To the Max: Reinventing Reward in Reinforcement Learning

0
Sign in to get full access
Overview
- The paper "To the Max: Reinventing Reward in Reinforcement Learning" explores ways to improve reinforcement learning agents by rethinking the reward function.
- The authors propose a new reward formulation called "MaxReward" that aims to provide better exploration and convergence properties compared to traditional reward functions.
- The paper includes a theoretical analysis of MaxReward and experiments on a set of benchmark reinforcement learning tasks to evaluate its performance.
Plain English Explanation
In reinforcement learning, agents learn to make decisions by receiving rewards or punishments for their actions. The standard approach is to define a single reward function that the agent tries to maximize. However, this can lead to issues with exploration and convergence to suboptimal policies.
The authors of this paper propose a new way to define the reward function, called "MaxReward." Instead of a single reward, the agent receives a set of potential rewards, and its goal is to maximize the
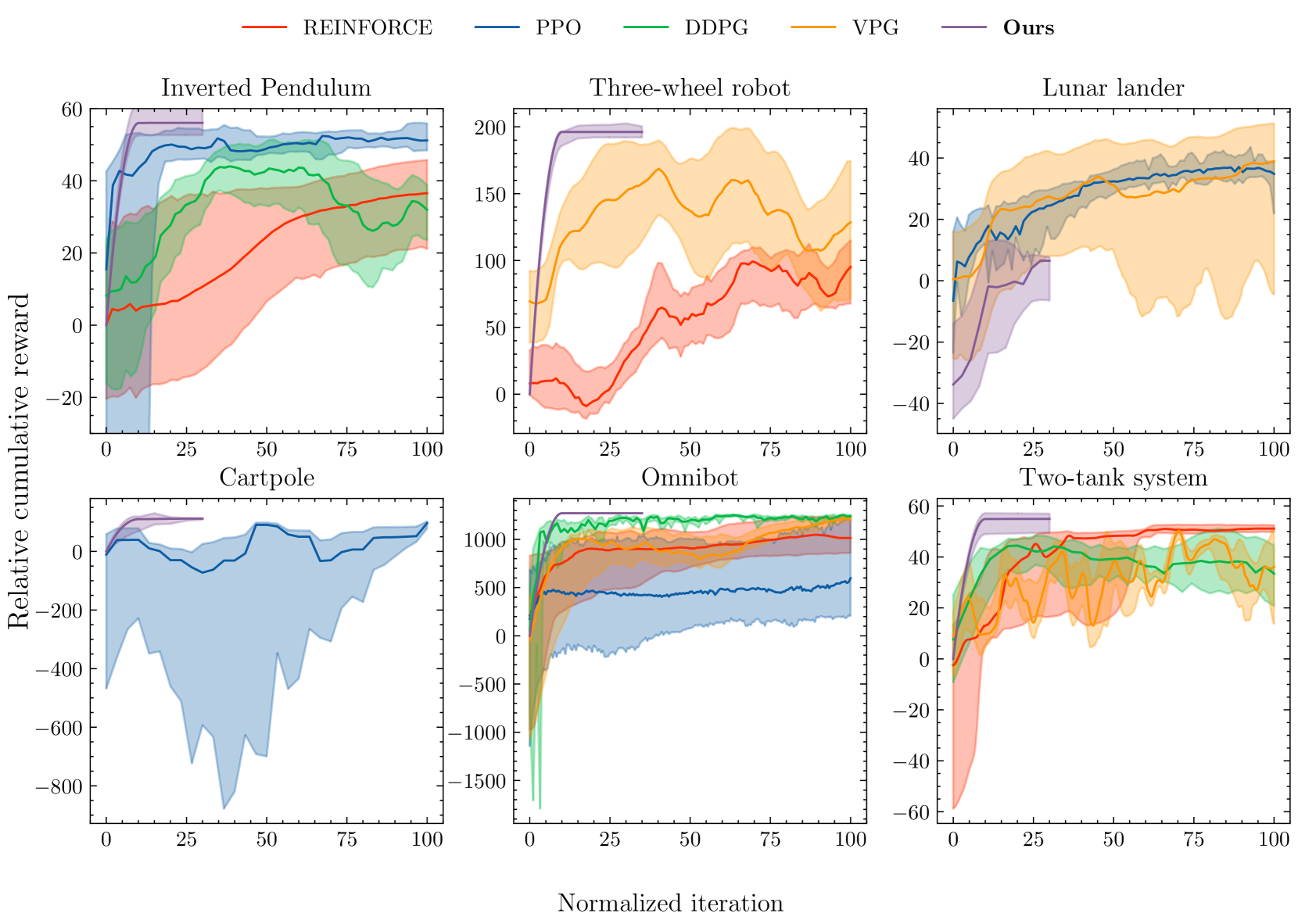
The authors provide a theoretical analysis of the MaxReward formulation, showing that it can lead to better exploration and convergence properties compared to traditional reward functions. They also evaluate MaxReward on a variety of reinforcement learning tasks and find that it outperforms standard reward functions in many cases.
Technical Explanation
The paper begins by motivating the need for new reward formulations in reinforcement learning. The authors argue that traditional reward functions can lead to issues with exploration and convergence, as the agent may get stuck pursuing a single reward signal that does not lead to the best long-term outcome.
To address this, the authors propose the "MaxReward" formulation. Instead of a single reward, the agent receives a set of potential rewards, and its goal is to maximize the
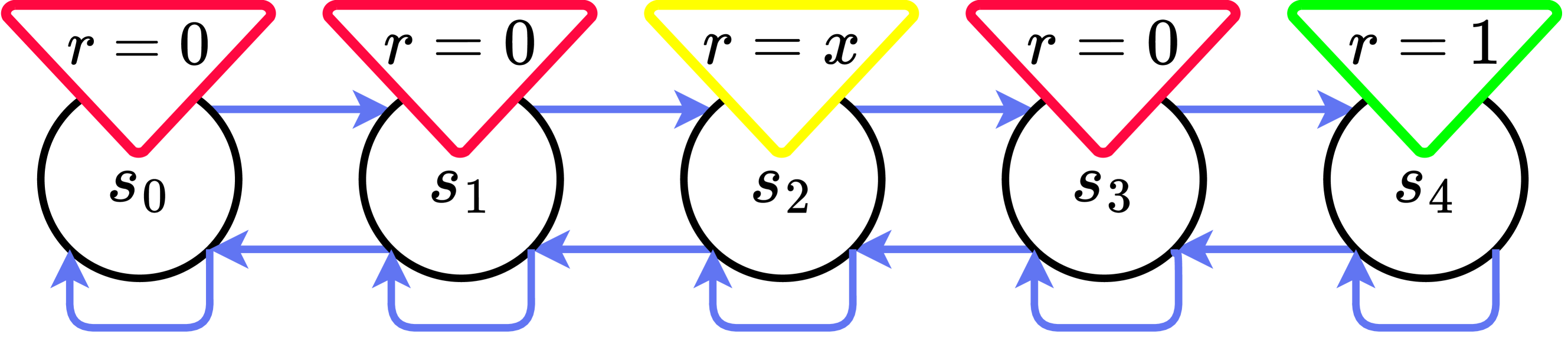
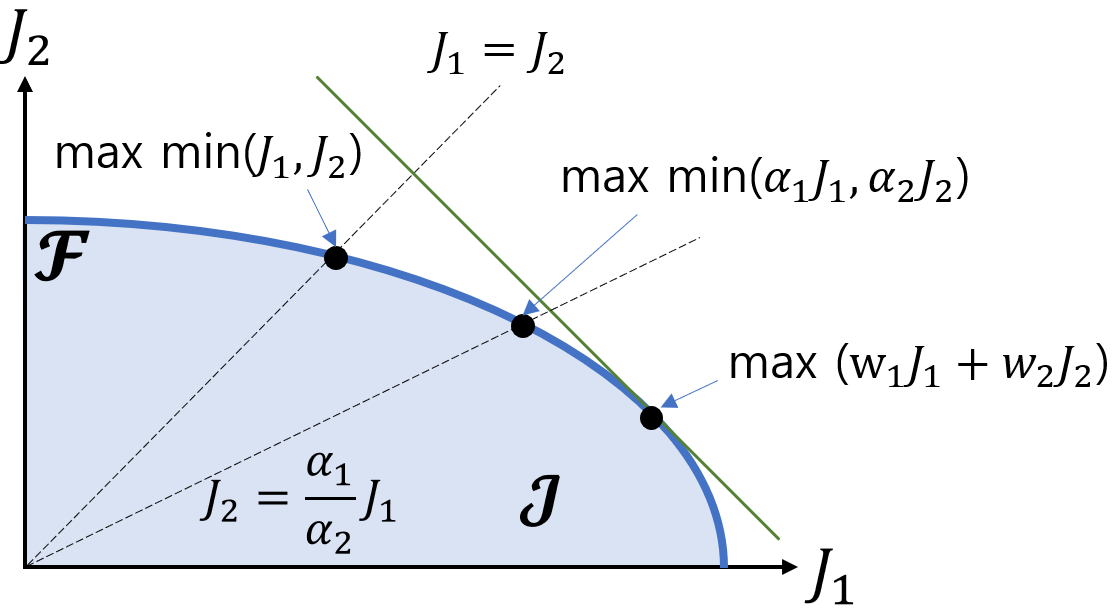
MaxReward(s, a) = max_r min_i r_i(s, a)
Where r_i(s, a) are the individual reward components.
The authors provide a theoretical analysis of the MaxReward formulation, showing that it can lead to better exploration and convergence properties compared to traditional reward functions. They also evaluate MaxReward on a variety of reinforcement learning tasks, including classic control problems and Atari games, and find that it outperforms standard reward functions in many cases.
Critical Analysis
The paper presents a novel and interesting approach to defining reward functions in reinforcement learning. The authors make a compelling case for the limitations of traditional reward functions and provide a well-designed alternative in the form of MaxReward.
One potential limitation of the approach is that it may be more computationally expensive, as the agent needs to consider a set of potential rewards rather than a single value. Additionally, the authors do not provide a systematic way to determine the individual reward components r_i, which could be challenging in practice.
Further research could explore ways to make the MaxReward formulation more efficient, as well as investigate how to automatically generate the individual reward components. It would also be interesting to see how MaxReward performs on a wider range of reinforcement learning tasks and in more complex environments.
Conclusion
This paper introduces a novel reward formulation called "MaxReward" that aims to improve exploration and convergence in reinforcement learning. By shifting the focus from maximizing a single reward to maximizing the minimum of a set of potential rewards, the authors demonstrate how this approach can lead to better performance on a variety of benchmark tasks.
The paper provides a solid theoretical foundation and experimental evaluation of the MaxReward approach, making it a valuable contribution to the field of reinforcement learning. While there are still some open questions and areas for further research, this work represents an important step towards reinventing reward functions and advancing the capabilities of reinforcement learning agents.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
To the Max: Reinventing Reward in Reinforcement Learning
Grigorii Veviurko, Wendelin Bohmer, Mathijs de Weerdt
In reinforcement learning (RL), different reward functions can define the same optimal policy but result in drastically different learning performance. For some, the agent gets stuck with a suboptimal behavior, and for others, it solves the task efficiently. Choosing a good reward function is hence an extremely important yet challenging problem. In this paper, we explore an alternative approach for using rewards for learning. We introduce textit{max-reward RL}, where an agent optimizes the maximum rather than the cumulative reward. Unlike earlier works, our approach works for deterministic and stochastic environments and can be easily combined with state-of-the-art RL algorithms. In the experiments, we study the performance of max-reward RL algorithms in two goal-reaching environments from Gymnasium-Robotics and demonstrate its benefits over standard RL. The code is available at https://github.com/veviurko/To-the-Max.
Read more7/31/2024
0
An approach to improve agent learning via guaranteeing goal reaching in all episodes
Pavel Osinenko, Grigory Yaremenko, Georgiy Malaniya, Anton Bolychev, Alexander Gepperth
Reinforcement learning is commonly concerned with problems of maximizing accumulated rewards in Markov decision processes. Oftentimes, a certain goal state or a subset of the state space attain maximal reward. In such a case, the environment may be considered solved when the goal is reached. Whereas numerous techniques, learning or non-learning based, exist for solving environments, doing so optimally is the biggest challenge. Say, one may choose a reward rate which penalizes the action effort. Reinforcement learning is currently among the most actively developed frameworks for solving environments optimally by virtue of maximizing accumulated reward, in other words, returns. Yet, tuning agents is a notoriously hard task as reported in a series of works. Our aim here is to help the agent learn a near-optimal policy efficiently while ensuring a goal reaching property of some basis policy that merely solves the environment. We suggest an algorithm, which is fairly flexible, and can be used to augment practically any agent as long as it comprises of a critic. A formal proof of a goal reaching property is provided. Comparative experiments on several problems under popular baseline agents provided an empirical evidence that the learning can indeed be boosted while ensuring goal reaching property.
Read more8/23/2024
0
The Max-Min Formulation of Multi-Objective Reinforcement Learning: From Theory to a Model-Free Algorithm
Giseung Park, Woohyeon Byeon, Seongmin Kim, Elad Havakuk, Amir Leshem, Youngchul Sung
In this paper, we consider multi-objective reinforcement learning, which arises in many real-world problems with multiple optimization goals. We approach the problem with a max-min framework focusing on fairness among the multiple goals and develop a relevant theory and a practical model-free algorithm under the max-min framework. The developed theory provides a theoretical advance in multi-objective reinforcement learning, and the proposed algorithm demonstrates a notable performance improvement over existing baseline methods.
Read more6/13/2024

0
Analyzing and Bridging the Gap between Maximizing Total Reward and Discounted Reward in Deep Reinforcement Learning
Shuyu Yin, Fei Wen, Peilin Liu, Tao Luo
In deep reinforcement learning applications, maximizing discounted reward is often employed instead of maximizing total reward to ensure the convergence and stability of algorithms, even though the performance metric for evaluating the policy remains the total reward. However, the optimal policies corresponding to these two objectives may not always be consistent. To address this issue, we analyzed the suboptimality of the policy obtained through maximizing discounted reward in relation to the policy that maximizes total reward and identified the influence of hyperparameters. Additionally, we proposed sufficient conditions for aligning the optimal policies of these two objectives under various settings. The primary contributions are as follows: We theoretically analyzed the factors influencing performance when using discounted reward as a proxy for total reward, thereby enhancing the theoretical understanding of this scenario. Furthermore, we developed methods to align the optimal policies of the two objectives in certain situations, which can improve the performance of reinforcement learning algorithms.
Read more7/19/2024