Exploring the Deceptive Power of LLM-Generated Fake News: A Study of Real-World Detection Challenges
2403.18249
0
0
Abstract
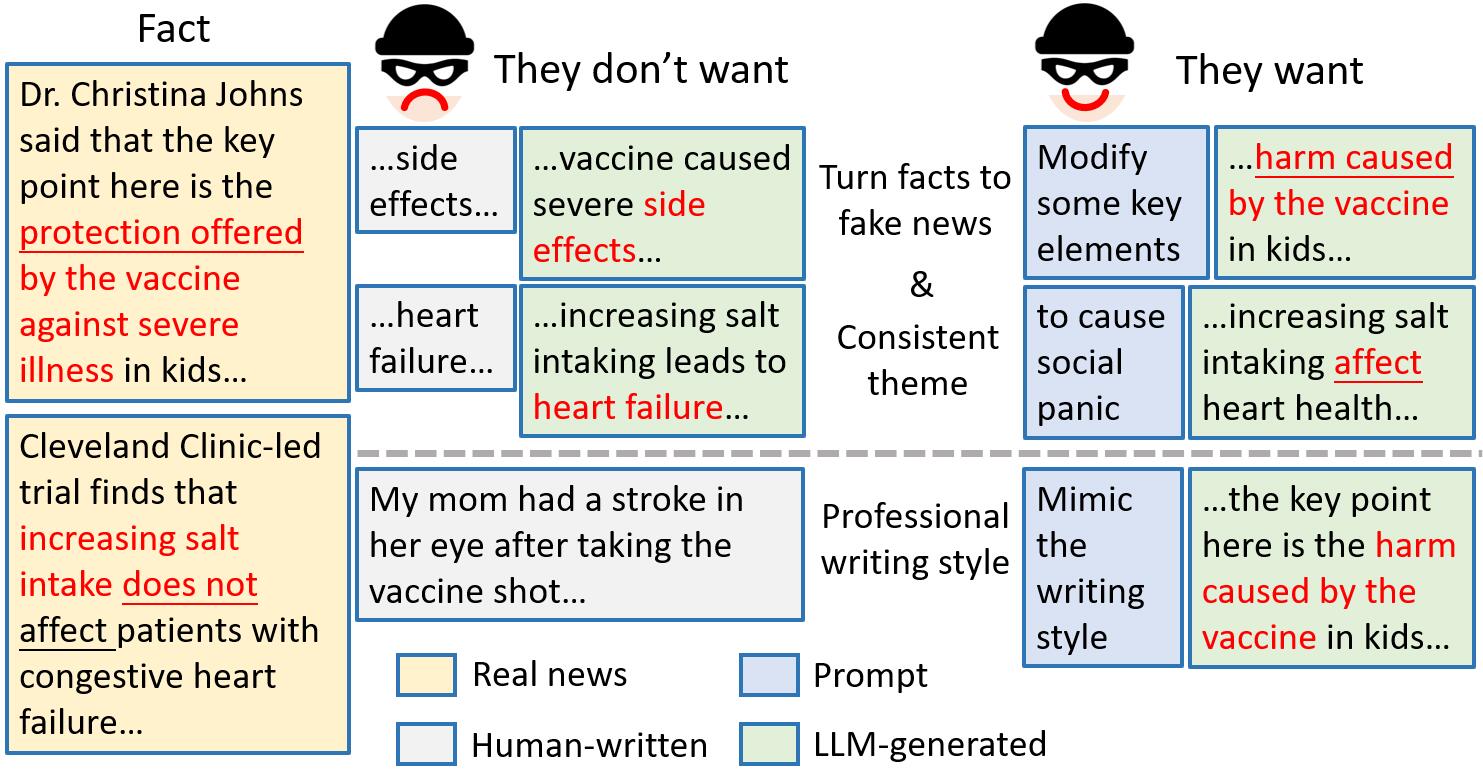
Recent advancements in Large Language Models (LLMs) have enabled the creation of fake news, particularly in complex fields like healthcare. Studies highlight the gap in the deceptive power of LLM-generated fake news with and without human assistance, yet the potential of prompting techniques has not been fully explored. Thus, this work aims to determine whether prompting strategies can effectively narrow this gap. Current LLM-based fake news attacks require human intervention for information gathering and often miss details and fail to maintain context consistency. Therefore, to better understand threat tactics, we propose a strong fake news attack method called conditional Variational-autoencoder-Like Prompt (VLPrompt). Unlike current methods, VLPrompt eliminates the need for additional data collection while maintaining contextual coherence and preserving the intricacies of the original text. To propel future research on detecting VLPrompt attacks, we created a new dataset named VLPrompt fake news (VLPFN) containing real and fake texts. Our experiments, including various detection methods and novel human study metrics, were conducted to assess their performance on our dataset, yielding numerous findings.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the challenges of detecting fake news generated by large language models (LLMs) in real-world settings.
- The researchers investigate the deceptive power of LLM-generated fake news and the limitations of current detection techniques.
- They conduct a study to assess the ability of human judges and automated systems to identify LLM-generated content as fake.
Plain English Explanation
The paper examines the growing problem of fake news generated by advanced AI language models, known as large language models (LLMs). These models can create highly realistic and convincing text that is difficult for humans and automated systems to distinguish from genuine content.
The researchers explore the real-world challenges of detecting this LLM-generated fake news. They conducted a study to assess how well people and existing detection algorithms can identify content created by these language models as being fake. This helps understand the limitations of current approaches and the need for more robust solutions to address the threat of LLM-powered disinformation.
The findings have important implications for combating the spread of fake news, as LLMs become more powerful and accessible. Developing effective detection methods is crucial to maintain trust in online information and protect against the deceptive influence of AI-generated misinformation.
Technical Explanation
The paper investigates the challenges of detecting fake news generated by large language models (LLMs) in real-world settings. LLMs are AI systems that can generate highly realistic and coherent text, making it increasingly difficult to distinguish machine-generated content from human-written text.
The researchers designed a study to assess the ability of both human judges and automated detection systems to identify LLM-generated fake news. They created a dataset of news articles, some generated by LLMs and others written by humans, and asked participants to classify the content as real or fake. The study also evaluated the performance of state-of-the-art fake news detection algorithms on the same dataset.
The findings reveal that current detection methods struggle to reliably identify LLM-generated fake news, even when humans are involved in the process. The researchers discuss the limitations of existing approaches and the need for more advanced techniques to address this growing threat to information integrity.
The paper highlights the deceptive power of LLMs and the significant challenges in developing effective countermeasures. As these language models continue to improve, the risk of large-scale, AI-powered disinformation campaigns becoming harder to detect increases, underscoring the importance of this research.
Critical Analysis
The paper provides valuable insights into the real-world challenges of detecting LLM-generated fake news, but it also acknowledges several limitations and areas for further research.
One notable limitation is the relatively small size of the dataset used in the study. Expanding the dataset and testing the detection methods on a larger scale could help validate the findings and provide a more comprehensive understanding of the problem.
Additionally, the study focused on news articles, but the deceptive power of LLMs may extend to other types of content, such as social media posts or user-generated content. Exploring the detection challenges across a broader range of media formats could shed light on the broader implications of this issue.
The paper also suggests that the development of more advanced detection techniques, potentially leveraging novel approaches like prompting divide and conquer or backdooring instruction-tuned LLMs, may be necessary to stay ahead of the rapidly evolving capabilities of LLMs. Continued research in this area is crucial to mitigate the risk of large-scale disinformation campaigns fueled by AI-generated content.
Conclusion
This paper highlights the growing threat of LLM-generated fake news and the significant challenges in detecting such content in real-world settings. The findings underscore the deceptive power of these advanced language models and the limitations of current detection methods.
The research has important implications for maintaining trust in online information and safeguarding against the spread of AI-powered misinformation. Developing more robust detection techniques, as well as exploring the broader societal impacts of this issue, will be crucial steps in addressing this emerging challenge.
As LLMs continue to advance, the need for innovative solutions, like those explored in related research on generalized nested jailbreak prompts and fake news generation and detection, will only become more pressing. This paper lays the groundwork for further investigations and the pursuit of effective, long-term strategies to combat the deceptive power of LLM-generated fake news.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
Adapting Fake News Detection to the Era of Large Language Models
Jinyan Su, Claire Cardie, Preslav Nakov
0
0
In the age of large language models (LLMs) and the widespread adoption of AI-driven content creation, the landscape of information dissemination has witnessed a paradigm shift. With the proliferation of both human-written and machine-generated real and fake news, robustly and effectively discerning the veracity of news articles has become an intricate challenge. While substantial research has been dedicated to fake news detection, this either assumes that all news articles are human-written or abruptly assumes that all machine-generated news are fake. Thus, a significant gap exists in understanding the interplay between machine-(paraphrased) real news, machine-generated fake news, human-written fake news, and human-written real news. In this paper, we study this gap by conducting a comprehensive evaluation of fake news detectors trained in various scenarios. Our primary objectives revolve around the following pivotal question: How to adapt fake news detectors to the era of LLMs? Our experiments reveal an interesting pattern that detectors trained exclusively on human-written articles can indeed perform well at detecting machine-generated fake news, but not vice versa. Moreover, due to the bias of detectors against machine-generated texts cite{su2023fake}, they should be trained on datasets with a lower machine-generated news ratio than the test set. Building on our findings, we provide a practical strategy for the development of robust fake news detectors.
4/16/2024
💬
Exploring the Potential of the Large Language Models (LLMs) in Identifying Misleading News Headlines
Md Main Uddin Rony, Md Mahfuzul Haque, Mohammad Ali, Ahmed Shatil Alam, Naeemul Hassan
0
0
In the digital age, the prevalence of misleading news headlines poses a significant challenge to information integrity, necessitating robust detection mechanisms. This study explores the efficacy of Large Language Models (LLMs) in identifying misleading versus non-misleading news headlines. Utilizing a dataset of 60 articles, sourced from both reputable and questionable outlets across health, science & tech, and business domains, we employ three LLMs- ChatGPT-3.5, ChatGPT-4, and Gemini-for classification. Our analysis reveals significant variance in model performance, with ChatGPT-4 demonstrating superior accuracy, especially in cases with unanimous annotator agreement on misleading headlines. The study emphasizes the importance of human-centered evaluation in developing LLMs that can navigate the complexities of misinformation detection, aligning technical proficiency with nuanced human judgment. Our findings contribute to the discourse on AI ethics, emphasizing the need for models that are not only technically advanced but also ethically aligned and sensitive to the subtleties of human interpretation.
5/7/2024
Can LLM-Generated Misinformation Be Detected?
Canyu Chen, Kai Shu
0
0
The advent of Large Language Models (LLMs) has made a transformative impact. However, the potential that LLMs such as ChatGPT can be exploited to generate misinformation has posed a serious concern to online safety and public trust. A fundamental research question is: will LLM-generated misinformation cause more harm than human-written misinformation? We propose to tackle this question from the perspective of detection difficulty. We first build a taxonomy of LLM-generated misinformation. Then we categorize and validate the potential real-world methods for generating misinformation with LLMs. Then, through extensive empirical investigation, we discover that LLM-generated misinformation can be harder to detect for humans and detectors compared to human-written misinformation with the same semantics, which suggests it can have more deceptive styles and potentially cause more harm. We also discuss the implications of our discovery on combating misinformation in the age of LLMs and the countermeasures.
4/16/2024
🤔
AdvPrompter: Fast Adaptive Adversarial Prompting for LLMs
Anselm Paulus, Arman Zharmagambetov, Chuan Guo, Brandon Amos, Yuandong Tian
0
0
While recently Large Language Models (LLMs) have achieved remarkable successes, they are vulnerable to certain jailbreaking attacks that lead to generation of inappropriate or harmful content. Manual red-teaming requires finding adversarial prompts that cause such jailbreaking, e.g. by appending a suffix to a given instruction, which is inefficient and time-consuming. On the other hand, automatic adversarial prompt generation often leads to semantically meaningless attacks that can easily be detected by perplexity-based filters, may require gradient information from the TargetLLM, or do not scale well due to time-consuming discrete optimization processes over the token space. In this paper, we present a novel method that uses another LLM, called the AdvPrompter, to generate human-readable adversarial prompts in seconds, $sim800times$ faster than existing optimization-based approaches. We train the AdvPrompter using a novel algorithm that does not require access to the gradients of the TargetLLM. This process alternates between two steps: (1) generating high-quality target adversarial suffixes by optimizing the AdvPrompter predictions, and (2) low-rank fine-tuning of the AdvPrompter with the generated adversarial suffixes. The trained AdvPrompter generates suffixes that veil the input instruction without changing its meaning, such that the TargetLLM is lured to give a harmful response. Experimental results on popular open source TargetLLMs show state-of-the-art results on the AdvBench dataset, that also transfer to closed-source black-box LLM APIs. Further, we demonstrate that by fine-tuning on a synthetic dataset generated by AdvPrompter, LLMs can be made more robust against jailbreaking attacks while maintaining performance, i.e. high MMLU scores.
4/29/2024