Accessing GPT-4 level Mathematical Olympiad Solutions via Monte Carlo Tree Self-refine with LLaMa-3 8B
2406.07394
99
0

Abstract
This paper introduces the MCT Self-Refine (MCTSr) algorithm, an innovative integration of Large Language Models (LLMs) with Monte Carlo Tree Search (MCTS), designed to enhance performance in complex mathematical reasoning tasks. Addressing the challenges of accuracy and reliability in LLMs, particularly in strategic and mathematical reasoning, MCTSr leverages systematic exploration and heuristic self-refine mechanisms to improve decision-making frameworks within LLMs. The algorithm constructs a Monte Carlo search tree through iterative processes of Selection, self-refine, self-evaluation, and Backpropagation, utilizing an improved Upper Confidence Bound (UCB) formula to optimize the exploration-exploitation balance. Extensive experiments demonstrate MCTSr's efficacy in solving Olympiad-level mathematical problems, significantly improving success rates across multiple datasets, including GSM8K, GSM Hard, MATH, and Olympiad-level benchmarks, including Math Odyssey, AIME, and OlympiadBench. The study advances the application of LLMs in complex reasoning tasks and sets a foundation for future AI integration, enhancing decision-making accuracy and reliability in LLM-driven applications.
Create account to get full access
Overview
• This paper explores a novel approach to generating high-quality solutions for Mathematical Olympiad problems by combining the strengths of large language models (LLMs) and Monte Carlo Tree Search (MCTS).
• The researchers developed a system that leverages the reasoning and problem-solving capabilities of the LLaMa-3 8B model, a state-of-the-art LLM, and enhances it through a self-refine process using MCTS.
• The goal is to create an AI system that can produce solutions to advanced mathematical problems on par with the performance of the GPT-4 model, which has demonstrated exceptional capabilities in this domain.
Plain English Explanation
The paper describes a method for training AI models to solve complex mathematical problems, such as those found in Mathematical Olympiad competitions, at a level comparable to the impressive GPT-4 model. The key idea is to combine the broad knowledge and language understanding of large language models (LLMs) like LLaMa-3 8B with the strategic reasoning and decision-making capabilities of Monte Carlo Tree Search (MCTS).
The researchers hypothesize that by integrating MCTS into the LLM's problem-solving process, the system can engage in a "self-refine" procedure to iteratively improve its solutions. This involves the LLM generating candidate solutions, which are then evaluated and refined through the MCTS algorithm. The process continues until the system converges on high-quality solutions that meet the desired level of performance.
The rationale behind this approach is that LLMs, while powerful in their language understanding and generation abilities, may struggle with the complex logical reasoning and strategic thinking required to solve advanced mathematical problems. By incorporating MCTS, the system can explore the problem space more effectively, consider multiple solution paths, and refine its responses to achieve results on par with the state-of-the-art GPT-4 model.
Technical Explanation
The researchers developed a system that combines the capabilities of the LLaMa-3 8B LLM with a self-refine process using Monte Carlo Tree Search (MCTS). The LLM is responsible for generating initial candidate solutions to mathematical problems, while the MCTS component evaluates and refines these solutions through a self-improvement process.
The MCTS algorithm is used to explore the problem space and identify the most promising solution paths. By iteratively simulating and evaluating different solution strategies, the system can converge on high-quality solutions that meet the desired level of performance, aiming to reach the capabilities demonstrated by the GPT-4 model in solving advanced mathematical problems.
The researchers leverage the REST-MCTS framework, which allows the LLM and MCTS components to work in tandem, with the LLM generating candidate solutions and the MCTS refining them through a continuous self-training process.
Critical Analysis
The paper presents a promising approach to leveraging the strengths of LLMs and MCTS to tackle complex mathematical problems. However, there are a few potential limitations and areas for further research:
-
The paper does not provide extensive details on the specific architectural and training details of the LLaMa-3 8B model, as well as the implementation of the MCTS component. More information on these aspects would be helpful to assess the feasibility and replicability of the proposed system.
-
The paper focuses on solving Mathematical Olympiad problems, which represent a specific and highly challenging domain. It would be valuable to explore the generalizability of the approach to a broader range of mathematical problems or even other domains beyond mathematics.
-
The paper does not address potential issues related to the interpretability and explainability of the system's decision-making process. As these models become more capable, it is important to understand how they arrive at their solutions, which could have implications for their trustworthiness and deployment in real-world applications.
-
The paper does not discuss the computational and resource requirements of the proposed system, which could be a practical concern for widespread adoption, especially in resource-constrained environments.
Conclusion
The paper presents a novel approach to generating high-quality solutions for advanced mathematical problems by combining the strengths of large language models and Monte Carlo Tree Search. By leveraging the LLaMa-3 8B model and incorporating a self-refine process using MCTS, the researchers aim to create an AI system capable of matching the performance of the state-of-the-art GPT-4 model in solving Mathematical Olympiad problems.
This research contributes to the ongoing efforts to develop AI systems that can handle complex reasoning and problem-solving tasks, with potential applications in education, research, and beyond. While the paper highlights promising results, further exploration of the system's scalability, interpretability, and generalizability could help solidify its impact and pave the way for future advancements in this exciting field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
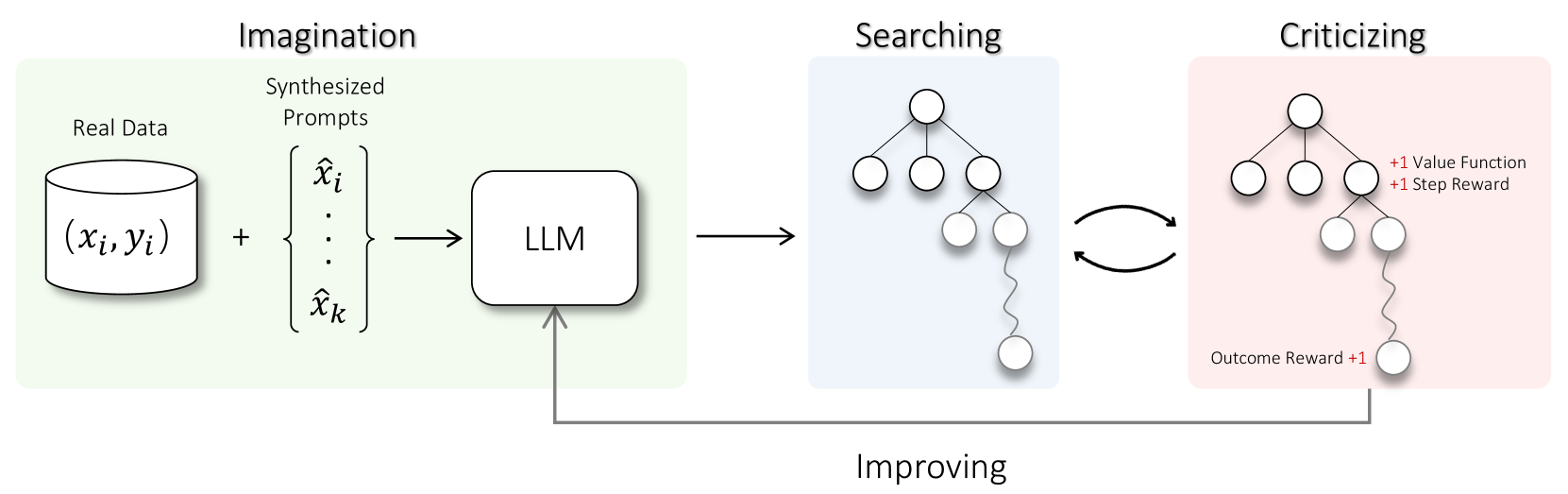
Toward Self-Improvement of LLMs via Imagination, Searching, and Criticizing
Ye Tian, Baolin Peng, Linfeng Song, Lifeng Jin, Dian Yu, Haitao Mi, Dong Yu
0
0
Despite the impressive capabilities of Large Language Models (LLMs) on various tasks, they still struggle with scenarios that involves complex reasoning and planning. Recent work proposed advanced prompting techniques and the necessity of fine-tuning with high-quality data to augment LLMs' reasoning abilities. However, these approaches are inherently constrained by data availability and quality. In light of this, self-correction and self-learning emerge as viable solutions, employing strategies that allow LLMs to refine their outputs and learn from self-assessed rewards. Yet, the efficacy of LLMs in self-refining its response, particularly in complex reasoning and planning task, remains dubious. In this paper, we introduce AlphaLLM for the self-improvements of LLMs, which integrates Monte Carlo Tree Search (MCTS) with LLMs to establish a self-improving loop, thereby enhancing the capabilities of LLMs without additional annotations. Drawing inspiration from the success of AlphaGo, AlphaLLM addresses the unique challenges of combining MCTS with LLM for self-improvement, including data scarcity, the vastness search spaces of language tasks, and the subjective nature of feedback in language tasks. AlphaLLM is comprised of prompt synthesis component, an efficient MCTS approach tailored for language tasks, and a trio of critic models for precise feedback. Our experimental results in mathematical reasoning tasks demonstrate that AlphaLLM significantly enhances the performance of LLMs without additional annotations, showing the potential for self-improvement in LLMs.
4/19/2024
🔎
Monte Carlo Tree Search Boosts Reasoning via Iterative Preference Learning
Yuxi Xie, Anirudh Goyal, Wenyue Zheng, Min-Yen Kan, Timothy P. Lillicrap, Kenji Kawaguchi, Michael Shieh
0
0
We introduce an approach aimed at enhancing the reasoning capabilities of Large Language Models (LLMs) through an iterative preference learning process inspired by the successful strategy employed by AlphaZero. Our work leverages Monte Carlo Tree Search (MCTS) to iteratively collect preference data, utilizing its look-ahead ability to break down instance-level rewards into more granular step-level signals. To enhance consistency in intermediate steps, we combine outcome validation and stepwise self-evaluation, continually updating the quality assessment of newly generated data. The proposed algorithm employs Direct Preference Optimization (DPO) to update the LLM policy using this newly generated step-level preference data. Theoretical analysis reveals the importance of using on-policy sampled data for successful self-improving. Extensive evaluations on various arithmetic and commonsense reasoning tasks demonstrate remarkable performance improvements over existing models. For instance, our approach outperforms the Mistral-7B Supervised Fine-Tuning (SFT) baseline on GSM8K, MATH, and ARC-C, with substantial increases in accuracy to $81.8%$ (+$5.9%$), $34.7%$ (+$5.8%$), and $76.4%$ (+$15.8%$), respectively. Additionally, our research delves into the training and inference compute tradeoff, providing insights into how our method effectively maximizes performance gains. Our code is publicly available at https://github.com/YuxiXie/MCTS-DPO.
6/19/2024
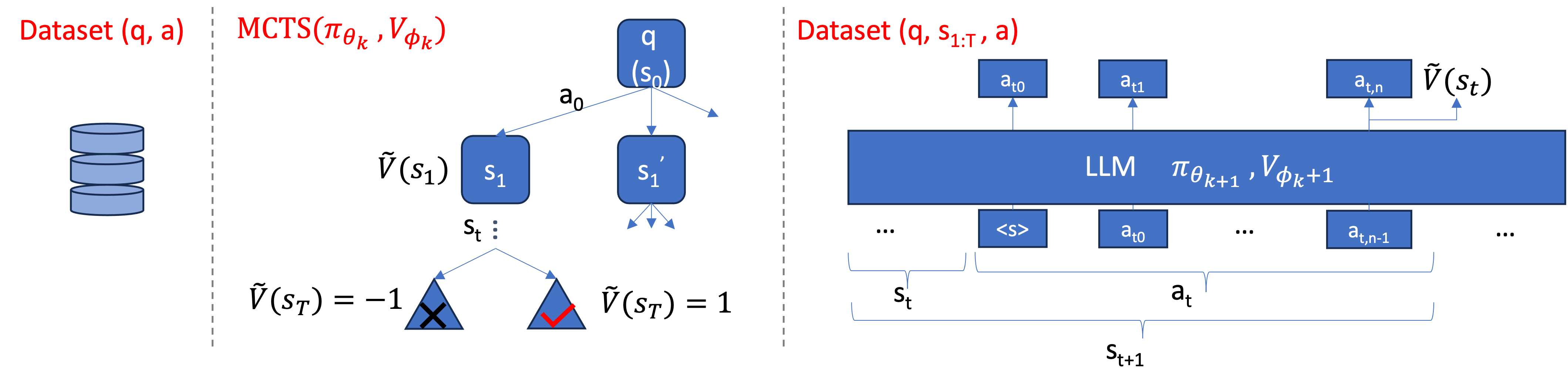
AlphaMath Almost Zero: process Supervision without process
Guoxin Chen, Minpeng Liao, Chengxi Li, Kai Fan
0
0
Recent advancements in large language models (LLMs) have substantially enhanced their mathematical reasoning abilities. However, these models still struggle with complex problems that require multiple reasoning steps, frequently leading to logical or numerical errors. While numerical mistakes can be largely addressed by integrating a code interpreter, identifying logical errors within intermediate steps is more challenging. Moreover, manually annotating these steps for training is not only expensive but also labor-intensive, requiring the expertise of professional annotators. In our study, we introduce an innovative approach that bypasses the need for process annotations (from human or GPTs) by utilizing the Monte Carlo Tree Search (MCTS) framework. This technique automatically generates both the process supervision and the step-level evaluation signals. Our method iteratively trains the policy and value models, leveraging the capabilities of a well-pretrained LLM to progressively enhance its mathematical reasoning skills. Furthermore, we propose an efficient inference strategy-step-level beam search, where the value model is crafted to assist the policy model (i.e., LLM) in navigating more effective reasoning paths, rather than solely relying on prior probabilities. The experimental results on both in-domain and out-of-domain datasets demonstrate that even without GPT-4 or human-annotated process supervision, our AlphaMath framework achieves comparable or superior results to previous state-of-the-art methods.
5/24/2024
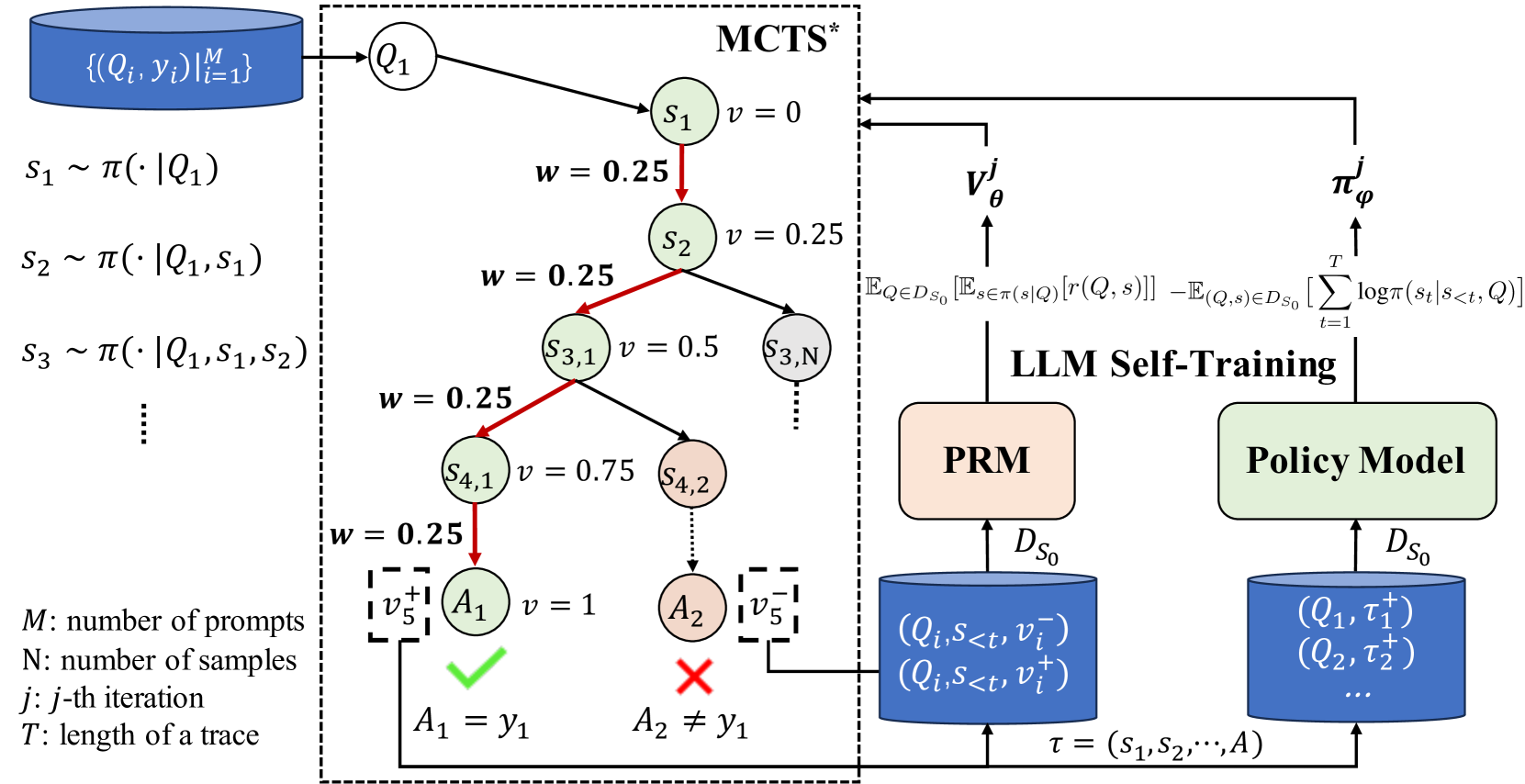
ReST-MCTS*: LLM Self-Training via Process Reward Guided Tree Search
Dan Zhang, Sining Zhoubian, Yisong Yue, Yuxiao Dong, Jie Tang
0
0
Recent methodologies in LLM self-training mostly rely on LLM generating responses and filtering those with correct output answers as training data. This approach often yields a low-quality fine-tuning training set (e.g., incorrect plans or intermediate reasoning). In this paper, we develop a reinforced self-training approach, called ReST-MCTS*, based on integrating process reward guidance with tree search MCTS* for collecting higher-quality reasoning traces as well as per-step value to train policy and reward models. ReST-MCTS* circumvents the per-step manual annotation typically used to train process rewards by tree-search-based reinforcement learning: Given oracle final correct answers, ReST-MCTS* is able to infer the correct process rewards by estimating the probability this step can help lead to the correct answer. These inferred rewards serve dual purposes: they act as value targets for further refining the process reward model and also facilitate the selection of high-quality traces for policy model self-training. We first show that the tree-search policy in ReST-MCTS* achieves higher accuracy compared with prior LLM reasoning baselines such as Best-of-N and Tree-of-Thought, within the same search budget. We then show that by using traces searched by this tree-search policy as training data, we can continuously enhance the three language models for multiple iterations, and outperform other self-training algorithms such as ReST$^text{EM}$ and Self-Rewarding LM.
6/7/2024