to use a Reversible Variational Transformer (RVT) architecture to encode the demonstrations into a compact latent representation, which can then be efficiently decoded to generate new manipulation trajectories.
- The researchers demonstrate the effectiveness of RVT-2 on a range of challenging robotic manipulation tasks, including block stacking, peg insertion, and door opening.
Plain English Explanation
The researchers have developed a new way for robots to learn precise manipulation skills by observing just a few demonstrations. Their approach, called RVT-2, uses a special type of neural network called a Reversible Variational Transformer to encode the demonstrations into a compact format. This encoded information can then be used to generate new manipulation trajectories that the robot can execute.
The key advantage of this method is that it allows robots to learn sophisticated manipulation skills from very little training data, which is important because collecting large datasets of human demonstrations can be time-consuming and expensive. By using the RVT-2 approach, the researchers showed that their robot could master challenging tasks like stacking blocks, inserting pegs, and opening doors after seeing just a few examples.
This type of efficient, data-efficient learning is a key challenge in robotics, and the RVT-2 approach represents an important step towards building robots that can rapidly acquire new skills from limited experience, just as humans and animals do.
Technical Explanation
The core of the RVT-2 approach is a Reversible Variational Transformer (RVT) architecture, which is used to encode the demonstration trajectories into a compact latent representation. This RVT encoder takes in a sequence of robot states and actions from the demonstrations and outputs a low-dimensional latent code that captures the essential features of the manipulation skill.
To generate new trajectories, the RVT decoder takes this latent code as input and uses an autoregressive procedure to sequentially predict the next robot state and action. The reversible nature of the RVT allows the gradients to flow freely between the encoder and decoder, enabling efficient end-to-end training.
The researchers evaluate RVT-2 on a variety of robotic manipulation tasks, including block stacking, peg insertion, and door opening. They show that RVT-2 can match or exceed the performance of previous state-of-the-art approaches while requiring significantly fewer demonstration examples.
Critical Analysis
One potential limitation of the RVT-2 approach is that it assumes the demonstrations are provided in the same coordinate frame and with the same initial conditions as the target task. In real-world scenarios, this may not always be the case, and the system may need to be extended to handle more variable initial conditions and coordinate frames.
Additionally, the paper does not explore the sample complexity of the RVT-2 approach in depth. While the researchers show that it outperforms previous methods with a small number of demonstrations, it would be valuable to understand how the performance scales as the number of demonstrations is further reduced, or how the approach compares to other few-shot learning techniques, such as those used for predicting point tracks from internet videos.
Overall, the RVT-2 approach represents an interesting and promising advancement in the field of data-efficient robotic manipulation learning. By leveraging the power of reversible variational transformers, the researchers have demonstrated a novel way to acquire sophisticated skills from limited experience, which could have significant implications for the development of more capable and adaptable robotic systems.
Conclusion
The RVT-2 approach presented in this paper offers a new way for robots to learn precise manipulation skills from a small number of demonstrations. By using a Reversible Variational Transformer architecture, the system can efficiently encode the essential features of the demonstration trajectories and then use this compact representation to generate new manipulation sequences.
The researchers have shown the effectiveness of RVT-2 on a range of challenging robotic tasks, highlighting its potential to enable robots to rapidly acquire new skills with limited training data. While there are some limitations that could be addressed in future work, this research represents an important step towards building more capable and adaptable robotic systems that can learn from limited experience, just as humans and animals do.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RVT-2: Learning Precise Manipulation from Few Demonstrations
Ankit Goyal, Valts Blukis, Jie Xu, Yijie Guo, Yu-Wei Chao, Dieter Fox
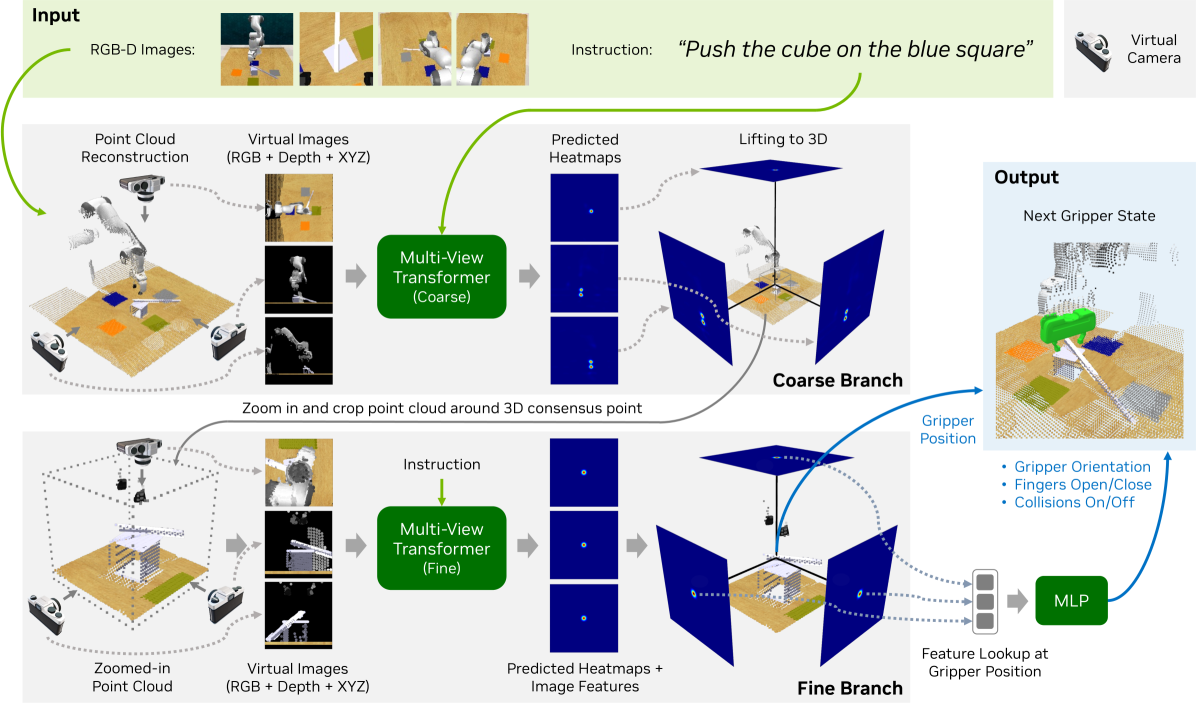
In this work, we study how to build a robotic system that can solve multiple 3D manipulation tasks given language instructions. To be useful in industrial and household domains, such a system should be capable of learning new tasks with few demonstrations and solving them precisely. Prior works, like PerAct and RVT, have studied this problem, however, they often struggle with tasks requiring high precision. We study how to make them more effective, precise, and fast. Using a combination of architectural and system-level improvements, we propose RVT-2, a multitask 3D manipulation model that is 6X faster in training and 2X faster in inference than its predecessor RVT. RVT-2 achieves a new state-of-the-art on RLBench, improving the success rate from 65% to 82%. RVT-2 is also effective in the real world, where it can learn tasks requiring high precision, like picking up and inserting plugs, with just 10 demonstrations. Visual results, code, and trained model are provided at: https://robotic-view-transformer-2.github.io/.
Read more6/14/2024
❗
0
Ag2Manip: Learning Novel Manipulation Skills with Agent-Agnostic Visual and Action Representations
Puhao Li, Tengyu Liu, Yuyang Li, Muzhi Han, Haoran Geng, Shu Wang, Yixin Zhu, Song-Chun Zhu, Siyuan Huang
Autonomous robotic systems capable of learning novel manipulation tasks are poised to transform industries from manufacturing to service automation. However, modern methods (e.g., VIP and R3M) still face significant hurdles, notably the domain gap among robotic embodiments and the sparsity of successful task executions within specific action spaces, resulting in misaligned and ambiguous task representations. We introduce Ag2Manip (Agent-Agnostic representations for Manipulation), a framework aimed at surmounting these challenges through two key innovations: a novel agent-agnostic visual representation derived from human manipulation videos, with the specifics of embodiments obscured to enhance generalizability; and an agent-agnostic action representation abstracting a robot's kinematics to a universal agent proxy, emphasizing crucial interactions between end-effector and object. Ag2Manip's empirical validation across simulated benchmarks like FrankaKitchen, ManiSkill, and PartManip shows a 325% increase in performance, achieved without domain-specific demonstrations. Ablation studies underline the essential contributions of the visual and action representations to this success. Extending our evaluations to the real world, Ag2Manip significantly improves imitation learning success rates from 50% to 77.5%, demonstrating its effectiveness and generalizability across both simulated and physical environments.
Read more4/29/2024

0
3D-MVP: 3D Multiview Pretraining for Robotic Manipulation
Shengyi Qian, Kaichun Mo, Valts Blukis, David F. Fouhey, Dieter Fox, Ankit Goyal
Recent works have shown that visual pretraining on egocentric datasets using masked autoencoders (MAE) can improve generalization for downstream robotics tasks. However, these approaches pretrain only on 2D images, while many robotics applications require 3D scene understanding. In this work, we propose 3D-MVP, a novel approach for 3D multi-view pretraining using masked autoencoders. We leverage Robotic View Transformer (RVT), which uses a multi-view transformer to understand the 3D scene and predict gripper pose actions. We split RVT's multi-view transformer into visual encoder and action decoder, and pretrain its visual encoder using masked autoencoding on large-scale 3D datasets such as Objaverse. We evaluate 3D-MVP on a suite of virtual robot manipulation tasks and demonstrate improved performance over baselines. We also show promising results on a real robot platform with minimal finetuning. Our results suggest that 3D-aware pretraining is a promising approach to improve sample efficiency and generalization of vision-based robotic manipulation policies. We will release code and pretrained models for 3D-MVP to facilitate future research. Project site: https://jasonqsy.github.io/3DMVP
Read more6/27/2024
📉
0
MoDem-V2: Visuo-Motor World Models for Real-World Robot Manipulation
Patrick Lancaster, Nicklas Hansen, Aravind Rajeswaran, Vikash Kumar
Robotic systems that aspire to operate in uninstrumented real-world environments must perceive the world directly via onboard sensing. Vision-based learning systems aim to eliminate the need for environment instrumentation by building an implicit understanding of the world based on raw pixels, but navigating the contact-rich high-dimensional search space from solely sparse visual reward signals significantly exacerbates the challenge of exploration. The applicability of such systems is thus typically restricted to simulated or heavily engineered environments since agent exploration in the real-world without the guidance of explicit state estimation and dense rewards can lead to unsafe behavior and safety faults that are catastrophic. In this study, we isolate the root causes behind these limitations to develop a system, called MoDem-V2, capable of learning contact-rich manipulation directly in the uninstrumented real world. Building on the latest algorithmic advancements in model-based reinforcement learning (MBRL), demo-bootstrapping, and effective exploration, MoDem-V2 can acquire contact-rich dexterous manipulation skills directly in the real world. We identify key ingredients for leveraging demonstrations in model learning while respecting real-world safety considerations -- exploration centering, agency handover, and actor-critic ensembles. We empirically demonstrate the contribution of these ingredients in four complex visuo-motor manipulation problems in both simulation and the real world. To the best of our knowledge, our work presents the first successful system for demonstration-augmented visual MBRL trained directly in the real world. Visit https://sites.google.com/view/modem-v2 for videos and more details.
Read more5/14/2024