MUC: Mixture of Uncalibrated Cameras for Robust 3D Human Body Reconstruction

0

Sign in to get full access
Overview
- Paper presents a novel approach called MUC (Mixture of Uncalibrated Cameras) for robust 3D human body reconstruction using multiple uncalibrated cameras
- Key innovations include handling uncalibrated cameras, jointly optimizing camera parameters and body shape/pose, and leveraging explicit geometry constraints
- Experiments on challenging datasets demonstrate the method's strong performance compared to prior art
Plain English Explanation
The research paper introduces a new technique called MUC (Mixture of Uncalibrated Cameras) that can reconstruct detailed 3D models of human bodies using multiple cameras without requiring the cameras to be precisely calibrated. This is a significant advancement over previous methods that relied on carefully calibrated camera setups.
The key innovations in MUC include:
- Handling Uncalibrated Cameras: The method can work with cameras that have unknown or inaccurate calibration parameters, making it much easier to set up and use in real-world scenarios.
- Joint Optimization: MUC simultaneously optimizes the camera parameters along with the 3D shape and pose of the human body, allowing the different components to cooperatively improve each other.
- Geometry Constraints: The approach incorporates explicit geometric constraints to further improve the accuracy and robustness of the 3D reconstruction.
By addressing these technical challenges, the MUC method is able to produce high-quality 3D human models from multi-view video captured with imperfect camera setups. This represents an important advancement over prior work that required carefully calibrated and synchronized camera arrays.
Technical Explanation
The core of the MUC method is a joint optimization framework that simultaneously estimates the 3D human body shape and pose along with the parameters of the uncalibrated cameras. This differs from previous multi-view 3D human reconstruction approaches that assumed the camera parameters were known a priori.
The optimization objective incorporates several key terms:
- Reprojection Error: Minimizing the distance between the projected 3D body joints and their 2D observations in each camera view.
- Shape and Pose Priors: Regularizing the 3D body shape and pose to match statistical priors learned from 3D human body datasets.
- Geometric Constraints: Enforcing constraints on the relative positions and orientations of body parts to improve reconstruction accuracy.
- Camera Parameter Updates: Jointly optimizing the intrinsic and extrinsic parameters of each camera to align with the 3D body reconstruction.
By optimizing these terms together, the method is able to progressively refine both the 3D human model and the camera calibrations, leading to robust and accurate reconstructions even with imperfect camera setups.
The authors evaluate MUC on challenging multi-view 3D human reconstruction benchmarks, demonstrating significant performance improvements over prior state-of-the-art methods. They also show the method's ability to handle a wide range of camera configurations, including those with significant distortion or missing calibration parameters.
Critical Analysis
The MUC method represents an important advance in multi-view 3D human reconstruction, as it relaxes the requirement for precisely calibrated camera setups that has limited the practical applicability of many previous techniques. However, the authors acknowledge that their approach still has some limitations.
One potential issue is that the joint optimization of camera parameters and 3D body models may be sensitive to initialization and could converge to local minima in some cases. The authors suggest further research into more robust optimization strategies to address this concern.
Additionally, while MUC can handle a variety of uncalibrated camera configurations, the performance may still degrade as the number of cameras or the quality of the camera calibrations decreases. Exploring ways to further improve the method's robustness to severely uncalibrated or sparse camera setups could be a fruitful direction for future work.
Overall, the MUC method represents a significant step forward in making multi-view 3D human reconstruction more practical and accessible, with the potential to enable a wide range of applications in areas like gaming, animation, and behavior analysis. The authors have made a valuable contribution to the field, and their work provides a strong foundation for continued research and development in this area.
Conclusion
The MUC method presented in this paper addresses a key challenge in multi-view 3D human body reconstruction by enabling the use of uncalibrated camera setups. Through joint optimization of camera parameters, body shape, and body pose, the method can produce accurate 3D human models even when the camera calibration information is incomplete or inaccurate.
The authors demonstrate the effectiveness of their approach through comprehensive experiments, showing significant performance improvements over prior state-of-the-art methods. While the method has some limitations, it represents an important advance that could enable a wide range of practical applications in areas like virtual reality, animation, and human behavior analysis.
Overall, the MUC method is a valuable contribution to the field of 3D human reconstruction, and the authors' work provides a solid foundation for further research and development in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MUC: Mixture of Uncalibrated Cameras for Robust 3D Human Body Reconstruction
Yitao Zhu, Sheng Wang, Mengjie Xu, Zixu Zhuang, Zhixin Wang, Kaidong Wang, Han Zhang, Qian Wang
Multiple cameras can provide comprehensive multi-view video coverage of a person. Fusing this multi-view data is crucial for tasks like behavioral analysis, although it traditionally requires camera calibration, a process that is often complex. Moreover, previous studies have overlooked the challenges posed by self-occlusion under multiple views and the continuity of human body shape estimation. In this study, we introduce a method to reconstruct the 3D human body from multiple uncalibrated camera views. Initially, we utilize a pre-trained human body encoder to process each camera view individually, enabling the reconstruction of human body models and parameters for each view along with predicted camera positions. Rather than merely averaging the models across views, we develop a neural network trained to assign weights to individual views for all human body joints, based on the estimated distribution of joint distances from each camera. Additionally, we focus on the mesh surface of the human body for dynamic fusion, allowing for the seamless integration of facial expressions and body shape into a unified human body model. Our method has shown excellent performance in reconstructing the human body on two public datasets, advancing beyond previous work from the SMPL model to the SMPL-X model. This extension incorporates more complex hand poses and facial expressions, enhancing the detail and accuracy of the reconstructions. Crucially, it supports the flexible ad-hoc deployment of any number of cameras, offering significant potential for various applications. Our code is available at https://github.com/AbsterZhu/MUC.
Read more8/27/2024

0
Human Mesh Recovery from Arbitrary Multi-view Images
Xiaoben Li, Mancheng Meng, Ziyan Wu, Terrence Chen, Fan Yang, Dinggang Shen
Human mesh recovery from arbitrary multi-view images involves two characteristics: the arbitrary camera poses and arbitrary number of camera views. Because of the variability, designing a unified framework to tackle this task is challenging. The challenges can be summarized as the dilemma of being able to simultaneously estimate arbitrary camera poses and recover human mesh from arbitrary multi-view images while maintaining flexibility. To solve this dilemma, we propose a divide and conquer framework for Unified Human Mesh Recovery (U-HMR) from arbitrary multi-view images. In particular, U-HMR consists of a decoupled structure and two main components: camera and body decoupling (CBD), camera pose estimation (CPE), and arbitrary view fusion (AVF). As camera poses and human body mesh are independent of each other, CBD splits the estimation of them into two sub-tasks for two individual sub-networks (ie, CPE and AVF) to handle respectively, thus the two sub-tasks are disentangled. In CPE, since each camera pose is unrelated to the others, we adopt a shared MLP to process all views in a parallel way. In AVF, in order to fuse multi-view information and make the fusion operation independent of the number of views, we introduce a transformer decoder with a SMPL parameters query token to extract cross-view features for mesh recovery. To demonstrate the efficacy and flexibility of the proposed framework and effect of each component, we conduct extensive experiments on three public datasets: Human3.6M, MPI-INF-3DHP, and TotalCapture.
Read more6/18/2024
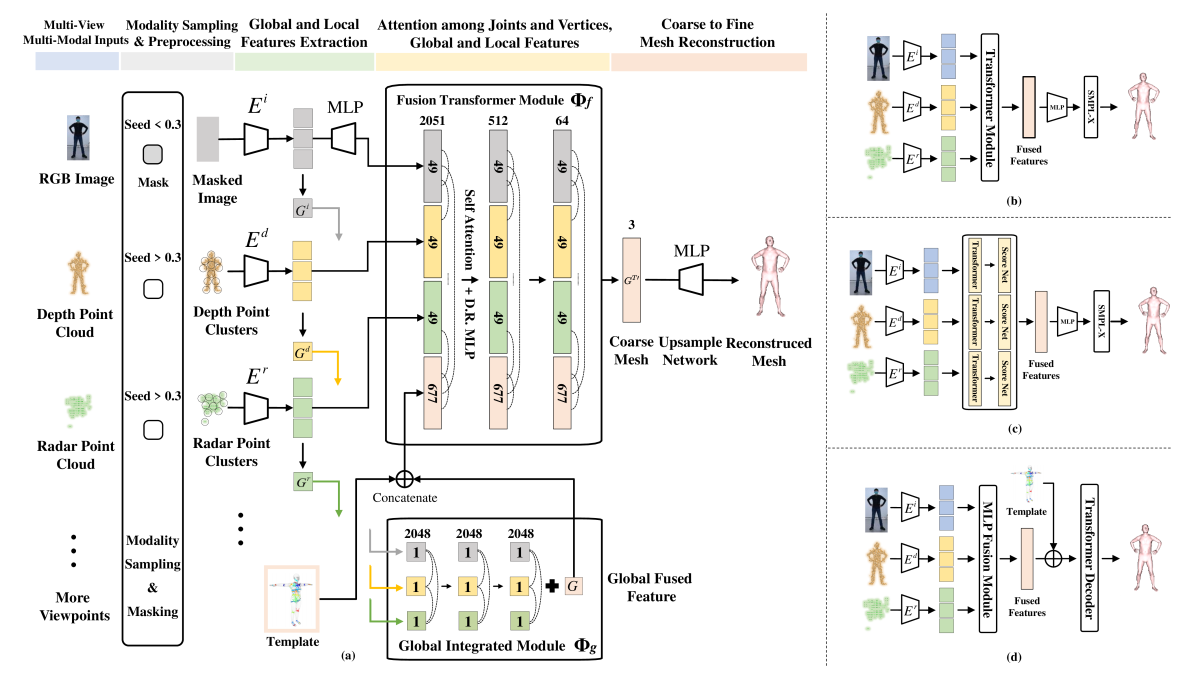
0
AdaptiveFusion: Adaptive Multi-Modal Multi-View Fusion for 3D Human Body Reconstruction
Anjun Chen, Xiangyu Wang, Zhi Xu, Kun Shi, Yan Qin, Yuchi Huo, Jiming Chen, Qi Ye
Recent advancements in sensor technology and deep learning have led to significant progress in 3D human body reconstruction. However, most existing approaches rely on data from a specific sensor, which can be unreliable due to the inherent limitations of individual sensing modalities. On the other hand, existing multi-modal fusion methods generally require customized designs based on the specific sensor combinations or setups, which limits the flexibility and generality of these methods. Furthermore, conventional point-image projection-based and Transformer-based fusion networks are susceptible to the influence of noisy modalities and sensor poses. To address these limitations and achieve robust 3D human body reconstruction in various conditions, we propose AdaptiveFusion, a generic adaptive multi-modal multi-view fusion framework that can effectively incorporate arbitrary combinations of uncalibrated sensor inputs. By treating different modalities from various viewpoints as equal tokens, and our handcrafted modality sampling module by leveraging the inherent flexibility of Transformer models, AdaptiveFusion is able to cope with arbitrary numbers of inputs and accommodate noisy modalities with only a single training network. Extensive experiments on large-scale human datasets demonstrate the effectiveness of AdaptiveFusion in achieving high-quality 3D human body reconstruction in various environments. In addition, our method achieves superior accuracy compared to state-of-the-art fusion methods.
Read more9/10/2024

0
COSMU: Complete 3D human shape from monocular unconstrained images
Marco Pesavento, Marco Volino, Adrian Hilton
We present a novel framework to reconstruct complete 3D human shapes from a given target image by leveraging monocular unconstrained images. The objective of this work is to reproduce high-quality details in regions of the reconstructed human body that are not visible in the input target. The proposed methodology addresses the limitations of existing approaches for reconstructing 3D human shapes from a single image, which cannot reproduce shape details in occluded body regions. The missing information of the monocular input can be recovered by using multiple views captured from multiple cameras. However, multi-view reconstruction methods necessitate accurately calibrated and registered images, which can be challenging to obtain in real-world scenarios. Given a target RGB image and a collection of multiple uncalibrated and unregistered images of the same individual, acquired using a single camera, we propose a novel framework to generate complete 3D human shapes. We introduce a novel module to generate 2D multi-view normal maps of the person registered with the target input image. The module consists of body part-based reference selection and body part-based registration. The generated 2D normal maps are then processed by a multi-view attention-based neural implicit model that estimates an implicit representation of the 3D shape, ensuring the reproduction of details in both observed and occluded regions. Extensive experiments demonstrate that the proposed approach estimates higher quality details in the non-visible regions of the 3D clothed human shapes compared to related methods, without using parametric models.
Read more7/16/2024