AdaptiveFusion: Adaptive Multi-Modal Multi-View Fusion for 3D Human Body Reconstruction

0
Sign in to get full access
Overview
- The paper proposes a novel 3D human body reconstruction method called AdaptiveFusion that uses adaptive multi-modal multi-view fusion.
- It can reconstruct accurate 3D human body models from multi-view images captured by uncalibrated cameras.
- The method adaptively fuses information from different modalities and views to handle occlusions and various scene complexities.
Plain English Explanation
AdaptiveFusion: Adaptive Multi-Modal Multi-View Fusion for 3D Human Body Reconstruction is a new technique for creating 3D models of human bodies from a set of images taken from different angles.
The key idea is to adaptively combine information from multiple camera views and sensor modalities (e.g. depth, color) to handle tricky situations like when parts of the body are blocked from view. This allows the system to reconstruct an accurate 3D model even when the inputs have missing or incomplete information.
For example, if one camera can't see the person's legs because they are behind a desk, the system will use the information from the other camera views and sensor data to "fill in the blanks" and create a complete 3D model.
The adaptive fusion part means the system dynamically decides how much to weight the different inputs based on their reliability and relevance to the current situation. This makes the 3D reconstruction more robust to challenging real-world conditions.
Technical Explanation
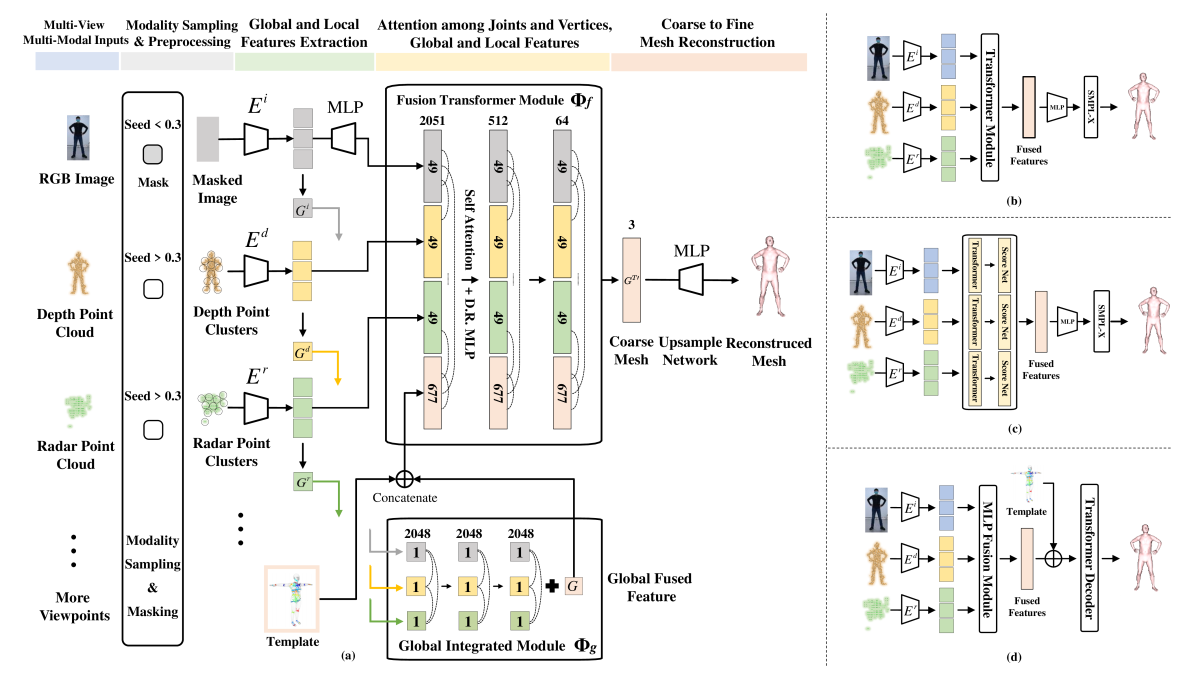
AdaptiveFusion is a deep learning-based approach for 3D human body reconstruction from multi-view, multi-modal inputs. The key technical contributions are:
-
Adaptive Fusion Module: This module dynamically adjusts the weights assigned to different camera views and sensor modalities based on their reliability and relevance to the current scene. This allows the system to handle partial occlusions and other complexities.
-
Multi-View Encoding: The system encodes the input images from multiple views into a shared latent representation using a convolutional neural network. This helps capture the 3D structure of the human body.
-
Weakly-Supervised Training: The model is trained using only 2D annotations (e.g. keypoints, silhouettes) without requiring expensive 3D ground truth data. This makes the approach more practical for real-world deployment.
The researchers evaluate AdaptiveFusion on standard 3D human reconstruction benchmarks and demonstrate state-of-the-art performance, particularly in challenging scenarios with occlusions and mixed camera views.
Critical Analysis
The AdaptiveFusion paper introduces an interesting and practical approach to 3D human body reconstruction. The adaptive fusion mechanism is a clever way to handle real-world complexities and missing data.
However, the paper does not discuss the computational efficiency of the approach, which could be an important consideration for real-time applications. Additionally, the weakly-supervised training strategy requires further investigation to ensure the reconstructed 3D models are sufficiently accurate for certain use cases.
It would also be valuable to see how AdaptiveFusion compares to other multi-view fusion methods, such as Multi-View Pose Fusion, MUC, and MV2DFusion, in terms of both accuracy and computational efficiency.
Conclusion
AdaptiveFusion presents a novel approach to 3D human body reconstruction that adaptively fuses information from multiple camera views and sensor modalities. This allows the system to handle challenging real-world conditions like partial occlusions, making it a promising technique for applications such as human mesh recovery from arbitrary multi-view scenarios. Further research is needed to address the computational efficiency and fully understand the approach's strengths and limitations compared to other state-of-the-art methods.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AdaptiveFusion: Adaptive Multi-Modal Multi-View Fusion for 3D Human Body Reconstruction
Anjun Chen, Xiangyu Wang, Zhi Xu, Kun Shi, Yan Qin, Yuchi Huo, Jiming Chen, Qi Ye
Recent advancements in sensor technology and deep learning have led to significant progress in 3D human body reconstruction. However, most existing approaches rely on data from a specific sensor, which can be unreliable due to the inherent limitations of individual sensing modalities. On the other hand, existing multi-modal fusion methods generally require customized designs based on the specific sensor combinations or setups, which limits the flexibility and generality of these methods. Furthermore, conventional point-image projection-based and Transformer-based fusion networks are susceptible to the influence of noisy modalities and sensor poses. To address these limitations and achieve robust 3D human body reconstruction in various conditions, we propose AdaptiveFusion, a generic adaptive multi-modal multi-view fusion framework that can effectively incorporate arbitrary combinations of uncalibrated sensor inputs. By treating different modalities from various viewpoints as equal tokens, and our handcrafted modality sampling module by leveraging the inherent flexibility of Transformer models, AdaptiveFusion is able to cope with arbitrary numbers of inputs and accommodate noisy modalities with only a single training network. Extensive experiments on large-scale human datasets demonstrate the effectiveness of AdaptiveFusion in achieving high-quality 3D human body reconstruction in various environments. In addition, our method achieves superior accuracy compared to state-of-the-art fusion methods.
Read more9/10/2024

0
Multi-view Pose Fusion for Occlusion-Aware 3D Human Pose Estimation
Laura Bragagnolo, Matteo Terreran, Davide Allegro, Stefano Ghidoni
Robust 3D human pose estimation is crucial to ensure safe and effective human-robot collaboration. Accurate human perception,however, is particularly challenging in these scenarios due to strong occlusions and limited camera viewpoints. Current 3D human pose estimation approaches are rather vulnerable in such conditions. In this work we present a novel approach for robust 3D human pose estimation in the context of human-robot collaboration. Instead of relying on noisy 2D features triangulation, we perform multi-view fusion on 3D skeletons provided by absolute monocular methods. Accurate 3D pose estimation is then obtained via reprojection error optimization, introducing limbs length symmetry constraints. We evaluate our approach on the public dataset Human3.6M and on a novel version Human3.6M-Occluded, derived adding synthetic occlusions on the camera views with the purpose of testing pose estimation algorithms under severe occlusions. We further validate our method on real human-robot collaboration workcells, in which we strongly surpass current 3D human pose estimation methods. Our approach outperforms state-of-the-art multi-view human pose estimation techniques and demonstrates superior capabilities in handling challenging scenarios with strong occlusions, representing a reliable and effective solution for real human-robot collaboration setups.
Read more8/29/2024

0
MUC: Mixture of Uncalibrated Cameras for Robust 3D Human Body Reconstruction
Yitao Zhu, Sheng Wang, Mengjie Xu, Zixu Zhuang, Zhixin Wang, Kaidong Wang, Han Zhang, Qian Wang
Multiple cameras can provide comprehensive multi-view video coverage of a person. Fusing this multi-view data is crucial for tasks like behavioral analysis, although it traditionally requires camera calibration, a process that is often complex. Moreover, previous studies have overlooked the challenges posed by self-occlusion under multiple views and the continuity of human body shape estimation. In this study, we introduce a method to reconstruct the 3D human body from multiple uncalibrated camera views. Initially, we utilize a pre-trained human body encoder to process each camera view individually, enabling the reconstruction of human body models and parameters for each view along with predicted camera positions. Rather than merely averaging the models across views, we develop a neural network trained to assign weights to individual views for all human body joints, based on the estimated distribution of joint distances from each camera. Additionally, we focus on the mesh surface of the human body for dynamic fusion, allowing for the seamless integration of facial expressions and body shape into a unified human body model. Our method has shown excellent performance in reconstructing the human body on two public datasets, advancing beyond previous work from the SMPL model to the SMPL-X model. This extension incorporates more complex hand poses and facial expressions, enhancing the detail and accuracy of the reconstructions. Crucially, it supports the flexible ad-hoc deployment of any number of cameras, offering significant potential for various applications. Our code is available at https://github.com/AbsterZhu/MUC.
Read more8/27/2024
0
MV2DFusion: Leveraging Modality-Specific Object Semantics for Multi-Modal 3D Detection
Zitian Wang, Zehao Huang, Yulu Gao, Naiyan Wang, Si Liu
The rise of autonomous vehicles has significantly increased the demand for robust 3D object detection systems. While cameras and LiDAR sensors each offer unique advantages--cameras provide rich texture information and LiDAR offers precise 3D spatial data--relying on a single modality often leads to performance limitations. This paper introduces MV2DFusion, a multi-modal detection framework that integrates the strengths of both worlds through an advanced query-based fusion mechanism. By introducing an image query generator to align with image-specific attributes and a point cloud query generator, MV2DFusion effectively combines modality-specific object semantics without biasing toward one single modality. Then the sparse fusion process can be accomplished based on the valuable object semantics, ensuring efficient and accurate object detection across various scenarios. Our framework's flexibility allows it to integrate with any image and point cloud-based detectors, showcasing its adaptability and potential for future advancements. Extensive evaluations on the nuScenes and Argoverse2 datasets demonstrate that MV2DFusion achieves state-of-the-art performance, particularly excelling in long-range detection scenarios.
Read more8/13/2024