Advancing Long-Term Multi-Energy Load Forecasting with Patchformer: A Patch and Transformer-Based Approach
2404.10458
0
0
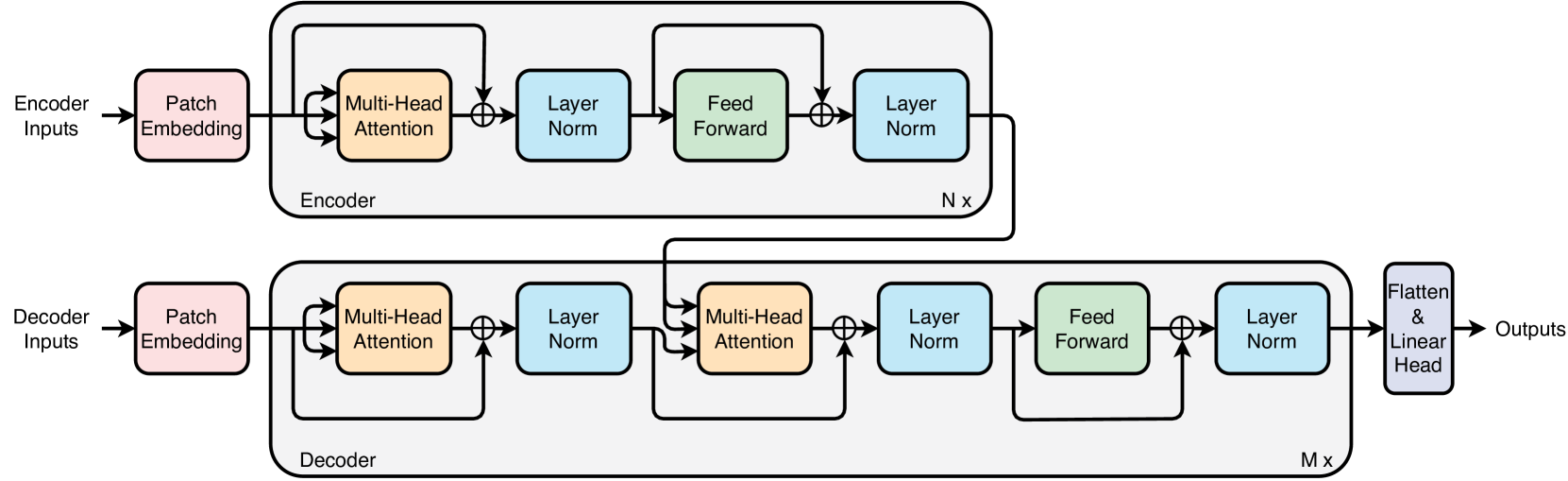
Abstract
In the context of increasing demands for long-term multi-energy load forecasting in real-world applications, this paper introduces Patchformer, a novel model that integrates patch embedding with encoder-decoder Transformer-based architectures. To address the limitation in existing Transformer-based models, which struggle with intricate temporal patterns in long-term forecasting, Patchformer employs patch embedding, which predicts multivariate time-series data by separating it into multiple univariate data and segmenting each of them into multiple patches. This method effectively enhances the model's ability to capture local and global semantic dependencies. The numerical analysis shows that the Patchformer obtains overall better prediction accuracy in both multivariate and univariate long-term forecasting on the novel Multi-Energy dataset and other benchmark datasets. In addition, the positive effect of the interdependence among energy-related products on the performance of long-term time-series forecasting across Patchformer and other compared models is discovered, and the superiority of the Patchformer against other models is also demonstrated, which presents a significant advancement in handling the interdependence and complexities of long-term multi-energy forecasting. Lastly, Patchformer is illustrated as the only model that follows the positive correlation between model performance and the length of the past sequence, which states its ability to capture long-range past local semantic information.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents Patchformer, a novel approach for long-term multi-energy load forecasting that combines patch-based modeling and transformer-based architectures.
- Patchformer aims to capture both local and global dependencies in complex multi-energy time series data, improving upon existing methods.
- The authors evaluate Patchformer on several real-world datasets, demonstrating its superior performance compared to state-of-the-art baselines.
Plain English Explanation
Forecasting energy usage over long time periods is a challenging problem, as it requires understanding complex patterns and relationships in the data. The paper introduces a new technique called Patchformer that uses a combination of patch-based modeling and transformer-based architectures to tackle this challenge.
Patch-based modeling involves breaking down the input data into smaller, overlapping "patches" and processing them independently. This allows the model to capture local patterns and details. The transformer architecture, on the other hand, is well-suited for understanding global dependencies and relationships in the data.
By combining these two approaches, Patchformer can effectively model both the local and global aspects of multi-energy time series data, leading to improved forecasting accuracy compared to existing methods. The authors evaluate Patchformer on real-world datasets and show that it outperforms other state-of-the-art models.
Technical Explanation
The paper proposes a novel architecture called Patchformer for long-term multi-energy load forecasting. Patchformer integrates patch-based modeling and transformer-based architectures to capture both local and global dependencies in complex multi-energy time series data.
The patch-based component of Patchformer involves dividing the input time series into smaller, overlapping patches, which are then processed independently. This allows the model to focus on local patterns and details within the data. The transformer-based component, on the other hand, is responsible for understanding the global relationships and dependencies across the entire time series.
The authors evaluate Patchformer on several real-world multi-energy datasets and compare its performance to state-of-the-art baselines, including TimGPT, Forecasting Electricity Market Signals via Generative AI, and MinusFormer. The results demonstrate that Patchformer outperforms these existing methods, showcasing its effectiveness in capturing the complex patterns and dependencies inherent in multi-energy time series data.
Critical Analysis
The paper presents a compelling approach to long-term multi-energy load forecasting, leveraging the strengths of both patch-based modeling and transformer-based architectures. However, the authors acknowledge several limitations and areas for further research.
One potential concern is the computational complexity of the Patchformer model, as the patch-based processing and transformer-based components may increase the overall model size and training time. The authors suggest exploring ways to optimize the architecture and reduce the computational burden, which would be beneficial for practical deployment.
Additionally, the paper focuses on evaluating Patchformer on a limited set of real-world datasets. Further testing on a more diverse range of datasets, including data from different domains or with varying characteristics, would help to better understand the generalizability and robustness of the proposed approach.
The authors also mention the need to investigate the interpretability of Patchformer, as understanding the model's decision-making process can be crucial for real-world applications. Incorporating techniques for model explanation and interpretability could enhance the trust and adoption of the proposed method.
Conclusion
The Patchformer model presented in this paper offers a promising approach to long-term multi-energy load forecasting. By combining patch-based modeling and transformer-based architectures, the model can effectively capture both local and global dependencies in complex time series data, resulting in improved forecasting accuracy.
The authors' evaluation of Patchformer on real-world datasets demonstrates its superiority over state-of-the-art baselines, highlighting the potential benefits of this hybrid approach. However, further research is needed to address the computational complexity, explore the model's generalizability, and enhance its interpretability.
If successful, the Patchformer model could have significant implications for the energy industry, enabling more accurate long-term forecasting of energy demand and load, which is crucial for efficient resource planning and management.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Enhanced LFTSformer: A Novel Long-Term Financial Time Series Prediction Model Using Advanced Feature Engineering and the DS Encoder Informer Architecture
Jianan Zhang, Hongyi Duan
0
0
This study presents a groundbreaking model for forecasting long-term financial time series, termed the Enhanced LFTSformer. The model distinguishes itself through several significant innovations: (1) VMD-MIC+FE Feature Engineering: The incorporation of sophisticated feature engineering techniques, specifically through the integration of Variational Mode Decomposition (VMD), Maximal Information Coefficient (MIC), and feature engineering (FE) methods, enables comprehensive perception and extraction of deep-level features from complex and variable financial datasets. (2) DS Encoder Informer: The architecture of the original Informer has been modified by adopting a Stacked Informer structure in the encoder, and an innovative introduction of a multi-head decentralized sparse attention mechanism, referred to as the Distributed Informer. This modification has led to a reduction in the number of attention blocks, thereby enhancing both the training accuracy and speed. (3) GC Enhanced Adam & Dynamic Loss Function: The deployment of a Gradient Clipping-enhanced Adam optimization algorithm and a dynamic loss function represents a pioneering approach within the domain of financial time series prediction. This novel methodology optimizes model performance and adapts more dynamically to evolving data patterns. Systematic experimentation on a range of benchmark stock market datasets demonstrates that the Enhanced LFTSformer outperforms traditional machine learning models and other Informer-based architectures in terms of prediction accuracy, adaptability, and generality. Furthermore, the paper identifies potential avenues for future enhancements, with a particular focus on the identification and quantification of pivotal impacting events and news. This is aimed at further refining the predictive efficacy of the model.
4/19/2024
➖
Learning to Embed Time Series Patches Independently
Seunghan Lee, Taeyoung Park, Kibok Lee
0
0
Masked time series modeling has recently gained much attention as a self-supervised representation learning strategy for time series. Inspired by masked image modeling in computer vision, recent works first patchify and partially mask out time series, and then train Transformers to capture the dependencies between patches by predicting masked patches from unmasked patches. However, we argue that capturing such patch dependencies might not be an optimal strategy for time series representation learning; rather, learning to embed patches independently results in better time series representations. Specifically, we propose to use 1) the simple patch reconstruction task, which autoencode each patch without looking at other patches, and 2) the simple patch-wise MLP that embeds each patch independently. In addition, we introduce complementary contrastive learning to hierarchically capture adjacent time series information efficiently. Our proposed method improves time series forecasting and classification performance compared to state-of-the-art Transformer-based models, while it is more efficient in terms of the number of parameters and training/inference time. Code is available at this repository: https://github.com/seunghan96/pits.
5/3/2024
🔎
Integrating Mamba and Transformer for Long-Short Range Time Series Forecasting
Xiongxiao Xu, Yueqing Liang, Baixiang Huang, Zhiling Lan, Kai Shu
0
0
Time series forecasting is an important problem and plays a key role in a variety of applications including weather forecasting, stock market, and scientific simulations. Although transformers have proven to be effective in capturing dependency, its quadratic complexity of attention mechanism prevents its further adoption in long-range time series forecasting, thus limiting them attend to short-range range. Recent progress on state space models (SSMs) have shown impressive performance on modeling long range dependency due to their subquadratic complexity. Mamba, as a representative SSM, enjoys linear time complexity and has achieved strong scalability on tasks that requires scaling to long sequences, such as language, audio, and genomics. In this paper, we propose to leverage a hybrid framework Mambaformer that internally combines Mamba for long-range dependency, and Transformer for short range dependency, for long-short range forecasting. To the best of our knowledge, this is the first paper to combine Mamba and Transformer architecture in time series data. We investigate possible hybrid architectures to combine Mamba layer and attention layer for long-short range time series forecasting. The comparative study shows that the Mambaformer family can outperform Mamba and Transformer in long-short range time series forecasting problem. The code is available at https://github.com/XiongxiaoXu/Mambaformerin-Time-Series.
4/24/2024
ShadowMaskFormer: Mask Augmented Patch Embeddings for Shadow Removal
Zhuohao Li, Guoyang Xie, Guannan Jiang, Zhichao Lu
0
0
Transformer recently emerged as the de facto model for computer vision tasks and has also been successfully applied to shadow removal. However, these existing methods heavily rely on intricate modifications to the attention mechanisms within the transformer blocks while using a generic patch embedding. As a result, it often leads to complex architectural designs requiring additional computation resources. In this work, we aim to explore the efficacy of incorporating shadow information within the early processing stage. Accordingly, we propose a transformer-based framework with a novel patch embedding that is tailored for shadow removal, dubbed ShadowMaskFormer. Specifically, we present a simple and effective mask-augmented patch embedding to integrate shadow information and promote the model's emphasis on acquiring knowledge for shadow regions. Extensive experiments conducted on the ISTD, ISTD+, and SRD benchmark datasets demonstrate the efficacy of our method against state-of-the-art approaches while using fewer model parameters.
5/1/2024