An approach to improve agent learning via guaranteeing goal reaching in all episodes

0
Sign in to get full access
Overview
- This paper proposes a novel approach to improve agent learning by guaranteeing that the agent reaches its goal in every episode during training.
- The key idea is to use "backward learning" to train the agent to reach the goal, instead of the typical reinforcement learning approach of learning from trial and error.
- The authors demonstrate the effectiveness of their method through experiments in various environments and compare it to other state-of-the-art reinforcement learning techniques.
Plain English Explanation
The paper introduces a new way to train artificial agents, or "AI agents," to accomplish specific tasks. Typically, agents learn through a process of trial and error, where they try different actions and get rewarded or punished based on the results. This can be a slow and inefficient process, especially for complex tasks.
The researchers propose a different approach called "backward learning." Instead of starting with random actions and gradually improving, the agent is trained to directly reach the goal, no matter what the starting point is. This is like teaching a person to get from their house to the store, by first showing them the route from the store back to their house, and then having them practice going both ways.
The key insight is that by guaranteeing the agent can reach the goal in every training episode, it learns more efficiently and effectively. This allows the agent to master the task much faster than traditional reinforcement learning methods.
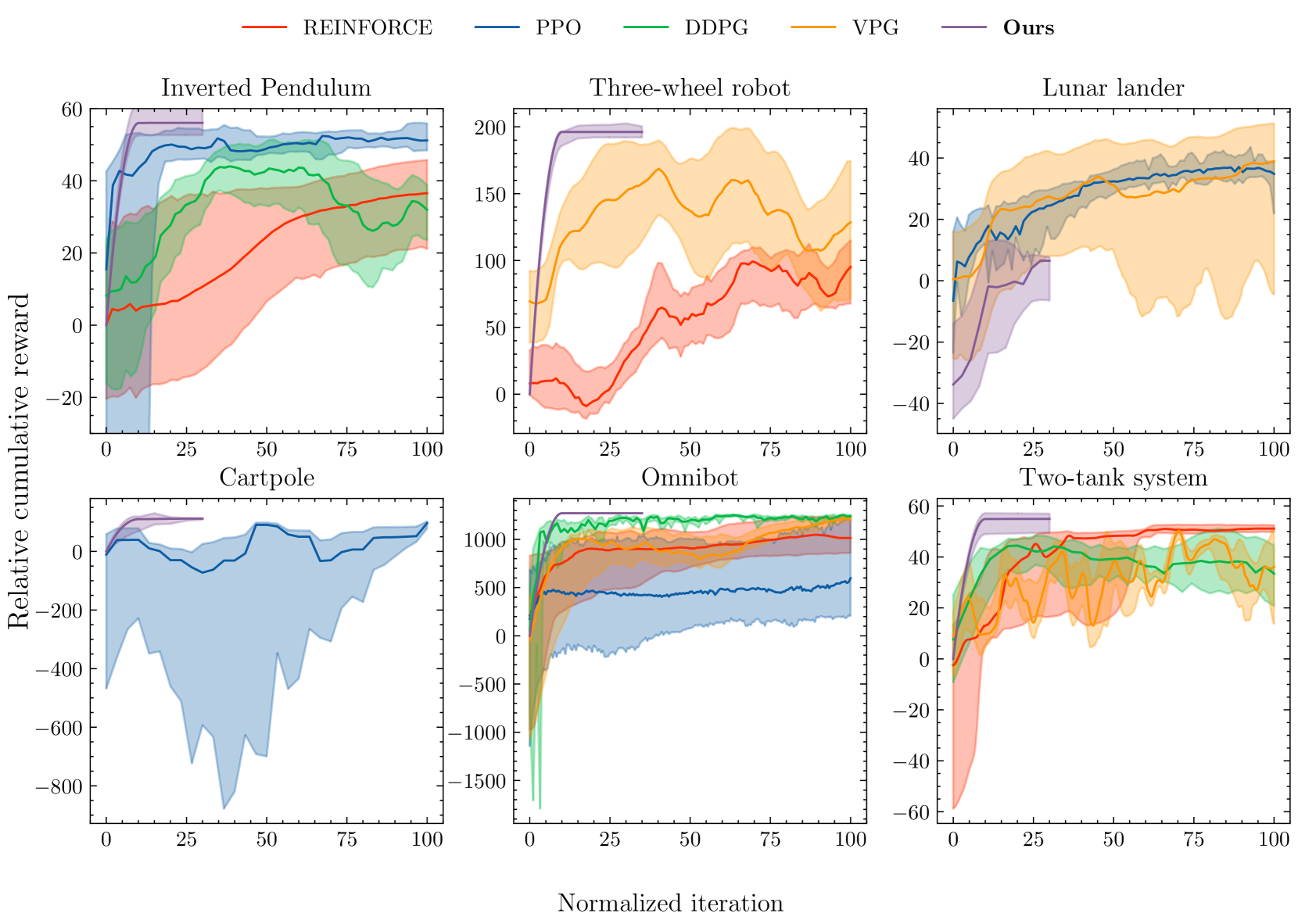
The paper demonstrates the benefits of this approach through experiments in various simulated environments, and compares it to other state-of-the-art reinforcement learning techniques. The results show that the backward learning method outperforms these other methods, suggesting it could be a valuable tool for training AI agents to accomplish complex tasks.
Technical Explanation
The paper introduces a novel approach called "Backward Learning" to train agents to reach a goal in reinforcement learning (RL) environments. The key idea is to train the agent to reach the goal from any starting state, rather than the typical RL approach of learning from trial and error.
The authors formulate the problem as a backward learning for goal-conditioned policies task, where the agent learns a policy that can reach the goal from any initial state. This is in contrast to the traditional goal-conditioned reinforcement learning approach, where the agent learns a policy that maximizes the expected return.
To solve this problem, the authors propose a method inspired by maximum diffusion reinforcement learning, where the agent learns a policy that maximizes the probability of reaching the goal from any initial state. This is achieved by training the agent to minimize the Kullback-Leibler (KL) divergence between the distribution of states visited by the agent and a uniform distribution over all states.
The authors demonstrate the effectiveness of their approach through experiments in various simulated environments, including continuous control tasks and discrete navigation tasks. The results show that their backward learning method outperforms standard RL techniques in terms of goal-reaching performance and sample efficiency.
Critical Analysis
The paper presents a promising approach to improve agent learning in reinforcement learning tasks, but there are a few potential limitations and areas for further research:
-
The paper focuses on relatively simple simulated environments, and it's unclear how well the backward learning method would scale to more complex real-world problems. Further evaluation in more challenging and realistic scenarios would be valuable.
-
The authors mention that their method requires the ability to reset the environment to any arbitrary state, which may not be feasible in many practical applications. Investigating ways to relax this requirement or develop alternatives would be an important next step.
-
The paper does not provide a theoretical analysis of the properties and guarantees of the backward learning approach. A more rigorous mathematical treatment could help build a deeper understanding of the method and its limitations.
-
While the experiments demonstrate the benefits of the backward learning method, the authors do not provide much insight into the underlying reasons for its superior performance. Exploring the mechanisms and dynamics that lead to the observed improvements could yield valuable insights.
Overall, the paper presents an interesting and potentially impactful idea, but further research is needed to fully explore its capabilities, limitations, and theoretical foundations.
Conclusion
This paper introduces a novel approach called "Backward Learning" to train reinforcement learning agents to reliably reach their goals. By training the agent to reach the goal from any starting state, rather than learning through trial and error, the method is able to achieve significantly improved performance and sample efficiency compared to standard RL techniques.
The key contribution of this work is the insight that guaranteeing goal-reaching in every training episode can lead to more effective and efficient agent learning. This represents an important step forward in the field of reinforcement learning, with potential applications in a wide range of domains where agents need to reliably accomplish specific tasks.
While further research is needed to fully understand the limitations and scaling capabilities of the backward learning approach, this paper demonstrates its promise as a valuable tool for training capable and reliable artificial agents.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
An approach to improve agent learning via guaranteeing goal reaching in all episodes
Pavel Osinenko, Grigory Yaremenko, Georgiy Malaniya, Anton Bolychev, Alexander Gepperth
Reinforcement learning is commonly concerned with problems of maximizing accumulated rewards in Markov decision processes. Oftentimes, a certain goal state or a subset of the state space attain maximal reward. In such a case, the environment may be considered solved when the goal is reached. Whereas numerous techniques, learning or non-learning based, exist for solving environments, doing so optimally is the biggest challenge. Say, one may choose a reward rate which penalizes the action effort. Reinforcement learning is currently among the most actively developed frameworks for solving environments optimally by virtue of maximizing accumulated reward, in other words, returns. Yet, tuning agents is a notoriously hard task as reported in a series of works. Our aim here is to help the agent learn a near-optimal policy efficiently while ensuring a goal reaching property of some basis policy that merely solves the environment. We suggest an algorithm, which is fairly flexible, and can be used to augment practically any agent as long as it comprises of a critic. A formal proof of a goal reaching property is provided. Comparative experiments on several problems under popular baseline agents provided an empirical evidence that the learning can indeed be boosted while ensuring goal reaching property.
Read more8/23/2024

0
Backward Learning for Goal-Conditioned Policies
Marc Hoftmann, Jan Robine, Stefan Harmeling
Can we learn policies in reinforcement learning without rewards? Can we learn a policy just by trying to reach a goal state? We answer these questions positively by proposing a multi-step procedure that first learns a world model that goes backward in time, secondly generates goal-reaching backward trajectories, thirdly improves those sequences using shortest path finding algorithms, and finally trains a neural network policy by imitation learning. We evaluate our method on a deterministic maze environment where the observations are $64times 64$ pixel bird's eye images and can show that it consistently reaches several goals.
Read more4/16/2024
0
To the Max: Reinventing Reward in Reinforcement Learning
Grigorii Veviurko, Wendelin Bohmer, Mathijs de Weerdt
In reinforcement learning (RL), different reward functions can define the same optimal policy but result in drastically different learning performance. For some, the agent gets stuck with a suboptimal behavior, and for others, it solves the task efficiently. Choosing a good reward function is hence an extremely important yet challenging problem. In this paper, we explore an alternative approach for using rewards for learning. We introduce textit{max-reward RL}, where an agent optimizes the maximum rather than the cumulative reward. Unlike earlier works, our approach works for deterministic and stochastic environments and can be easily combined with state-of-the-art RL algorithms. In the experiments, we study the performance of max-reward RL algorithms in two goal-reaching environments from Gymnasium-Robotics and demonstrate its benefits over standard RL. The code is available at https://github.com/veviurko/To-the-Max.
Read more7/31/2024
0
An Introduction to Reinforcement Learning: Fundamental Concepts and Practical Applications
Majid Ghasemi, Amir Hossein Moosavi, Ibrahim Sorkhoh, Anjali Agrawal, Fadi Alzhouri, Dariush Ebrahimi
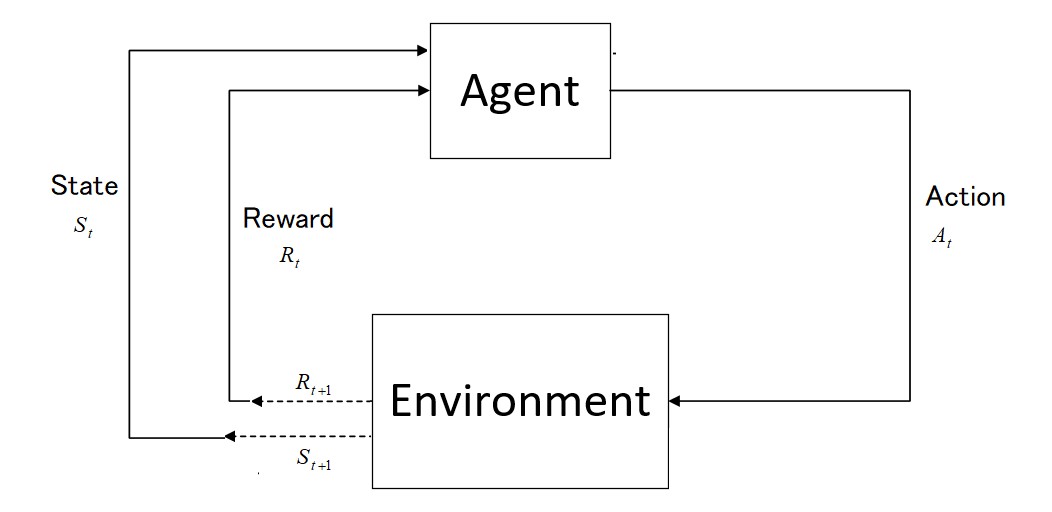
Reinforcement Learning (RL) is a branch of Artificial Intelligence (AI) which focuses on training agents to make decisions by interacting with their environment to maximize cumulative rewards. An overview of RL is provided in this paper, which discusses its core concepts, methodologies, recent trends, and resources for learning. We provide a detailed explanation of key components of RL such as states, actions, policies, and reward signals so that the reader can build a foundational understanding. The paper also provides examples of various RL algorithms, including model-free and model-based methods. In addition, RL algorithms are introduced and resources for learning and implementing them are provided, such as books, courses, and online communities. This paper demystifies a comprehensive yet simple introduction for beginners by offering a structured and clear pathway for acquiring and implementing real-time techniques.
Read more8/16/2024