AdaBM: On-the-Fly Adaptive Bit Mapping for Image Super-Resolution
2404.03296
0
0
Abstract
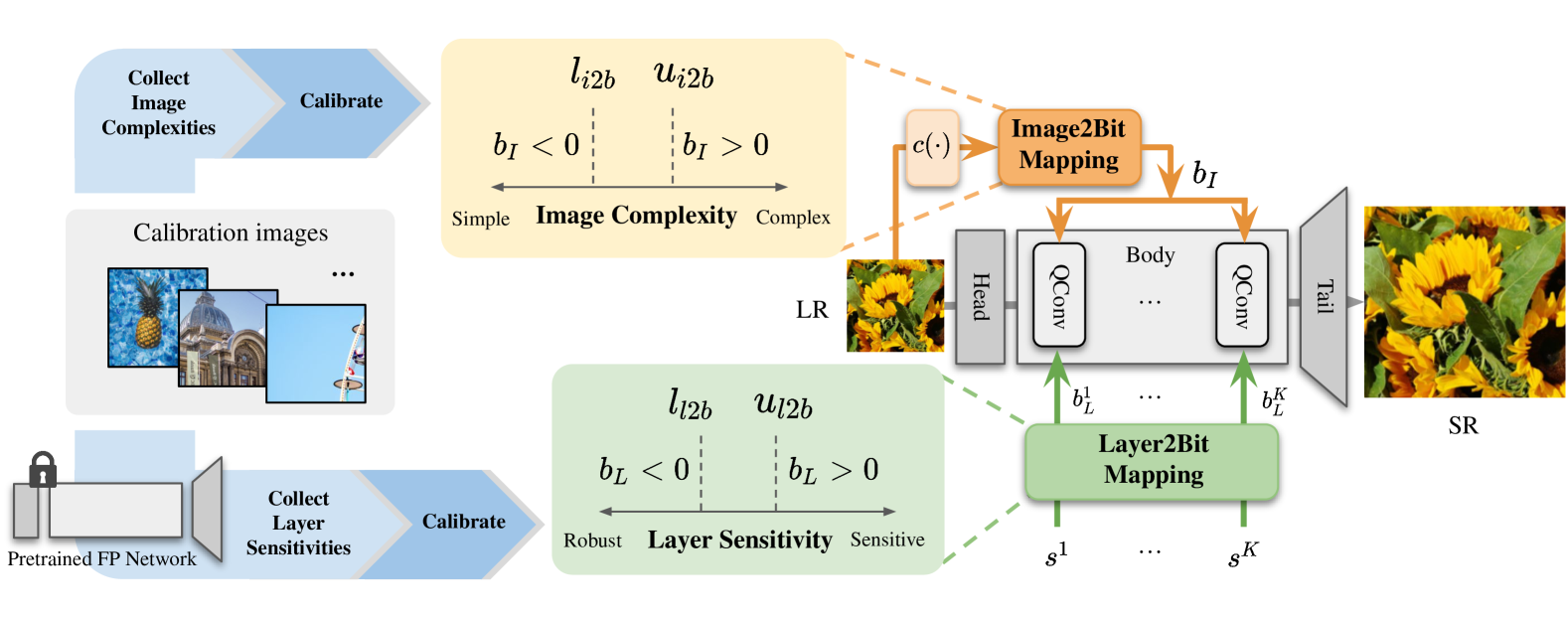
Although image super-resolution (SR) problem has experienced unprecedented restoration accuracy with deep neural networks, it has yet limited versatile applications due to the substantial computational costs. Since different input images for SR face different restoration difficulties, adapting computational costs based on the input image, referred to as adaptive inference, has emerged as a promising solution to compress SR networks. Specifically, adapting the quantization bit-widths has successfully reduced the inference and memory cost without sacrificing the accuracy. However, despite the benefits of the resultant adaptive network, existing works rely on time-intensive quantization-aware training with full access to the original training pairs to learn the appropriate bit allocation policies, which limits its ubiquitous usage. To this end, we introduce the first on-the-fly adaptive quantization framework that accelerates the processing time from hours to seconds. We formulate the bit allocation problem with only two bit mapping modules: one to map the input image to the image-wise bit adaptation factor and one to obtain the layer-wise adaptation factors. These bit mappings are calibrated and fine-tuned using only a small number of calibration images. We achieve competitive performance with the previous adaptive quantization methods, while the processing time is accelerated by x2000. Codes are available at https://github.com/Cheeun/AdaBM.
Create account to get full access
Overview
- This paper proposes a new method called AdaBM (Adaptive Bit Mapping) for improving image super-resolution, which is the task of upscaling low-resolution images to higher resolutions.
- The key idea is to adaptively adjust the bit depth (number of bits used to represent each pixel) on-the-fly during the super-resolution process, rather than using a fixed bit depth.
- The authors show that this adaptive bit mapping strategy can lead to better performance compared to using a fixed bit depth.
Plain English Explanation
The goal of image super-resolution is to take a low-quality, low-resolution image and intelligently "fill in the gaps" to create a higher-quality, higher-resolution version of the same image. This is a challenging task that requires sophisticated algorithms to analyze the image and reconstruct the missing details.
The AdaBM method proposed in this paper tries to tackle the super-resolution problem in a new way. Instead of using a fixed number of bits to represent each pixel in the output image (a common approach), AdaBM dynamically adjusts the bit depth on-the-fly as it's processing the image.
The intuition is that different parts of an image may benefit from different bit depths. For example, high-contrast regions like edges might require more bits to capture the details, while smooth regions could get by with fewer bits. By adapting the bit depth to the local image content, AdaBM can potentially produce better super-resolved images compared to methods that use a one-size-fits-all bit depth.
The paper demonstrates that this adaptive bit mapping strategy can indeed lead to improved super-resolution performance on standard benchmark datasets. The authors also provide insights into how the bit depth adaptation happens and why it is beneficial.
Technical Explanation
The core of the AdaBM method is a module that dynamically adjusts the bit depth used to represent the super-resolved image features. This bit depth adaptation happens on-the-fly as the super-resolution network processes the input low-resolution image.
The AdaBM module takes the intermediate feature maps produced by the super-resolution network and learns to predict the optimal bit depth for each spatial location in the feature maps. This predicted bit depth is then used to quantize the feature values, effectively controlling the level of detail preserved in different regions of the image.
The authors train the AdaBM module end-to-end along with the rest of the super-resolution network, allowing the bit depth adaptation to be optimized for the specific task and dataset. They show that this adaptive bit mapping strategy outperforms using a fixed bit depth across the entire image.
Additionally, the paper explores how the AdaBM approach can be combined with other super-resolution techniques, such as diffusion models, to further improve performance.
Critical Analysis
The AdaBM paper presents a novel and interesting approach to improving image super-resolution. The key strength of the method is its ability to dynamically adjust the bit depth used to represent the image features, which allows it to better capture the varying levels of detail across different regions of the image.
However, the paper does not address some potential limitations of the AdaBM approach. For example, the computational overhead of the bit depth prediction module is not discussed, and it's unclear how this additional complexity affects the overall efficiency of the super-resolution pipeline.
Additionally, the paper focuses on evaluating AdaBM on standard super-resolution benchmarks, but it would be interesting to see how the method performs on more diverse or challenging datasets, such as those with complex textures or scene layouts.
Furthermore, the authors do not explore the potential implications of adaptive bit depth representation for other image processing tasks beyond super-resolution, such as image recognition or compression. Investigating these broader applications could help contextualize the significance of the AdaBM approach.
Conclusion
The AdaBM paper presents an innovative method for improving image super-resolution by adaptively adjusting the bit depth used to represent the image features. The key insight is that different regions of an image may benefit from different levels of detail, and by dynamically optimizing the bit depth, the super-resolution performance can be enhanced.
The experimental results show that the AdaBM approach outperforms using a fixed bit depth across the entire image, demonstrating the benefits of this adaptive bit mapping strategy. While the paper focuses on super-resolution, the underlying principles of AdaBM could potentially be applied to other image processing tasks, opening up interesting avenues for future research.
Overall, the AdaBM method represents a promising step forward in the field of image super-resolution, and its adaptive bit depth representation could have broader implications for the wider landscape of image-based machine learning applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
AdaQAT: Adaptive Bit-Width Quantization-Aware Training
C'edric Gernigon (TARAN), Silviu-Ioan Filip (TARAN), Olivier Sentieys (TARAN), Cl'ement Coggiola (CNES), Mickael Bruno (CNES)
0
0
Large-scale deep neural networks (DNNs) have achieved remarkable success in many application scenarios. However, high computational complexity and energy costs of modern DNNs make their deployment on edge devices challenging. Model quantization is a common approach to deal with deployment constraints, but searching for optimized bit-widths can be challenging. In this work, we present Adaptive Bit-Width Quantization Aware Training (AdaQAT), a learning-based method that automatically optimizes weight and activation signal bit-widths during training for more efficient DNN inference. We use relaxed real-valued bit-widths that are updated using a gradient descent rule, but are otherwise discretized for all quantization operations. The result is a simple and flexible QAT approach for mixed-precision uniform quantization problems. Compared to other methods that are generally designed to be run on a pretrained network, AdaQAT works well in both training from scratch and fine-tuning scenarios.Initial results on the CIFAR-10 and ImageNet datasets using ResNet20 and ResNet18 models, respectively, indicate that our method is competitive with other state-of-the-art mixed-precision quantization approaches.
4/29/2024

2DQuant: Low-bit Post-Training Quantization for Image Super-Resolution
Kai Liu, Haotong Qin, Yong Guo, Xin Yuan, Linghe Kong, Guihai Chen, Yulun Zhang
0
0
Low-bit quantization has become widespread for compressing image super-resolution (SR) models for edge deployment, which allows advanced SR models to enjoy compact low-bit parameters and efficient integer/bitwise constructions for storage compression and inference acceleration, respectively. However, it is notorious that low-bit quantization degrades the accuracy of SR models compared to their full-precision (FP) counterparts. Despite several efforts to alleviate the degradation, the transformer-based SR model still suffers severe degradation due to its distinctive activation distribution. In this work, we present a dual-stage low-bit post-training quantization (PTQ) method for image super-resolution, namely 2DQuant, which achieves efficient and accurate SR under low-bit quantization. The proposed method first investigates the weight and activation and finds that the distribution is characterized by coexisting symmetry and asymmetry, long tails. Specifically, we propose Distribution-Oriented Bound Initialization (DOBI), using different searching strategies to search a coarse bound for quantizers. To obtain refined quantizer parameters, we further propose Distillation Quantization Calibration (DQC), which employs a distillation approach to make the quantized model learn from its FP counterpart. Through extensive experiments on different bits and scaling factors, the performance of DOBI can reach the state-of-the-art (SOTA) while after stage two, our method surpasses existing PTQ in both metrics and visual effects. 2DQuant gains an increase in PSNR as high as 4.52dB on Set5 (x2) compared with SOTA when quantized to 2-bit and enjoys a 3.60x compression ratio and 5.08x speedup ratio. The code and models will be available at https://github.com/Kai-Liu001/2DQuant.
6/12/2024
🏷️
EfficientDM: Efficient Quantization-Aware Fine-Tuning of Low-Bit Diffusion Models
Yefei He, Jing Liu, Weijia Wu, Hong Zhou, Bohan Zhuang
0
0
Diffusion models have demonstrated remarkable capabilities in image synthesis and related generative tasks. Nevertheless, their practicality for real-world applications is constrained by substantial computational costs and latency issues. Quantization is a dominant way to compress and accelerate diffusion models, where post-training quantization (PTQ) and quantization-aware training (QAT) are two main approaches, each bearing its own properties. While PTQ exhibits efficiency in terms of both time and data usage, it may lead to diminished performance in low bit-width. On the other hand, QAT can alleviate performance degradation but comes with substantial demands on computational and data resources. In this paper, we introduce a data-free and parameter-efficient fine-tuning framework for low-bit diffusion models, dubbed EfficientDM, to achieve QAT-level performance with PTQ-like efficiency. Specifically, we propose a quantization-aware variant of the low-rank adapter (QALoRA) that can be merged with model weights and jointly quantized to low bit-width. The fine-tuning process distills the denoising capabilities of the full-precision model into its quantized counterpart, eliminating the requirement for training data. We also introduce scale-aware optimization and temporal learned step-size quantization to further enhance performance. Extensive experimental results demonstrate that our method significantly outperforms previous PTQ-based diffusion models while maintaining similar time and data efficiency. Specifically, there is only a 0.05 sFID increase when quantizing both weights and activations of LDM-4 to 4-bit on ImageNet 256x256. Compared to QAT-based methods, our EfficientDM also boasts a 16.2x faster quantization speed with comparable generation quality. Code is available at href{https://github.com/ThisisBillhe/EfficientDM}{this hrl}.
4/16/2024
Towards Lightweight Speaker Verification via Adaptive Neural Network Quantization
Bei Liu, Haoyu Wang, Yanmin Qian
0
0
Modern speaker verification (SV) systems typically demand expensive storage and computing resources, thereby hindering their deployment on mobile devices. In this paper, we explore adaptive neural network quantization for lightweight speaker verification. Firstly, we propose a novel adaptive uniform precision quantization method which enables the dynamic generation of quantization centroids customized for each network layer based on k-means clustering. By applying it to the pre-trained SV systems, we obtain a series of quantized variants with different bit widths. To enhance the performance of low-bit quantized models, a mixed precision quantization algorithm along with a multi-stage fine-tuning (MSFT) strategy is further introduced. Unlike uniform precision quantization, mixed precision approach allows for the assignment of varying bit widths to different network layers. When bit combination is determined, MSFT is employed to progressively quantize and fine-tune network in a specific order. Finally, we design two distinct binary quantization schemes to mitigate performance degradation of 1-bit quantized models: the static and adaptive quantizers. Experiments on VoxCeleb demonstrate that lossless 4-bit uniform precision quantization is achieved on both ResNets and DF-ResNets, yielding a promising compression ratio of around 8. Moreover, compared to uniform precision approach, mixed precision quantization not only obtains additional performance improvements with a similar model size but also offers the flexibility to generate bit combination for any desirable model size. In addition, our suggested 1-bit quantization schemes remarkably boost the performance of binarized models. Finally, a thorough comparison with existing lightweight SV systems reveals that our proposed models outperform all previous methods by a large margin across various model size ranges.
6/19/2024