OMPO: A Unified Framework for RL under Policy and Dynamics Shifts

0

Sign in to get full access
Overview
- This paper presents a unified framework called OMPO (Occupancy Model Policy Optimization) for reinforcement learning (RL) under policy and dynamics shifts.
- The framework aims to address the challenges of RL agents performing well in environments with changing policies and dynamics, which are common in real-world applications.
- OMPO leverages a generalized occupancy model to capture the shift in policy and dynamics, enabling the RL agent to adapt and perform well in different environments.
Plain English Explanation
The paper introduces a new approach called OMPO (Occupancy Model Policy Optimization) that helps reinforcement learning (RL) agents adapt to changes in the environment. In many real-world situations, the rules of the game (the "policy") or the way the environment behaves (the "dynamics") can shift over time. This can cause problems for RL agents that have been trained on a specific set of conditions, as they may not perform well when those conditions change.
OMPO addresses this challenge by using a special type of model called a "generalized occupancy model" to keep track of how the policy and dynamics are shifting. This allows the RL agent to adjust its behavior accordingly and maintain good performance even as the environment changes around it. The paper demonstrates that OMPO can outperform other RL methods in situations with policy and dynamics shifts, making it a promising tool for real-world applications where adaptability is important.
Technical Explanation
The key innovation in this paper is the OMPO framework, which builds on the concept of generalized occupancy models to enable RL agents to adapt to changes in policy and environment dynamics. The framework consists of three main components:
- Occupancy Model: This module learns a model of the state occupancy distribution, capturing how the agent's behavior and the environment's dynamics interact.
- Policy Optimization: The policy is optimized by maximizing the expected return under the learned occupancy model, allowing the agent to adapt to shifts in policy and dynamics.
- Dynamics Model: A dynamics model is learned in parallel to capture changes in the environment's behavior, further improving the agent's adaptability.
The authors demonstrate the effectiveness of OMPO through experiments on a range of environments with policy and dynamics shifts, including robotic control tasks and language tasks. The results show that OMPO can outperform other state-of-the-art RL methods in terms of final performance and sample efficiency, highlighting its ability to handle the challenges of shifting policies and dynamics.
Critical Analysis
The OMPO framework presents a promising approach to addressing the challenge of RL in environments with changing policies and dynamics. By incorporating the occupancy model and dynamics model, the framework provides a principled way for agents to adapt to these shifts, which is a common issue in real-world applications.
However, the paper does not discuss potential limitations or areas for further research in depth. For example, it would be interesting to understand the computational and sample complexity of learning the occupancy and dynamics models, and how these scale with the complexity of the environment. Additionally, the paper could explore the robustness of OMPO to more severe or adversarial shifts in policy and dynamics, which may be important for deploying RL agents in safety-critical applications.
Furthermore, the paper could benefit from a more thorough comparison to other related approaches, such as invariance-based methods or constrained RL, to better situate the contributions of OMPO and identify its unique strengths and weaknesses.
Conclusion
The OMPO framework presented in this paper offers a principled and effective approach to reinforcement learning in environments with shifting policies and dynamics. By leveraging generalized occupancy models, the framework enables RL agents to adapt to these changes and maintain good performance, which is a crucial capability for many real-world applications.
The technical insights and experimental results showcased in the paper suggest that OMPO is a promising direction for further research and development in the field of adaptive and robust reinforcement learning. As the deployment of RL agents becomes more widespread, frameworks like OMPO will play an increasingly important role in ensuring the reliability and versatility of these systems in complex, dynamic environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
OMPO: A Unified Framework for RL under Policy and Dynamics Shifts
Yu Luo, Tianying Ji, Fuchun Sun, Jianwei Zhang, Huazhe Xu, Xianyuan Zhan
Training reinforcement learning policies using environment interaction data collected from varying policies or dynamics presents a fundamental challenge. Existing works often overlook the distribution discrepancies induced by policy or dynamics shifts, or rely on specialized algorithms with task priors, thus often resulting in suboptimal policy performances and high learning variances. In this paper, we identify a unified strategy for online RL policy learning under diverse settings of policy and dynamics shifts: transition occupancy matching. In light of this, we introduce a surrogate policy learning objective by considering the transition occupancy discrepancies and then cast it into a tractable min-max optimization problem through dual reformulation. Our method, dubbed Occupancy-Matching Policy Optimization (OMPO), features a specialized actor-critic structure equipped with a distribution discriminator and a small-size local buffer. We conduct extensive experiments based on the OpenAI Gym, Meta-World, and Panda Robots environments, encompassing policy shifts under stationary and nonstationary dynamics, as well as domain adaption. The results demonstrate that OMPO outperforms the specialized baselines from different categories in all settings. We also find that OMPO exhibits particularly strong performance when combined with domain randomization, highlighting its potential in RL-based robotics applications
Read more5/30/2024
0
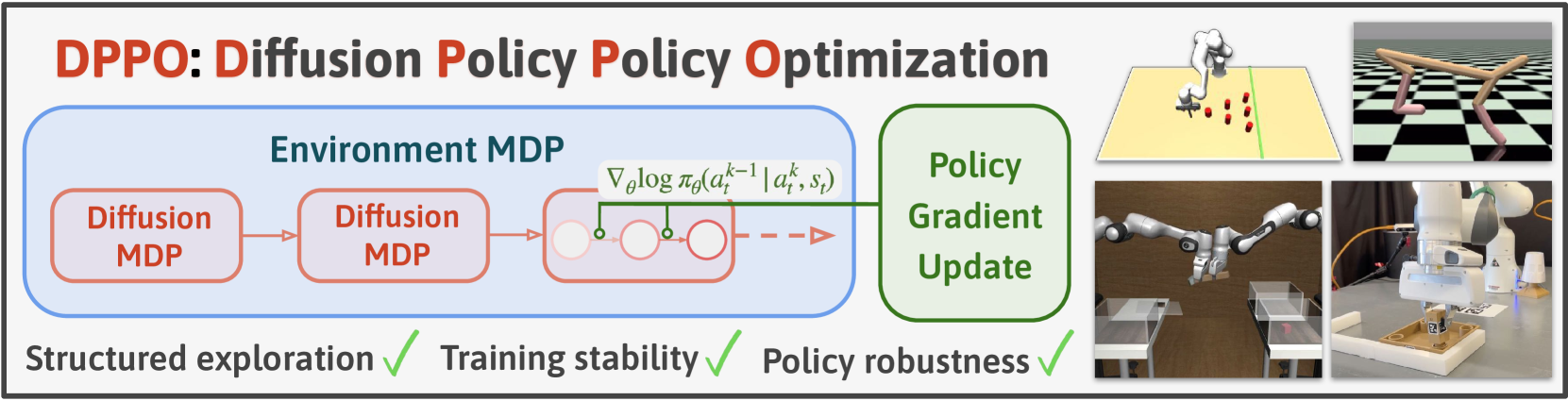
Diffusion Policy Policy Optimization
Allen Z. Ren, Justin Lidard, Lars L. Ankile, Anthony Simeonov, Pulkit Agrawal, Anirudha Majumdar, Benjamin Burchfiel, Hongkai Dai, Max Simchowitz
We introduce Diffusion Policy Policy Optimization, DPPO, an algorithmic framework including best practices for fine-tuning diffusion-based policies (e.g. Diffusion Policy) in continuous control and robot learning tasks using the policy gradient (PG) method from reinforcement learning (RL). PG methods are ubiquitous in training RL policies with other policy parameterizations; nevertheless, they had been conjectured to be less efficient for diffusion-based policies. Surprisingly, we show that DPPO achieves the strongest overall performance and efficiency for fine-tuning in common benchmarks compared to other RL methods for diffusion-based policies and also compared to PG fine-tuning of other policy parameterizations. Through experimental investigation, we find that DPPO takes advantage of unique synergies between RL fine-tuning and the diffusion parameterization, leading to structured and on-manifold exploration, stable training, and strong policy robustness. We further demonstrate the strengths of DPPO in a range of realistic settings, including simulated robotic tasks with pixel observations, and via zero-shot deployment of simulation-trained policies on robot hardware in a long-horizon, multi-stage manipulation task. Website with code: diffusion-ppo.github.io
Read more9/4/2024

0
DPO: Differential reinforcement learning with application to optimal configuration search
Chandrajit Bajaj, Minh Nguyen
Reinforcement learning (RL) with continuous state and action spaces remains one of the most challenging problems within the field. Most current learning methods focus on integral identities such as value functions to derive an optimal strategy for the learning agent. In this paper, we instead study the dual form of the original RL formulation to propose the first differential RL framework that can handle settings with limited training samples and short-length episodes. Our approach introduces Differential Policy Optimization (DPO), a pointwise and stage-wise iteration method that optimizes policies encoded by local-movement operators. We prove a pointwise convergence estimate for DPO and provide a regret bound comparable with the best current theoretical derivation. Such pointwise estimate ensures that the learned policy matches the optimal path uniformly across different steps. We then apply DPO to a class of practical RL problems with continuous state and action spaces, and which search for optimal configurations with Lagrangian rewards. DPO is easy to implement, scalable, and shows competitive results on benchmarking experiments against several popular RL methods.
Read more8/14/2024

0
Transferable Reinforcement Learning via Generalized Occupancy Models
Chuning Zhu, Xinqi Wang, Tyler Han, Simon S. Du, Abhishek Gupta
Intelligent agents must be generalists, capable of quickly adapting to various tasks. In reinforcement learning (RL), model-based RL learns a dynamics model of the world, in principle enabling transfer to arbitrary reward functions through planning. However, autoregressive model rollouts suffer from compounding error, making model-based RL ineffective for long-horizon problems. Successor features offer an alternative by modeling a policy's long-term state occupancy, reducing policy evaluation under new tasks to linear reward regression. Yet, policy improvement with successor features can be challenging. This work proposes a novel class of models, i.e., generalized occupancy models (GOMs), that learn a distribution of successor features from a stationary dataset, along with a policy that acts to realize different successor features. These models can quickly select the optimal action for arbitrary new tasks. By directly modeling long-term outcomes in the dataset, GOMs avoid compounding error while enabling rapid transfer across reward functions. We present a practical instantiation of GOMs using diffusion models and show their efficacy as a new class of transferable models, both theoretically and empirically across various simulated robotics problems. Videos and code at https://weirdlabuw.github.io/gom/.
Read more5/30/2024