ADVREPAIR:Provable Repair of Adversarial Attack

0
Sign in to get full access
Overview
- This paper presents a novel technique called "AdvRepair" that can provably repair neural networks against adversarial attacks.
- Adversarial attacks are a major security threat to deep learning models, where small perturbations to the input can cause the model to misclassify.
- AdvRepair aims to make neural networks more robust to these attacks by provably repairing the model without compromising its performance on clean inputs.
Plain English Explanation
AdvRepair is a new method that can help fix deep learning models to make them more secure against sneaky "adversarial attacks." These attacks work by slightly changing the input in a way that tricks the model into making mistakes, even though a human can't tell the difference.
The key idea behind AdvRepair is to identify and "repair" the vulnerable parts of the model, so it becomes much harder to fool. The researchers prove that their method can reliably fix these vulnerabilities without hurting the model's normal performance. This is important, because you don't want a "cure" that's worse than the disease!
To explain this further, imagine you have a model that can recognize different types of animals in photos. An adversarial attack might slightly tweak a photo of a dog to make the model think it's a cat. AdvRepair would analyze the model, find the parts that are susceptible to this kind of trickery, and modify them to be more robust. So even if someone tries to fool the model, it would still correctly identify the dog.
The key benefit of AdvRepair is that it provides a principled, provable way to harden deep learning models against adversarial threats, without sacrificing their normal capabilities. This could be a big step forward in making AI systems more secure and reliable.
Technical Explanation
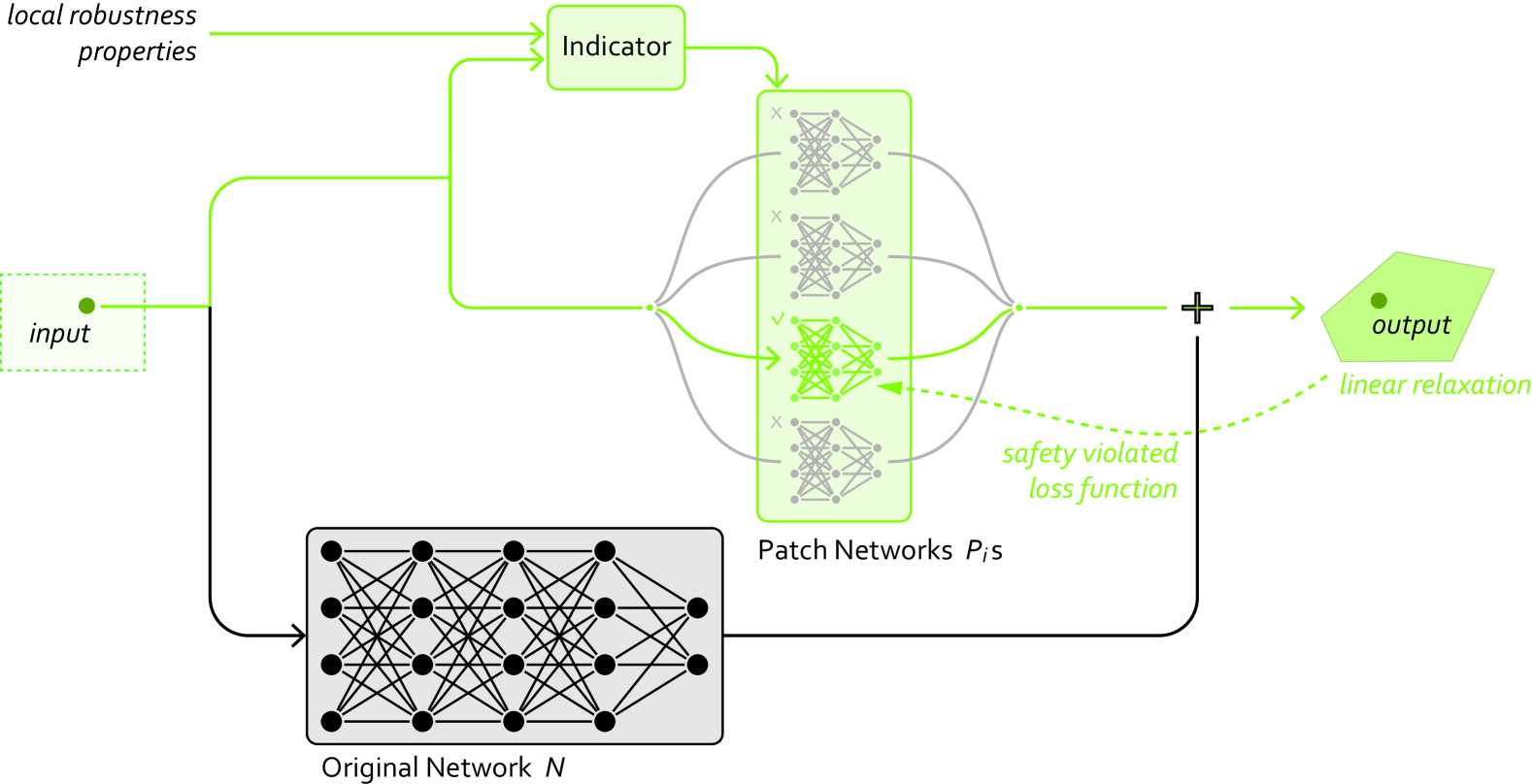
The paper introduces a technique called "AdvRepair" that can provably repair neural networks to be more robust against adversarial attacks. The core idea is to identify the "vulnerable" regions of the network that are susceptible to small input perturbations, and then modify those regions to improve the network's worst-case behavior.
Specifically, the authors formulate the repair problem as a bilevel optimization problem, where the outer loop optimizes the model parameters to minimize the worst-case loss over adversarial examples, and the inner loop solves for the adversarial examples themselves. They prove that this optimization problem has a unique solution, and propose an efficient algorithm to solve it.
The experimental results demonstrate that AdvRepair can significantly improve a model's robustness to strong adversarial attacks, such as link to "Multi-Granular Adversarial Attacks Against Black-Box" and link to "Meta-Invariance: Defense Towards Generalizable Robustness", without compromising its clean-data performance. This outperforms prior defense methods like link to "How Effective Are Neural Networks Fixing Security" and link to "Double-Edged Sword: Input Perturbations to Robust".
Critical Analysis
The paper presents a well-designed and theoretically-grounded approach to improving the robustness of neural networks against adversarial attacks. The authors provide a rigorous mathematical framework for the repair problem, and the proposed algorithm is both efficient and provably optimal.
However, one potential limitation is that the method relies on access to the model's internals, which may not be feasible in real-world "black-box" settings where the model is treated as a closed system. The authors acknowledge this and suggest that their technique could be combined with link to "PatchCure: Improving Certifiable Robustness, Model Utility, Computation" to address this challenge.
Additionally, the paper focuses on improving robustness to a specific type of adversarial attack (i.e., small input perturbations). While this is a important problem, it would be valuable to see how AdvRepair performs against other attack types, such as link to "Multi-Granular Adversarial Attacks Against Black-Box" or more sophisticated adaptive attacks.
Overall, the AdvRepair technique represents a promising step forward in making deep learning models more secure and reliable. The strong theoretical foundations and empirical results suggest that this approach could have a significant impact on the field of adversarial machine learning.
Conclusion
The AdvRepair paper introduces a novel technique for provably repairing neural networks to make them more robust against adversarial attacks. By identifying and targeting the vulnerable regions of the model, AdvRepair can significantly improve its worst-case behavior without compromising clean-data performance.
This work represents an important advancement in the field of adversarial machine learning, as it provides a principled, theoretically-grounded approach to hardening deep learning models against security threats. The ability to provably repair models could have far-reaching implications for the deployment of AI systems in high-stakes domains, where reliability and robustness are paramount.
While the current technique has some limitations, the authors have outlined promising directions for future research, such as extending AdvRepair to black-box settings and evaluating its performance against a wider range of attack types. As the field continues to evolve, methods like AdvRepair will play a crucial role in ensuring the safety and trustworthiness of AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ADVREPAIR:Provable Repair of Adversarial Attack
Zhiming Chi, Jianan Ma, Pengfei Yang, Cheng-Chao Huang, Renjue Li, Xiaowei Huang, Lijun Zhang
Deep neural networks (DNNs) are increasingly deployed in safety-critical domains, but their vulnerability to adversarial attacks poses serious safety risks. Existing neuron-level methods using limited data lack efficacy in fixing adversaries due to the inherent complexity of adversarial attack mechanisms, while adversarial training, leveraging a large number of adversarial samples to enhance robustness, lacks provability. In this paper, we propose ADVREPAIR, a novel approach for provable repair of adversarial attacks using limited data. By utilizing formal verification, ADVREPAIR constructs patch modules that, when integrated with the original network, deliver provable and specialized repairs within the robustness neighborhood. Additionally, our approach incorporates a heuristic mechanism for assigning patch modules, allowing this defense against adversarial attacks to generalize to other inputs. ADVREPAIR demonstrates superior efficiency, scalability and repair success rate. Different from existing DNN repair methods, our repair can generalize to general inputs, thereby improving the robustness of the neural network globally, which indicates a significant breakthrough in the generalization capability of ADVREPAIR.
Read more4/3/2024

0
GraphMU: Repairing Robustness of Graph Neural Networks via Machine Unlearning
Tao Wu, Xinwen Cao, Chao Wang, Shaojie Qiao, Xingping Xian, Lin Yuan, Canyixing Cui, Yanbing Liu
Graph Neural Networks (GNNs) have demonstrated significant application potential in various fields. However, GNNs are still vulnerable to adversarial attacks. Numerous adversarial defense methods on GNNs are proposed to address the problem of adversarial attacks. However, these methods can only serve as a defense before poisoning, but cannot repair poisoned GNN. Therefore, there is an urgent need for a method to repair poisoned GNN. In this paper, we address this gap by introducing the novel concept of model repair for GNNs. We propose a repair framework, Repairing Robustness of Graph Neural Networks via Machine Unlearning (GraphMU), which aims to fine-tune poisoned GNN to forget adversarial samples without the need for complete retraining. We also introduce a unlearning validation method to ensure that our approach effectively forget specified poisoned data. To evaluate the effectiveness of GraphMU, we explore three fine-tuned subgraph construction scenarios based on the available perturbation information: (i) Known Perturbation Ratios, (ii) Known Complete Knowledge of Perturbations, and (iii) Unknown any Knowledge of Perturbations. Our extensive experiments, conducted across four citation datasets and four adversarial attack scenarios, demonstrate that GraphMU can effectively restore the performance of poisoned GNN.
Read more6/21/2024

0
Exploring DNN Robustness Against Adversarial Attacks Using Approximate Multipliers
Mohammad Javad Askarizadeh, Ebrahim Farahmand, Jorge Castro-Godinez, Ali Mahani, Laura Cabrera-Quiros, Carlos Salazar-Garcia
Deep Neural Networks (DNNs) have advanced in many real-world applications, such as healthcare and autonomous driving. However, their high computational complexity and vulnerability to adversarial attacks are ongoing challenges. In this letter, approximate multipliers are used to explore DNN robustness improvement against adversarial attacks. By uniformly replacing accurate multipliers for state-of-the-art approximate ones in DNN layer models, we explore the DNNs robustness against various adversarial attacks in a feasible time. Results show up to 7% accuracy drop due to approximations when no attack is present while improving robust accuracy up to 10% when attacks applied.
Read more4/19/2024

0
Data Reconstruction Attacks and Defenses: A Systematic Evaluation
Sheng Liu, Zihan Wang, Yuxiao Chen, Qi Lei
Reconstruction attacks and defenses are essential in understanding the data leakage problem in machine learning. However, prior work has centered around empirical observations of gradient inversion attacks, lacks theoretical justifications, and cannot disentangle the usefulness of defending methods from the computational limitation of attacking methods. In this work, we propose to view the problem as an inverse problem, enabling us to theoretically, quantitatively, and systematically evaluate the data reconstruction problem. On various defense methods, we derived the algorithmic upper bound and the matching (in feature dimension and model width) information-theoretical lower bound on the reconstruction error for two-layer neural networks. To complement the theoretical results and investigate the utility-privacy trade-off, we defined a natural evaluation metric of the defense methods with similar utility loss among the strongest attacks. We further propose a strong reconstruction attack that helps update some previous understanding of the strength of defense methods under our proposed evaluation metric.
Read more6/28/2024