Accelerated Optimization Landscape of Linear-Quadratic Regulator
2307.03590
0
0

Abstract
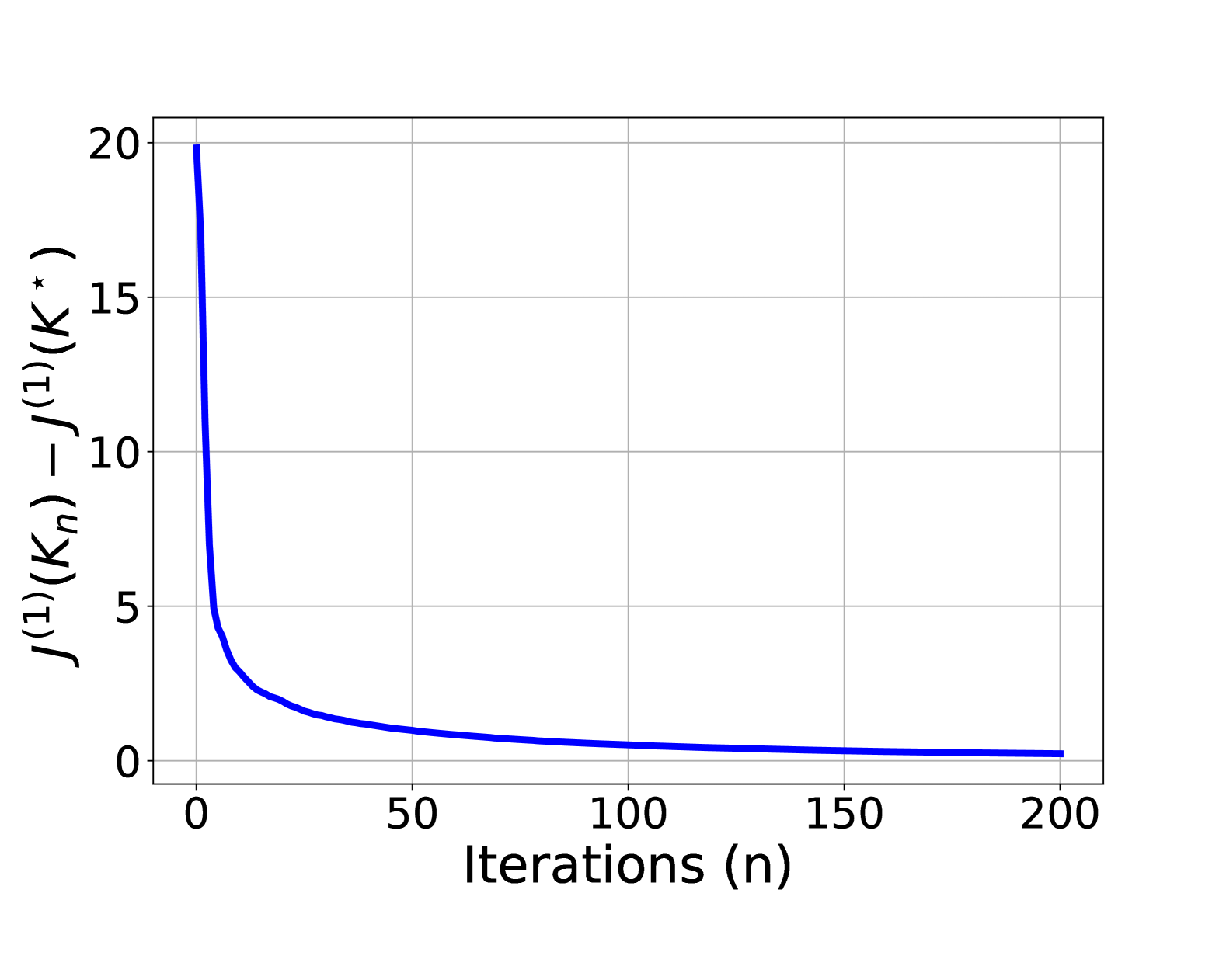
Linear-quadratic regulator (LQR) is a landmark problem in the field of optimal control, which is the concern of this paper. Generally, LQR is classified into state-feedback LQR (SLQR) and output-feedback LQR (OLQR) based on whether the full state is obtained. It has been suggested in existing literature that both SLQR and OLQR could be viewed as textit{constrained nonconvex matrix optimization} problems in which the only variable to be optimized is the feedback gain matrix. In this paper, we introduce a first-order accelerated optimization framework of handling the LQR problem, and give its convergence analysis for the cases of SLQR and OLQR, respectively. Specifically, a Lipschiz Hessian property of LQR performance criterion is presented, which turns out to be a crucial property for the application of modern optimization techniques. For the SLQR problem, a continuous-time hybrid dynamic system is introduced, whose solution trajectory is shown to converge exponentially to the optimal feedback gain with Nesterov-optimal order $1-frac{1}{sqrt{kappa}}$ ($kappa$ the condition number). Then, the symplectic Euler scheme is utilized to discretize the hybrid dynamic system, and a Nesterov-type method with a restarting rule is proposed that preserves the continuous-time convergence rate, i.e., the discretized algorithm admits the Nesterov-optimal convergence order. For the OLQR problem, a Hessian-free accelerated framework is proposed, which is a two-procedure method consisting of semiconvex function optimization and negative curvature exploitation. In a time $mathcal{O}(epsilon^{-7/4}log(1/epsilon))$, the method can find an $epsilon$-stationary point of the performance criterion; this entails that the method improves upon the $mathcal{O}(epsilon^{-2})$ complexity of vanilla gradient descent. Moreover, our method provides the second-order guarantee of stationary point.
Create account to get full access
Overview
- This paper explores the optimization landscape of the Linear-Quadratic Regulator (LQR), a fundamental control theory problem.
- The authors present an accelerated optimization algorithm that can efficiently find the globally optimal solution for LQR problems.
- The algorithm leverages insights into the structure of the LQR optimization landscape to achieve faster convergence compared to traditional methods.
Plain English Explanation
The Linear-Quadratic Regulator (LQR) is a widely used control theory technique for designing optimal controllers. It involves finding the best way to control a linear system (e.g., a robot, a vehicle, or a chemical process) to minimize a quadratic cost function. This is an important problem in fields like robotics, aerospace engineering, and industrial automation.
The authors of this paper have developed a new optimization algorithm that can quickly and reliably find the globally optimal solution for LQR problems. Their key insight is that the LQR optimization landscape has a specific structure that can be exploited to accelerate the optimization process. By taking advantage of this structure, their algorithm converges to the optimal solution much faster than traditional methods.
This is significant because finding the optimal LQR controller is a computationally challenging task, especially for large-scale systems. The authors' algorithm makes it possible to solve these problems more efficiently, which could lead to improved performance and energy savings in real-world control systems.
Technical Explanation
The authors propose an "Accelerated Optimization Landscape" (AOL) algorithm for solving LQR problems. The key idea is to leverage the specific structure of the LQR optimization landscape to achieve faster convergence to the global optimum.
Specifically, the authors show that the LQR optimization landscape is a convex quadratic function with a unique global minimum. They exploit this property by using an accelerated gradient descent method that takes advantage of the landscape's curvature information. This allows the algorithm to converge much faster than standard gradient-based optimization techniques.
The authors provide theoretical analysis to characterize the convergence rate of the AOL algorithm. They prove that it achieves a linear convergence rate, which is significantly faster than the sublinear rates of traditional methods. The authors also validate the performance of their algorithm through numerical simulations on various LQR benchmark problems.
Critical Analysis
The authors have provided a thorough theoretical analysis of their proposed AOL algorithm, including convergence rate guarantees. This is a strength of the paper, as it gives the reader confidence in the algorithm's correctness and efficiency.
However, the paper does not discuss the practical implementation of the algorithm or how it would scale to large-scale, real-world LQR problems. The numerical experiments are limited to relatively small-scale examples, and the authors do not address potential challenges that might arise when applying the algorithm to more complex control systems.
Additionally, the authors do not compare the performance of their AOL algorithm to other state-of-the-art methods for solving LQR problems, such as primal-dual iLQR, learning-based LQR, or receding horizon control approaches. A more comprehensive benchmarking analysis would help demonstrate the relative advantages of the AOL algorithm.
Conclusion
This paper presents an accelerated optimization algorithm for solving the Linear-Quadratic Regulator (LQR) problem, a fundamental control theory problem with applications in robotics, aerospace, and industrial automation. The authors' key insight is to exploit the specific structure of the LQR optimization landscape to achieve faster convergence to the global optimum.
The theoretical analysis and simulation results show that the proposed AOL algorithm can outperform traditional optimization methods for LQR problems. This could lead to improvements in the performance and efficiency of real-world control systems. However, the paper does not address practical implementation details or provide a comprehensive comparison to other state-of-the-art LQR optimization techniques.
Overall, this work makes a valuable contribution to the field of optimal control by introducing a novel algorithm that can solve LQR problems more efficiently. Further research is needed to assess the algorithm's scalability and practical applicability in complex, large-scale control scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
➖
Parallel and Proximal Linear-Quadratic Methods for Real-Time Constrained Model-Predictive Control
Wilson Jallet (LAAS-GEPETTO, WILLOW), Ewen Dantec (WILLOW), Etienne Arlaud (WILLOW), Justin Carpentier (WILLOW, DI-ENS), Nicolas Mansard (LAAS-GEPETTO)
0
0
Recent strides in nonlinear model predictive control (NMPC) underscore a dependence on numerical advancements to efficiently and accurately solve large-scale problems. Given the substantial number of variables characterizing typical whole-body optimal control (OC) problems - often numbering in the thousands - exploiting the sparse structure of the numerical problem becomes crucial to meet computational demands, typically in the range of a few milliseconds. Addressing the linear-quadratic regulator (LQR) problem is a fundamental building block for computing Newton or Sequential Quadratic Programming (SQP) steps in direct optimal control methods. This paper concentrates on equality-constrained problems featuring implicit system dynamics and dual regularization, a characteristic of advanced interiorpoint or augmented Lagrangian solvers. Here, we introduce a parallel algorithm for solving an LQR problem with dual regularization. Leveraging a rewriting of the LQR recursion through block elimination, we first enhanced the efficiency of the serial algorithm and then subsequently generalized it to handle parametric problems. This extension enables us to split decision variables and solve multiple subproblems concurrently. Our algorithm is implemented in our nonlinear numerical optimal control library ALIGATOR. It showcases improved performance over previous serial formulations and we validate its efficacy by deploying it in the model predictive control of a real quadruped robot.
6/4/2024
🏅
Sample Complexity of the Linear Quadratic Regulator: A Reinforcement Learning Lens
Amirreza Neshaei Moghaddam, Alex Olshevsky, Bahman Gharesifard
0
0
We provide the first known algorithm that provably achieves $varepsilon$-optimality within $widetilde{mathcal{O}}(1/varepsilon)$ function evaluations for the discounted discrete-time LQR problem with unknown parameters, without relying on two-point gradient estimates. These estimates are known to be unrealistic in many settings, as they depend on using the exact same initialization, which is to be selected randomly, for two different policies. Our results substantially improve upon the existing literature outside the realm of two-point gradient estimates, which either leads to $widetilde{mathcal{O}}(1/varepsilon^2)$ rates or heavily relies on stability assumptions.
4/22/2024
🔍
Fully Adaptive Regret-Guaranteed Algorithm for Control of Linear Quadratic Systems
Jafar Abbaszadeh Chekan, Cedric Langbort
0
0
The first algorithm for the Linear Quadratic (LQ) control problem with an unknown system model, featuring a regret of $mathcal{O}(sqrt{T})$, was introduced by Abbasi-Yadkori and Szepesv'ari (2011). Recognizing the computational complexity of this algorithm, subsequent efforts (see Cohen et al. (2019), Mania et al. (2019), Faradonbeh et al. (2020a), and Kargin et al.(2022)) have been dedicated to proposing algorithms that are computationally tractable while preserving this order of regret. Although successful, the existing works in the literature lack a fully adaptive exploration-exploitation trade-off adjustment and require a user-defined value, which can lead to overall regret bound growth with some factors. In this work, noticing this gap, we propose the first fully adaptive algorithm that controls the number of policy updates (i.e., tunes the exploration-exploitation trade-off) and optimizes the upper-bound of regret adaptively. Our proposed algorithm builds on the SDP-based approach of Cohen et al. (2019) and relaxes its need for a horizon-dependant warm-up phase by appropriately tuning the regularization parameter and adding an adaptive input perturbation. We further show that through careful exploration-exploitation trade-off adjustment there is no need to commit to the widely-used notion of strong sequential stability, which is restrictive and can introduce complexities in initialization.
6/13/2024
Meta-Learning Linear Quadratic Regulators: A Policy Gradient MAML Approach for Model-free LQR
Leonardo F. Toso, Donglin Zhan, James Anderson, Han Wang
0
0
We investigate the problem of learning linear quadratic regulators (LQR) in a multi-task, heterogeneous, and model-free setting. We characterize the stability and personalization guarantees of a policy gradient-based (PG) model-agnostic meta-learning (MAML) (Finn et al., 2017) approach for the LQR problem under different task-heterogeneity settings. We show that our MAML-LQR algorithm produces a stabilizing controller close to each task-specific optimal controller up to a task-heterogeneity bias in both model-based and model-free learning scenarios. Moreover, in the model-based setting, we show that such a controller is achieved with a linear convergence rate, which improves upon sub-linear rates from existing work. Our theoretical guarantees demonstrate that the learned controller can efficiently adapt to unseen LQR tasks.
6/4/2024