Decoding Vocal Articulations from Acoustic Latent Representations

0

Sign in to get full access
Overview
- This paper investigates decoding vocal articulations, which are the movements of the tongue, lips, and other articulatory organs, from acoustic latent representations.
- The researchers develop a model that can estimate articulatory parameters from speech audio, allowing for applications in areas like accent conversion, speech synthesis for dysarthric speakers, and accented text-to-speech.
- The model is trained on a dataset of speech audio paired with electromagnetic articulography (EMA) data, which tracks the motion of the articulators during speech.
Plain English Explanation
When we speak, our vocal organs like the tongue, lips, and throat move in complex ways to produce different sounds. This paper looks at a way to estimate the movements of these vocal organs from just the audio of someone's speech, without needing any special sensors.
The key idea is to train a machine learning model on audio data paired with measurements of how the vocal organs move during speech. This allows the model to learn the connection between the acoustic signal and the underlying articulations. Once trained, the model can then take new speech audio as input and output estimates of how the vocal organs are moving.
This could be useful for applications like helping people with speech disorders, where the model could analyze their articulations and suggest ways to improve their speech. It could also enable new speech synthesis techniques, where the model generates speech by first estimating the vocal tract movements and then converting that into audio.
Technical Explanation
The paper presents a deep learning model that can decode vocal articulations from acoustic latent representations. The model is trained on a dataset of speech audio paired with electromagnetic articulography (EMA) data, which provides ground truth measurements of how the tongue, lips, and other vocal organs move during speech production.
The model architecture consists of an encoder that maps the input speech audio to a latent representation, and a decoder that predicts the corresponding articulatory parameter trajectories from this latent code. The encoder uses convolutional and recurrent neural network layers to process the acoustic features, while the decoder employs a sequence-to-sequence model with attention to generate the articulatory outputs.
During training, the model learns to minimize the error between the predicted articulatory parameters and the ground truth EMA measurements. This allows the model to capture the complex mappings between the acoustic signal and the underlying vocal tract dynamics.
Experiments on a publicly available articulatory dataset demonstrate the model's ability to accurately reconstruct the articulatory trajectories from speech audio. The researchers also show that the learned latent representations can be leveraged for other tasks, such as accent conversion and dysarthric speech synthesis.
Critical Analysis
The paper presents a promising approach for decoding vocal articulations from speech audio, with potential applications in speech technology and rehabilitation. However, a few caveats and limitations should be considered:
-
The model's performance is heavily dependent on the quality and coverage of the training data. Real-world speech exhibits much greater variability than the controlled dataset used in the experiments, which could impact the model's generalization ability.
-
The paper does not provide a thorough analysis of the model's robustness to noisy or accented speech, which would be crucial for many practical applications.
-
While the latent representations are shown to be useful for related tasks, the paper does not explore the model's interpretability or provide insights into the specific articulatory features captured by the latent space.
-
The computational complexity and inference time of the model are not discussed, which could be an important consideration for real-time applications.
Overall, the research represents an important step towards understanding the relationship between acoustics and articulation, but further work is needed to address the limitations and expand the model's capabilities.
Conclusion
This paper presents a deep learning model that can effectively decode vocal articulations from speech audio. By training the model on paired audio and articulatory data, the researchers were able to learn the complex mapping between the acoustic signal and the underlying vocal tract dynamics.
The ability to estimate articulatory parameters from speech has many potential applications, such as improving speech synthesis for people with speech disorders, enabling new techniques for accent conversion, and enhancing text-to-speech systems to handle diverse speaking styles.
While the current model shows promising results, further research is needed to address the limitations and extend the capabilities of this technology. Continued advancements in this area could lead to significant improvements in speech-based applications and a better understanding of the human speech production process.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Decoding Vocal Articulations from Acoustic Latent Representations
Mateo C'amara, Fernando Marcos, Jos'e Luis Blanco
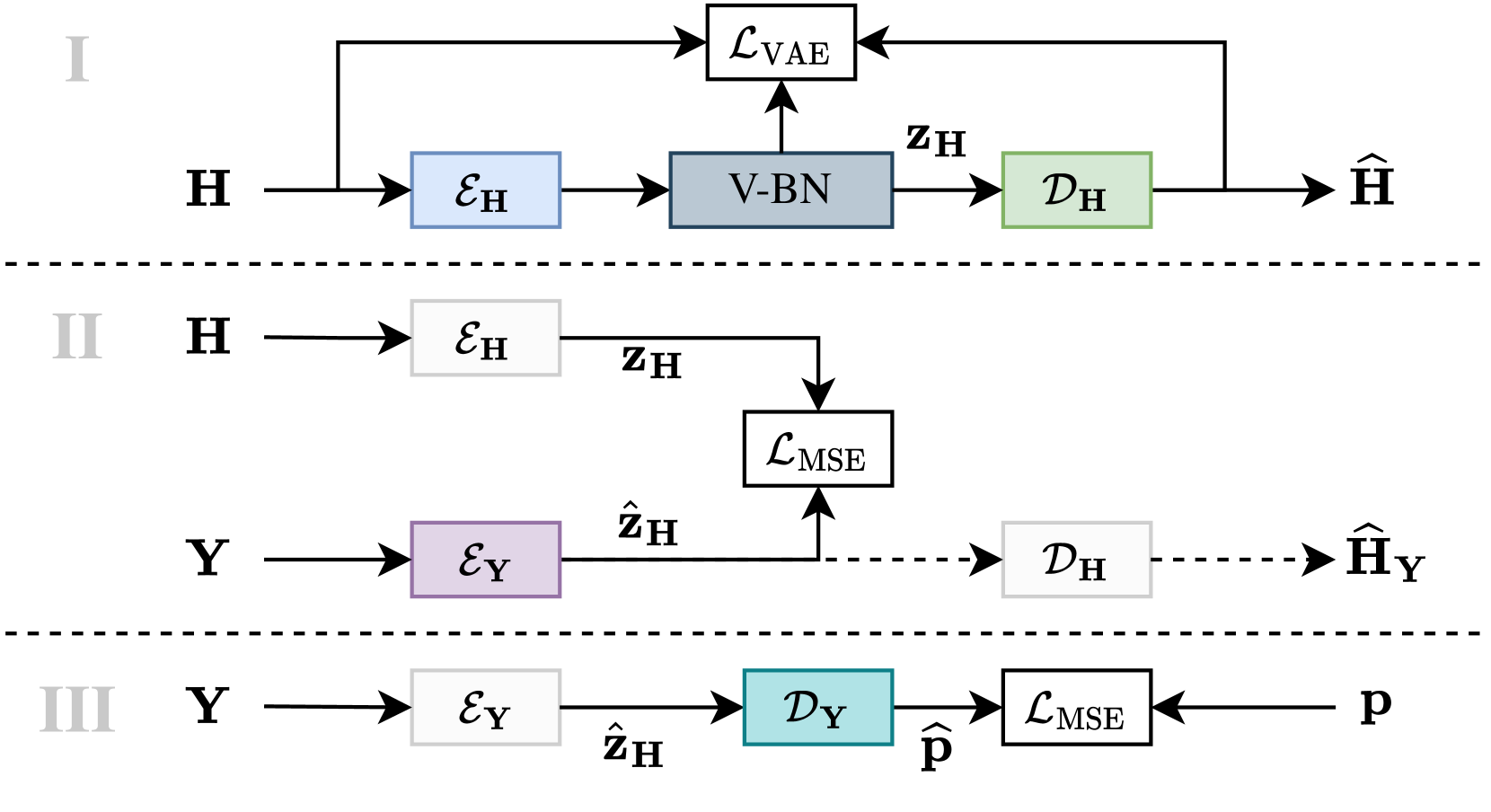
We present a novel neural encoder system for acoustic-to-articulatory inversion. We leverage the Pink Trombone voice synthesizer that reveals articulatory parameters (e.g tongue position and vocal cord configuration). Our system is designed to identify the articulatory features responsible for producing specific acoustic characteristics contained in a neural latent representation. To generate the necessary latent embeddings, we employed two main methodologies. The first was a self-supervised variational autoencoder trained from scratch to reconstruct the input signal at the decoder stage. We conditioned its bottleneck layer with a subnetwork called the projector, which decodes the voice synthesizer's parameters. The second methodology utilized two pretrained models: EnCodec and Wav2Vec. They eliminate the need to train the encoding process from scratch, allowing us to focus on training the projector network. This approach aimed to explore the potential of these existing models in the context of acoustic-to-articulatory inversion. By reusing the pretrained models, we significantly simplified the data processing pipeline, increasing efficiency and reducing computational overhead. The primary goal of our project was to demonstrate that these neural architectures can effectively encapsulate both acoustic and articulatory features. This prediction-based approach is much faster than traditional methods focused on acoustic feature-based parameter optimization. We validated our models by predicting six different parameters and evaluating them with objective and ViSQOL subjective-equivalent metric using both synthesizer- and human-generated sounds. The results show that the predicted parameters can generate human-like vowel sounds when input into the synthesizer. We provide the dataset, code, and detailed findings to support future research in this field.
Read more6/21/2024
0
Blind Acoustic Parameter Estimation Through Task-Agnostic Embeddings Using Latent Approximations
Philipp Gotz, Cagdas Tuna, Andreas Brendel, Andreas Walther, Emanuel A. P. Habets
We present a method for blind acoustic parameter estimation from single-channel reverberant speech. The method is structured into three stages. In the first stage, a variational auto-encoder is trained to extract latent representations of acoustic impulse responses represented as mel-spectrograms. In the second stage, a separate speech encoder is trained to estimate low-dimensional representations from short segments of reverberant speech. Finally, the pre-trained speech encoder is combined with a small regression model and evaluated on two parameter regression tasks. Experimentally, the proposed method is shown to outperform a fully end-to-end trained baseline model.
Read more7/30/2024

0
Articulatory Encodec: Vocal Tract Kinematics as a Codec for Speech
Cheol Jun Cho, Peter Wu, Tejas S. Prabhune, Dhruv Agarwal, Gopala K. Anumanchipalli
Vocal tract articulation is a natural, grounded control space of speech production. The spatiotemporal coordination of articulators combined with the vocal source shapes intelligible speech sounds to enable effective spoken communication. Based on this physiological grounding of speech, we propose a new framework of neural encoding-decoding of speech -- Articulatory Encodec. Articulatory Encodec comprises an articulatory analysis model that infers articulatory features from speech audio, and an articulatory synthesis model that synthesizes speech audio from articulatory features. The articulatory features are kinematic traces of vocal tract articulators and source features, which are intuitively interpretable and controllable, being the actual physical interface of speech production. An additional speaker identity encoder is jointly trained with the articulatory synthesizer to inform the voice texture of individual speakers. By training on large-scale speech data, we achieve a fully intelligible, high-quality articulatory synthesizer that generalizes to unseen speakers. Furthermore, the speaker embedding is effectively disentangled from articulations, which enables accent-perserving zero-shot voice conversion. To the best of our knowledge, this is the first demonstration of universal, high-performance articulatory inference and synthesis, suggesting the proposed framework as a powerful coding system of speech.
Read more8/22/2024

0
Accent Conversion with Articulatory Representations
Yashish M. Siriwardena, Nathan Swedlow, Audrey Howard, Evan Gitterman, Dan Darcy, Carol Espy-Wilson, Andrea Fanelli
Conversion of non-native accented speech to native (American) English has a wide range of applications such as improving intelligibility of non-native speech. Previous work on this domain has used phonetic posteriograms as the target speech representation to train an acoustic model which is then used to extract a compact representation of input speech for accent conversion. In this work, we introduce the idea of using an effective articulatory speech representation, extracted from an acoustic-to-articulatory speech inversion system, to improve the acoustic model used in accent conversion. The idea to incorporate articulatory representations originates from their ability to well characterize accents in speech. To incorporate articulatory representations with conventional phonetic posteriograms, a multi-task learning based acoustic model is proposed. Objective and subjective evaluations show that the use of articulatory representations can improve the effectiveness of accent conversion.
Read more6/11/2024