Accent Conversion with Articulatory Representations

0

Sign in to get full access
Overview
- This paper presents a method for converting speech accents using articulatory representations, which describe how speech sounds are produced in the vocal tract.
- The researchers developed a model that can convert speech from one accent to another by manipulating the articulatory representations of the input speech.
- This approach aims to improve the naturalness and intelligibility of accent conversion for text-to-speech applications.
Plain English Explanation
The paper describes a new way to change the accent of speech. Instead of just changing the sounds of the words, the researchers used a more detailed representation of how the speech is produced in the mouth and throat. This articulatory representation allows the model to make more natural-sounding changes to the accent.
For example, accent conversion model might change the way certain vowels are pronounced to shift the accent, rather than just substituting one sound for another. The non-autoregressive model can also do this in real-time, which is useful for applications like speech synthesis or language modeling.
Overall, this approach aims to create more natural-sounding accent changes, which could improve the experience of text-to-speech systems that need to adapt to different accents.
Technical Explanation
The researchers developed a model that can convert speech from one accent to another by manipulating the articulatory representations of the input speech. Articulatory representations describe how speech sounds are produced in the vocal tract, including the positions and movements of the tongue, lips, and other speech organs.
The model takes the acoustic features of the input speech, along with the target accent information, and generates the corresponding articulatory representations. It then uses these articulatory representations to synthesize the speech in the target accent. This approach allows the model to make more nuanced changes to the accent, compared to simply substituting one sound for another.
The researchers evaluated their model on several accent conversion tasks, including converting American English to British English and vice versa. They found that their approach outperformed previous methods in terms of naturalness and intelligibility of the converted speech.
Critical Analysis
The paper presents a promising approach to accent conversion, but there are a few caveats to consider. First, the model was trained and evaluated on a relatively small dataset of English accents, so its performance on a wider range of accents is unclear. Additionally, the paper does not address potential issues with bias or fairness, such as whether the model performs equally well on different demographic groups.
Another potential limitation is the reliance on articulatory representations, which can be difficult to obtain and may not be available for all languages or speakers. The researchers note that developing efficient ways to estimate articulatory representations from acoustic features is an important area for future research.
Overall, the work represents a valuable contribution to the field of accent conversion, but further research is needed to address these limitations and explore the broader implications of this approach.
Conclusion
This paper presents a novel method for converting speech accents using articulatory representations. By modeling the detailed movements of the speech organs, the researchers were able to create more natural-sounding accent changes compared to previous approaches.
The potential applications of this work include improving the user experience of text-to-speech systems, which often need to adapt to different regional or demographic accents. Additionally, the ability to manipulate articulatory representations could have broader implications for speech synthesis and language modeling tasks.
While the paper presents promising results, further research is needed to address the limitations and explore the wider applicability of this approach. Developing more efficient methods for estimating articulatory representations and evaluating the model on a broader range of accents and languages will be important next steps.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Accent Conversion with Articulatory Representations
Yashish M. Siriwardena, Nathan Swedlow, Audrey Howard, Evan Gitterman, Dan Darcy, Carol Espy-Wilson, Andrea Fanelli
Conversion of non-native accented speech to native (American) English has a wide range of applications such as improving intelligibility of non-native speech. Previous work on this domain has used phonetic posteriograms as the target speech representation to train an acoustic model which is then used to extract a compact representation of input speech for accent conversion. In this work, we introduce the idea of using an effective articulatory speech representation, extracted from an acoustic-to-articulatory speech inversion system, to improve the acoustic model used in accent conversion. The idea to incorporate articulatory representations originates from their ability to well characterize accents in speech. To incorporate articulatory representations with conventional phonetic posteriograms, a multi-task learning based acoustic model is proposed. Objective and subjective evaluations show that the use of articulatory representations can improve the effectiveness of accent conversion.
Read more6/11/2024

0
Decoding Vocal Articulations from Acoustic Latent Representations
Mateo C'amara, Fernando Marcos, Jos'e Luis Blanco
We present a novel neural encoder system for acoustic-to-articulatory inversion. We leverage the Pink Trombone voice synthesizer that reveals articulatory parameters (e.g tongue position and vocal cord configuration). Our system is designed to identify the articulatory features responsible for producing specific acoustic characteristics contained in a neural latent representation. To generate the necessary latent embeddings, we employed two main methodologies. The first was a self-supervised variational autoencoder trained from scratch to reconstruct the input signal at the decoder stage. We conditioned its bottleneck layer with a subnetwork called the projector, which decodes the voice synthesizer's parameters. The second methodology utilized two pretrained models: EnCodec and Wav2Vec. They eliminate the need to train the encoding process from scratch, allowing us to focus on training the projector network. This approach aimed to explore the potential of these existing models in the context of acoustic-to-articulatory inversion. By reusing the pretrained models, we significantly simplified the data processing pipeline, increasing efficiency and reducing computational overhead. The primary goal of our project was to demonstrate that these neural architectures can effectively encapsulate both acoustic and articulatory features. This prediction-based approach is much faster than traditional methods focused on acoustic feature-based parameter optimization. We validated our models by predicting six different parameters and evaluating them with objective and ViSQOL subjective-equivalent metric using both synthesizer- and human-generated sounds. The results show that the predicted parameters can generate human-like vowel sounds when input into the synthesizer. We provide the dataset, code, and detailed findings to support future research in this field.
Read more6/21/2024

0
Accent Conversion in Text-To-Speech Using Multi-Level VAE and Adversarial Training
Jan Melechovsky, Ambuj Mehrish, Berrak Sisman, Dorien Herremans
With rapid globalization, the need to build inclusive and representative speech technology cannot be overstated. Accent is an important aspect of speech that needs to be taken into consideration while building inclusive speech synthesizers. Inclusive speech technology aims to erase any biases towards specific groups, such as people of certain accent. We note that state-of-the-art Text-to-Speech (TTS) systems may currently not be suitable for all people, regardless of their background, as they are designed to generate high-quality voices without focusing on accent. In this paper, we propose a TTS model that utilizes a Multi-Level Variational Autoencoder with adversarial learning to address accented speech synthesis and conversion in TTS, with a vision for more inclusive systems in the future. We evaluate the performance through both objective metrics and subjective listening tests. The results show an improvement in accent conversion ability compared to the baseline.
Read more6/4/2024
0
Convert and Speak: Zero-shot Accent Conversion with Minimum Supervision
Zhijun Jia, Huaying Xue, Xiulian Peng, Yan Lu
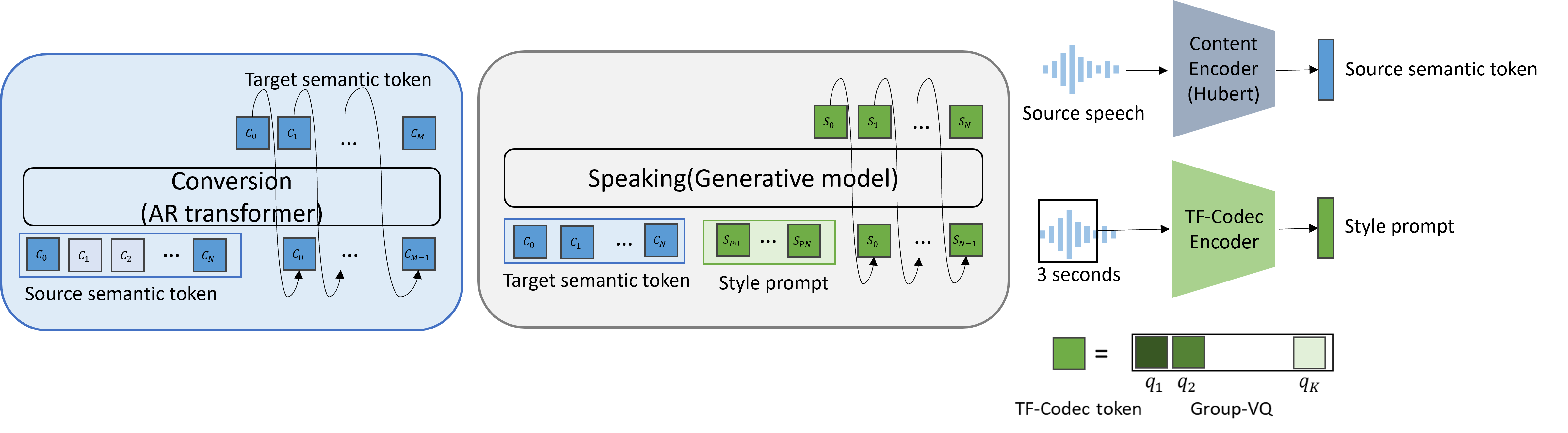
Low resource of parallel data is the key challenge of accent conversion(AC) problem in which both the pronunciation units and prosody pattern need to be converted. We propose a two-stage generative framework convert-and-speak in which the conversion is only operated on the semantic token level and the speech is synthesized conditioned on the converted semantic token with a speech generative model in target accent domain. The decoupling design enables the speaking module to use massive amount of target accent speech and relieves the parallel data required for the conversion module. Conversion with the bridge of semantic token also relieves the requirement for the data with text transcriptions and unlocks the usage of language pre-training technology to further efficiently reduce the need of parallel accent speech data. To reduce the complexity and latency of speaking, a single-stage AR generative model is designed to achieve good quality as well as lower computation cost. Experiments on Indian-English to general American-English conversion show that the proposed framework achieves state-of-the-art performance in accent similarity, speech quality, and speaker maintenance with only 15 minutes of weakly parallel data which is not constrained to the same speaker. Extensive experimentation with diverse accent types suggests that this framework possesses a high degree of adaptability, making it readily scalable to accommodate other accents with low-resource data. Audio samples are available at https://www.microsoft.com/en-us/research/project/convert-and-speak-zero-shot-accent-conversion-with-minimumsupervision/.
Read more8/23/2024