Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations
2402.17152
2
0
Abstract
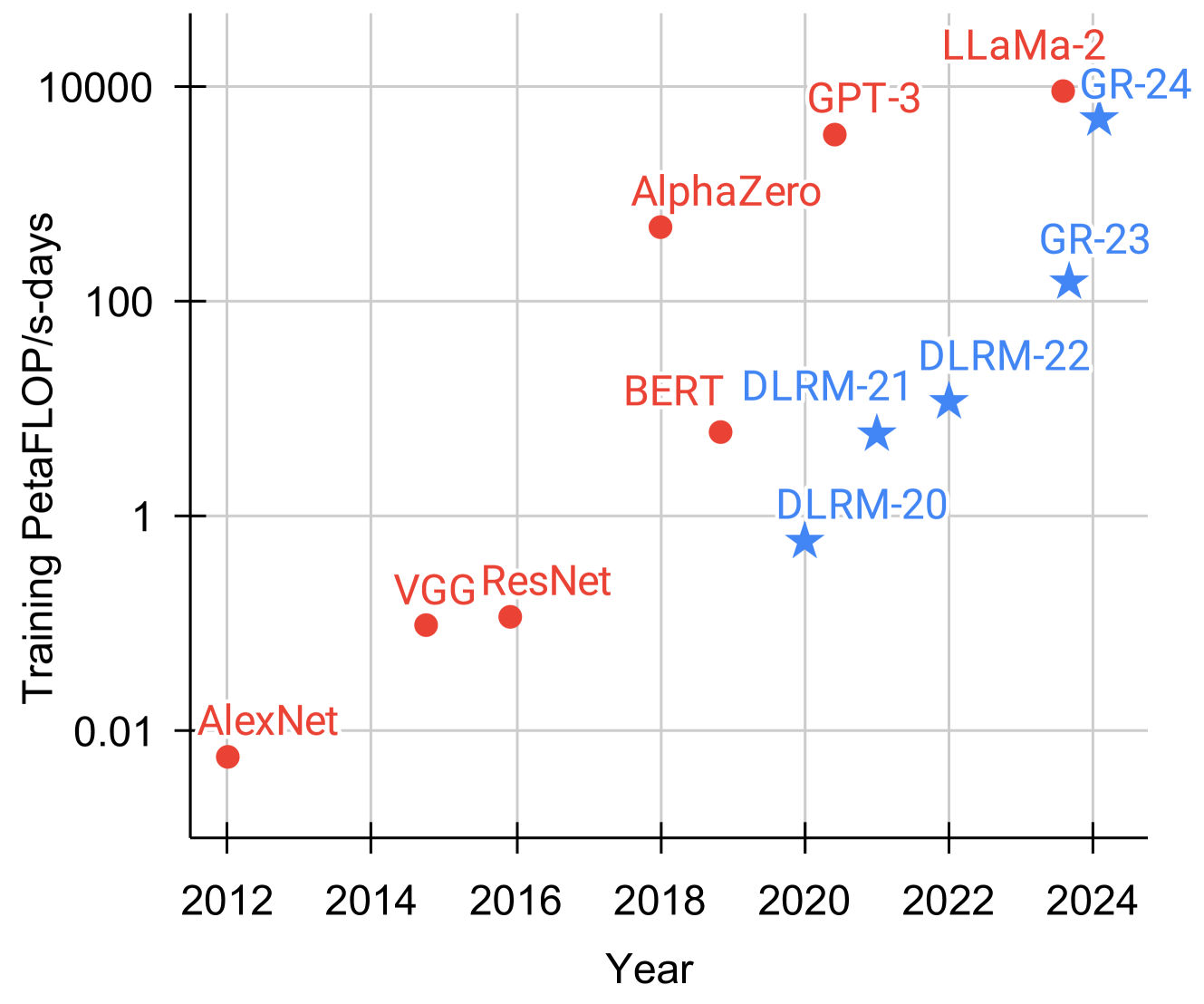
Large-scale recommendation systems are characterized by their reliance on high cardinality, heterogeneous features and the need to handle tens of billions of user actions on a daily basis. Despite being trained on huge volume of data with thousands of features, most Deep Learning Recommendation Models (DLRMs) in industry fail to scale with compute. Inspired by success achieved by Transformers in language and vision domains, we revisit fundamental design choices in recommendation systems. We reformulate recommendation problems as sequential transduction tasks within a generative modeling framework (Generative Recommenders), and propose a new architecture, HSTU, designed for high cardinality, non-stationary streaming recommendation data. HSTU outperforms baselines over synthetic and public datasets by up to 65.8% in NDCG, and is 5.3x to 15.2x faster than FlashAttention2-based Transformers on 8192 length sequences. HSTU-based Generative Recommenders, with 1.5 trillion parameters, improve metrics in online A/B tests by 12.4% and have been deployed on multiple surfaces of a large internet platform with billions of users. More importantly, the model quality of Generative Recommenders empirically scales as a power-law of training compute across three orders of magnitude, up to GPT-3/LLaMa-2 scale, which reduces carbon footprint needed for future model developments, and further paves the way for the first foundational models in recommendations.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper introduces a new approach for generative recommendations called "Actions Speak Louder than Words" (ASLW), which utilizes trillion-parameter sequential transducers.
- ASLW aims to improve upon traditional deep learning recommendation models (DLRMs) by treating recommendation as a sequential transduction task.
- The paper explores how this approach can lead to more effective and personalized recommendations compared to existing methods.
Plain English Explanation
The researchers have developed a new way to make recommendations to users, called "Actions Speak Louder than Words" (ASLW). Typical recommendation systems today use deep learning models to analyze a user's past behavior and interests to suggest new things they might like. However, the researchers argue that these models have limitations, as they don't fully capture the dynamic nature of user interests over time.
ASLW instead treats the recommendation process as a "sequential transduction" task, where the model generates a sequence of recommended items based on the user's past actions and interests. This allows the model to better adapt to changes in user preferences and make more personalized suggestions.
The key innovation in ASLW is the use of "trillion-parameter" sequential transducers, which are large-scale neural network models capable of processing long sequences of information. By leveraging the power of these massive models, the researchers believe ASLW can produce higher-quality and more relevant recommendations for users.
Technical Explanation
The paper proposes a new approach for generative recommendations called "Actions Speak Louder than Words" (ASLW), which builds on the idea of treating recommendation as a sequential transduction task. Traditional deep learning recommendation models (DLRMs) typically focus on predicting a user's next interaction, but the authors argue that this limited view fails to capture the dynamic nature of user interests over time.
ASLW aims to address this by using a trillion-parameter sequential transducer to generate a sequence of recommended items for a user based on their past actions and interactions. This allows the model to better adapt to changes in user preferences and make more personalized suggestions.
The authors draw inspiration from recent advances in sequence-to-sequence transduction models and generative personalized prompts to develop the ASLW architecture. They demonstrate through experiments that ASLW can outperform traditional DLRM approaches in terms of recommendation quality and personalization.
Critical Analysis
The paper presents a compelling approach to improving recommendation systems by treating the task as a sequential transduction problem. The use of large-scale trillion-parameter models is an exciting development that could lead to more effective and personalized recommendations.
However, the authors acknowledge that the training and deployment of such massive models come with significant computational and resource requirements. Additionally, the paper does not delve into the potential biases or fairness issues that could arise from such powerful recommendation systems, which is an important consideration for real-world applications.
Further research is needed to address the scalability and robustness of the ASLW approach, as well as to explore its implications for user privacy, algorithmic transparency, and the broader societal impact of advanced recommendation technologies.
Conclusion
The "Actions Speak Louder than Words" (ASLW) approach introduces a novel way to tackle the recommendation problem by framing it as a sequential transduction task. By leveraging the power of trillion-parameter models, the researchers aim to create more effective and personalized recommendations compared to traditional deep learning recommendation models (DLRMs).
This work highlights the potential of large-scale generative models and sequence-to-sequence transduction techniques to advance the field of recommender systems. While the computational and ethical challenges of such powerful models must be addressed, the ASLW approach represents an exciting direction for improving the user experience and relevance of recommendation systems.
Related Papers
Generative AI Beyond LLMs: System Implications of Multi-Modal Generation
Alicia Golden, Samuel Hsia, Fei Sun, Bilge Acun, Basil Hosmer, Yejin Lee, Zachary DeVito, Jeff Johnson, Gu-Yeon Wei, David Brooks, Carole-Jean Wu
0
0
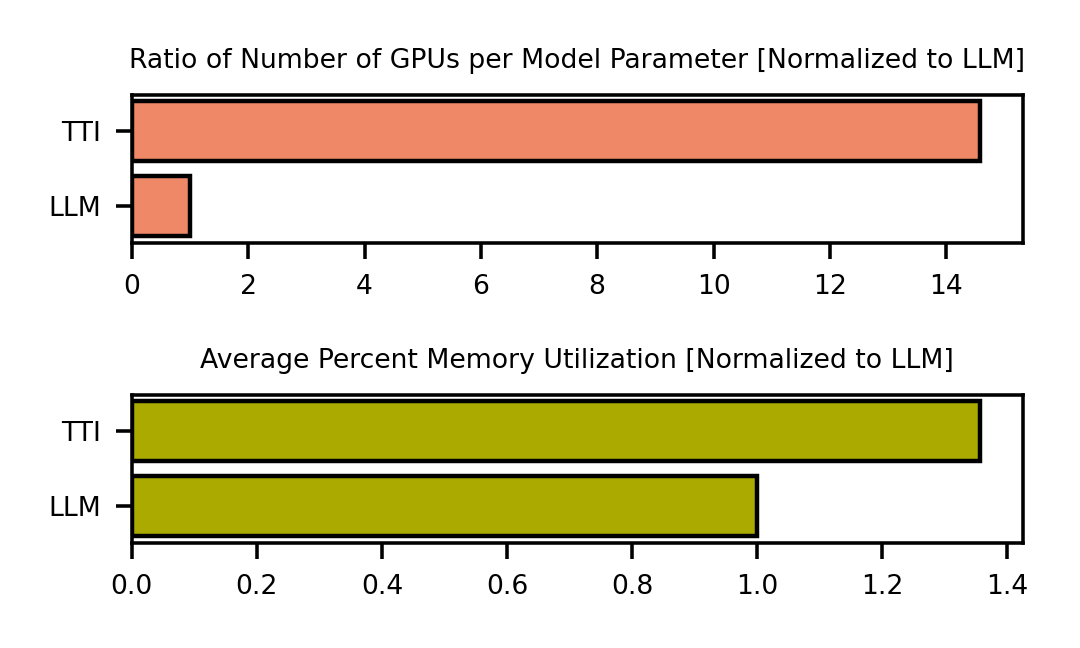
As the development of large-scale Generative AI models evolve beyond text (1D) generation to include image (2D) and video (3D) generation, processing spatial and temporal information presents unique challenges to quality, performance, and efficiency. We present the first work towards understanding this new system design space for multi-modal text-to-image (TTI) and text-to-video (TTV) generation models. Current model architecture designs are bifurcated into 2 categories: Diffusion- and Transformer-based models. Our systematic performance characterization on a suite of eight representative TTI/TTV models shows that after state-of-the-art optimization techniques such as Flash Attention are applied, Convolution accounts for up to 44% of execution time for Diffusion-based TTI models, while Linear layers consume up to 49% of execution time for Transformer-based models. We additionally observe that Diffusion-based TTI models resemble the Prefill stage of LLM inference, and benefit from 1.1-2.5x greater speedup from Flash Attention than Transformer-based TTI models that resemble the Decode phase. Since optimizations designed for LLMs do not map directly onto TTI/TTV models, we must conduct a thorough characterization of these workloads to gain insights for new optimization opportunities. In doing so, we define sequence length in the context of TTI/TTV models and observe sequence length can vary up to 4x in Diffusion model inference. We additionally observe temporal aspects of TTV workloads pose unique system bottlenecks, with Temporal Attention accounting for over 60% of total Attention time. Overall, our in-depth system performance characterization is a critical first step towards designing efficient and deployable systems for emerging TTI/TTV workloads.
5/7/2024
CALRec: Contrastive Alignment of Generative LLMs For Sequential Recommendation
Yaoyiran Li, Xiang Zhai, Moustafa Alzantot, Keyi Yu, Ivan Vuli'c, Anna Korhonen, Mohamed Hammad
0
0
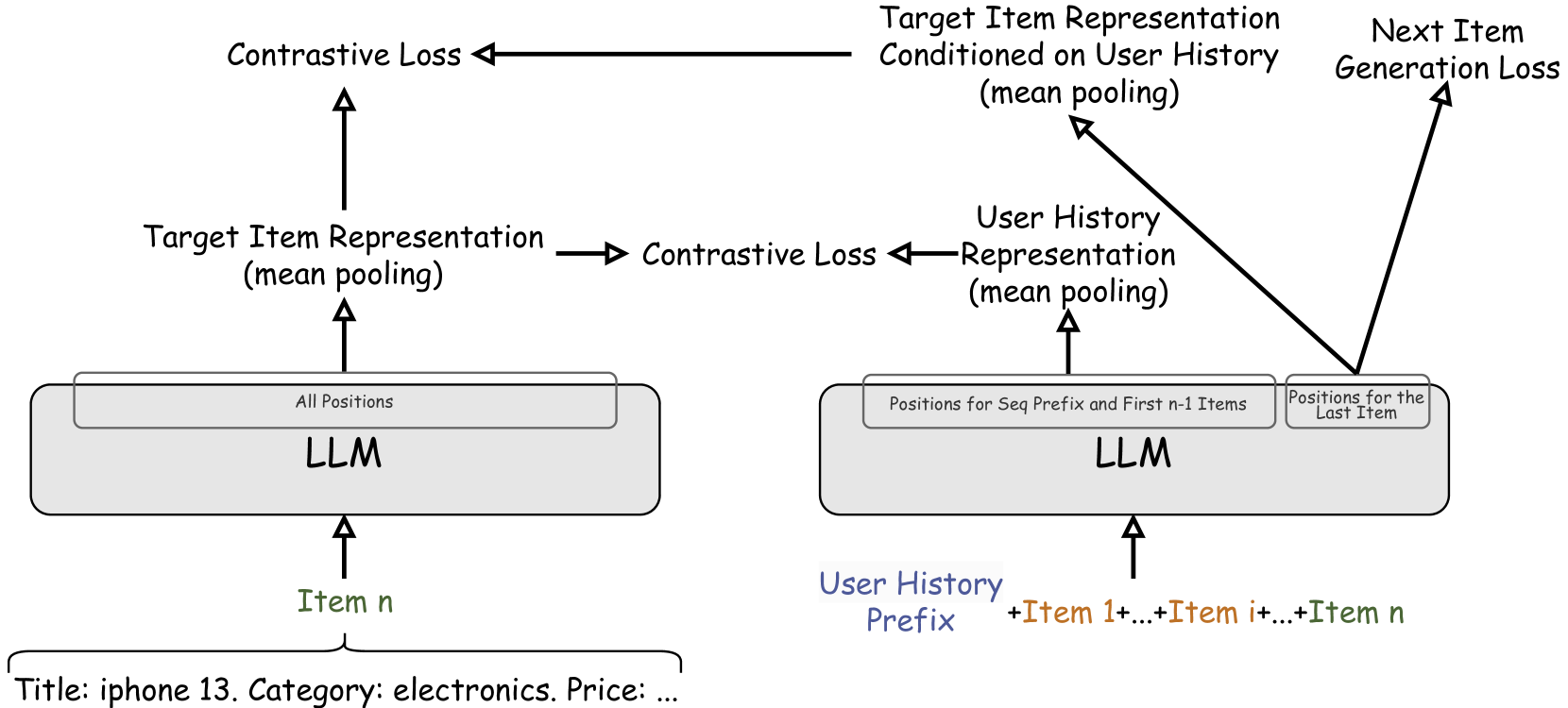
Traditional recommender systems such as matrix factorization methods rely on learning a shared dense embedding space to represent both items and user preferences. Sequence models such as RNN, GRUs, and, recently, Transformers have also excelled in the task of sequential recommendation. This task requires understanding the sequential structure present in users' historical interactions to predict the next item they may like. Building upon the success of Large Language Models (LLMs) in a variety of tasks, researchers have recently explored using LLMs that are pretrained on vast corpora of text for sequential recommendation. To use LLMs in sequential recommendations, both the history of user interactions and the model's prediction of the next item are expressed in text form. We propose CALRec, a two-stage LLM finetuning framework that finetunes a pretrained LLM in a two-tower fashion using a mixture of two contrastive losses and a language modeling loss: the LLM is first finetuned on a data mixture from multiple domains followed by another round of target domain finetuning. Our model significantly outperforms many state-of-the-art baselines (+37% in Recall@1 and +24% in NDCG@10) and systematic ablation studies reveal that (i) both stages of finetuning are crucial, and, when combined, we achieve improved performance, and (ii) contrastive alignment is effective among the target domains explored in our experiments.
5/7/2024
📶
TruthSR: Trustworthy Sequential Recommender Systems via User-generated Multimodal Content
Meng Yan, Haibin Huang, Ying Liu, Juan Zhao, Xiyue Gao, Cai Xu, Ziyu Guan, Wei Zhao
0
0
Sequential recommender systems explore users' preferences and behavioral patterns from their historically generated data. Recently, researchers aim to improve sequential recommendation by utilizing massive user-generated multi-modal content, such as reviews, images, etc. This content often contains inevitable noise. Some studies attempt to reduce noise interference by suppressing cross-modal inconsistent information. However, they could potentially constrain the capturing of personalized user preferences. In addition, it is almost impossible to entirely eliminate noise in diverse user-generated multi-modal content. To solve these problems, we propose a trustworthy sequential recommendation method via noisy user-generated multi-modal content. Specifically, we explicitly capture the consistency and complementarity of user-generated multi-modal content to mitigate noise interference. We also achieve the modeling of the user's multi-modal sequential preferences. In addition, we design a trustworthy decision mechanism that integrates subjective user perspective and objective item perspective to dynamically evaluate the uncertainty of prediction results. Experimental evaluation on four widely-used datasets demonstrates the superior performance of our model compared to state-of-the-art methods. The code is released at https://github.com/FairyMeng/TrustSR.
4/29/2024
MMGRec: Multimodal Generative Recommendation with Transformer Model
Han Liu, Yinwei Wei, Xuemeng Song, Weili Guan, Yuan-Fang Li, Liqiang Nie
0
0
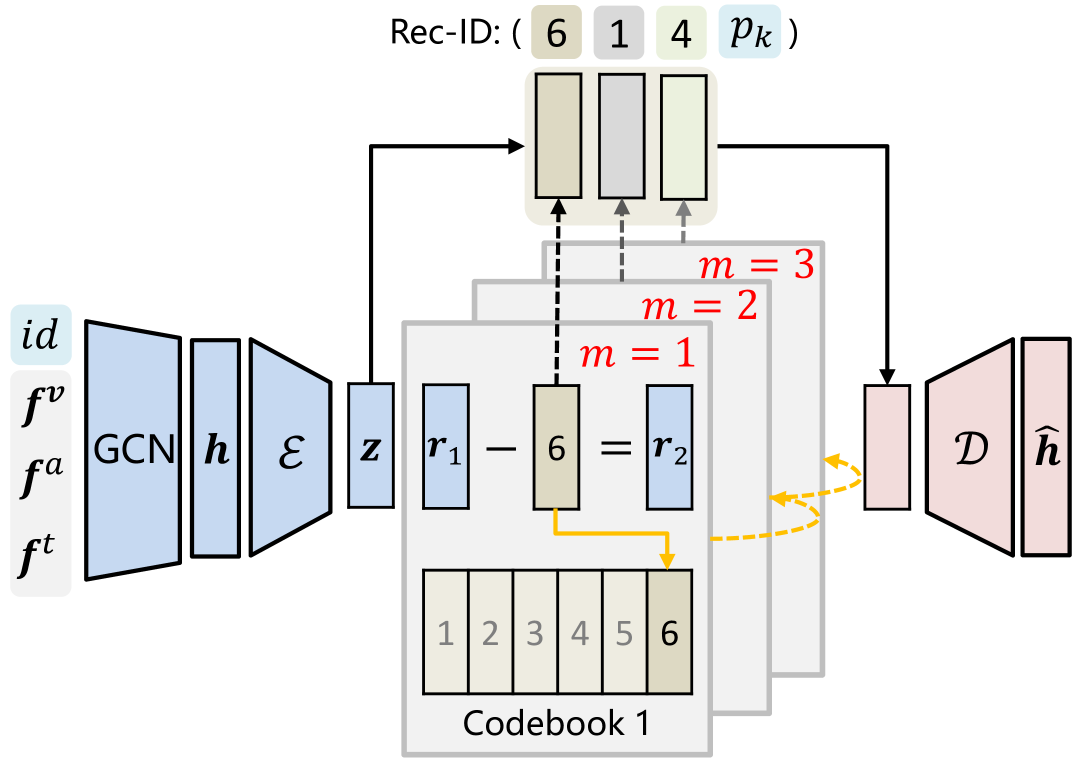
Multimodal recommendation aims to recommend user-preferred candidates based on her/his historically interacted items and associated multimodal information. Previous studies commonly employ an embed-and-retrieve paradigm: learning user and item representations in the same embedding space, then retrieving similar candidate items for a user via embedding inner product. However, this paradigm suffers from inference cost, interaction modeling, and false-negative issues. Toward this end, we propose a new MMGRec model to introduce a generative paradigm into multimodal recommendation. Specifically, we first devise a hierarchical quantization method Graph RQ-VAE to assign Rec-ID for each item from its multimodal and CF information. Consisting of a tuple of semantically meaningful tokens, Rec-ID serves as the unique identifier of each item. Afterward, we train a Transformer-based recommender to generate the Rec-IDs of user-preferred items based on historical interaction sequences. The generative paradigm is qualified since this model systematically predicts the tuple of tokens identifying the recommended item in an autoregressive manner. Moreover, a relation-aware self-attention mechanism is devised for the Transformer to handle non-sequential interaction sequences, which explores the element pairwise relation to replace absolute positional encoding. Extensive experiments evaluate MMGRec's effectiveness compared with state-of-the-art methods.
4/26/2024