AIR-Bench: Benchmarking Large Audio-Language Models via Generative Comprehension

0

Sign in to get full access
Overview
- This paper introduces AIR-Bench, a new benchmark for evaluating the performance of large audio-language models.
- AIR-Bench focuses on the task of generative comprehension, where models must generate summaries or answers based on audio inputs.
- The benchmark covers a diverse set of audio-language understanding tasks and datasets.
- The authors use AIR-Bench to analyze the capabilities of several state-of-the-art audio-language models.
Plain English Explanation
The researchers have developed a new benchmark called AIR-Bench to evaluate the performance of large audio-language models. These are AI models that can understand and generate text based on audio inputs, such as speech or environmental sounds.
The key idea behind AIR-Bench is to focus on the task of "generative comprehension." This means the models have to not just understand the audio, but also generate a summary or answer based on what they've learned. This is a more challenging task than simply classifying or extracting information from audio.
The benchmark covers a wide range of audio-language understanding tasks, using different datasets. This allows the researchers to get a comprehensive view of the models' capabilities across various domains.
By using AIR-Bench to analyze several state-of-the-art audio-language models, the researchers can better understand the current limitations and strengths of these technologies. This can guide future research and development efforts in this important area of artificial intelligence.
Technical Explanation
The paper introduces AIR-Bench, a new benchmark for evaluating the performance of large audio-language models. The benchmark focuses on the task of generative comprehension, where models must generate summaries or answers based on audio inputs.
AIR-Bench covers a diverse set of audio-language understanding tasks, using datasets that span various domains, including speech, music, and environmental sounds. The tasks range from generating captions for audio clips to answering questions about audio content.
The authors use AIR-Bench to analyze the performance of several state-of-the-art audio-language models, including BART, PromptCLIP, and UniSpeech-SAT. The results provide insights into the current capabilities and limitations of these models, as well as areas for future research and development.
Critical Analysis
The authors acknowledge several limitations of their work. First, the benchmark focuses on generative comprehension tasks, which may not capture all the nuances of audio-language understanding. Additional tasks, such as audio classification or retrieval, could provide a more complete picture of model capabilities.
Furthermore, the datasets used in AIR-Bench, while diverse, may not be representative of the full range of real-world audio-language scenarios. The authors suggest that expanding the benchmark to include more diverse and challenging datasets could help address this issue.
Another potential concern is the computational cost and resource requirements of running the AIR-Bench evaluation. Developing more efficient and scalable benchmarking approaches could make it more accessible to a wider range of researchers and developers.
Overall, the AIR-Bench framework represents an important step forward in the evaluation of audio-language models. By providing a standardized and comprehensive benchmark, the authors hope to drive progress in this rapidly evolving field of AI.
Conclusion
The AIR-Bench benchmark introduced in this paper offers a new approach to evaluating the performance of large audio-language models. By focusing on the task of generative comprehension, the benchmark provides a more comprehensive assessment of these models' capabilities in understanding and generating relevant outputs based on audio inputs.
The results from analyzing several state-of-the-art models using AIR-Bench offer valuable insights into the current strengths and limitations of audio-language technologies. This knowledge can guide future research and development efforts, ultimately leading to more powerful and versatile AI systems that can seamlessly integrate audio and language understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AIR-Bench: Benchmarking Large Audio-Language Models via Generative Comprehension
Qian Yang, Jin Xu, Wenrui Liu, Yunfei Chu, Ziyue Jiang, Xiaohuan Zhou, Yichong Leng, Yuanjun Lv, Zhou Zhao, Chang Zhou, Jingren Zhou
Recently, instruction-following audio-language models have received broad attention for human-audio interaction. However, the absence of benchmarks capable of evaluating audio-centric interaction capabilities has impeded advancements in this field. Previous models primarily focus on assessing different fundamental tasks, such as Automatic Speech Recognition (ASR), and lack an assessment of the open-ended generative capabilities centered around audio. Thus, it is challenging to track the progression in the Large Audio-Language Models (LALMs) domain and to provide guidance for future improvement. In this paper, we introduce AIR-Bench (textbf{A}udio textbf{I}nsttextbf{R}uction textbf{Bench}mark), the first benchmark designed to evaluate the ability of LALMs to understand various types of audio signals (including human speech, natural sounds, and music), and furthermore, to interact with humans in the textual format. AIR-Bench encompasses two dimensions: textit{foundation} and textit{chat} benchmarks. The former consists of 19 tasks with approximately 19k single-choice questions, intending to inspect the basic single-task ability of LALMs. The latter one contains 2k instances of open-ended question-and-answer data, directly assessing the comprehension of the model on complex audio and its capacity to follow instructions. Both benchmarks require the model to generate hypotheses directly. We design a unified framework that leverages advanced language models, such as GPT-4, to evaluate the scores of generated hypotheses given the meta-information of the audio. Experimental results demonstrate a high level of consistency between GPT-4-based evaluation and human evaluation. By revealing the limitations of existing LALMs through evaluation results, AIR-Bench can provide insights into the direction of future research.
Read more7/29/2024

0
AudioBench: A Universal Benchmark for Audio Large Language Models
Bin Wang, Xunlong Zou, Geyu Lin, Shuo Sun, Zhuohan Liu, Wenyu Zhang, Zhengyuan Liu, AiTi Aw, Nancy F. Chen
We introduce AudioBench, a universal benchmark designed to evaluate Audio Large Language Models (AudioLLMs). It encompasses 8 distinct tasks and 26 datasets, among which, 7 are newly proposed datasets. The evaluation targets three main aspects: speech understanding, audio scene understanding, and voice understanding (paralinguistic). Despite recent advancements, there lacks a comprehensive benchmark for AudioLLMs on instruction following capabilities conditioned on audio signals. AudioBench addresses this gap by setting up datasets as well as desired evaluation metrics. Besides, we also evaluated the capabilities of five popular models and found that no single model excels consistently across all tasks. We outline the research outlook for AudioLLMs and anticipate that our open-sourced evaluation toolkit, data, and leaderboard will offer a robust testbed for future model developments.
Read more9/4/2024

0
Evaluating Large Vision-Language Models' Understanding of Real-World Complexities Through Synthetic Benchmarks
Haokun Zhou, Yipeng Hong
This study assesses the ability of Large Vision-Language Models (LVLMs) to differentiate between AI-generated and human-generated images. It introduces a new automated benchmark construction method for this evaluation. The experiment compared common LVLMs with human participants using a mixed dataset of AI and human-created images. Results showed that LVLMs could distinguish between the image types to some extent but exhibited a rightward bias, and perform significantly worse compared to humans. To build on these findings, we developed an automated benchmark construction process using AI. This process involved topic retrieval, narrative script generation, error embedding, and image generation, creating a diverse set of text-image pairs with intentional errors. We validated our method through constructing two caparable benchmarks. This study highlights the strengths and weaknesses of LVLMs in real-world understanding and advances benchmark construction techniques, providing a scalable and automatic approach for AI model evaluation.
Read more6/14/2024
0
CS-Bench: A Comprehensive Benchmark for Large Language Models towards Computer Science Mastery
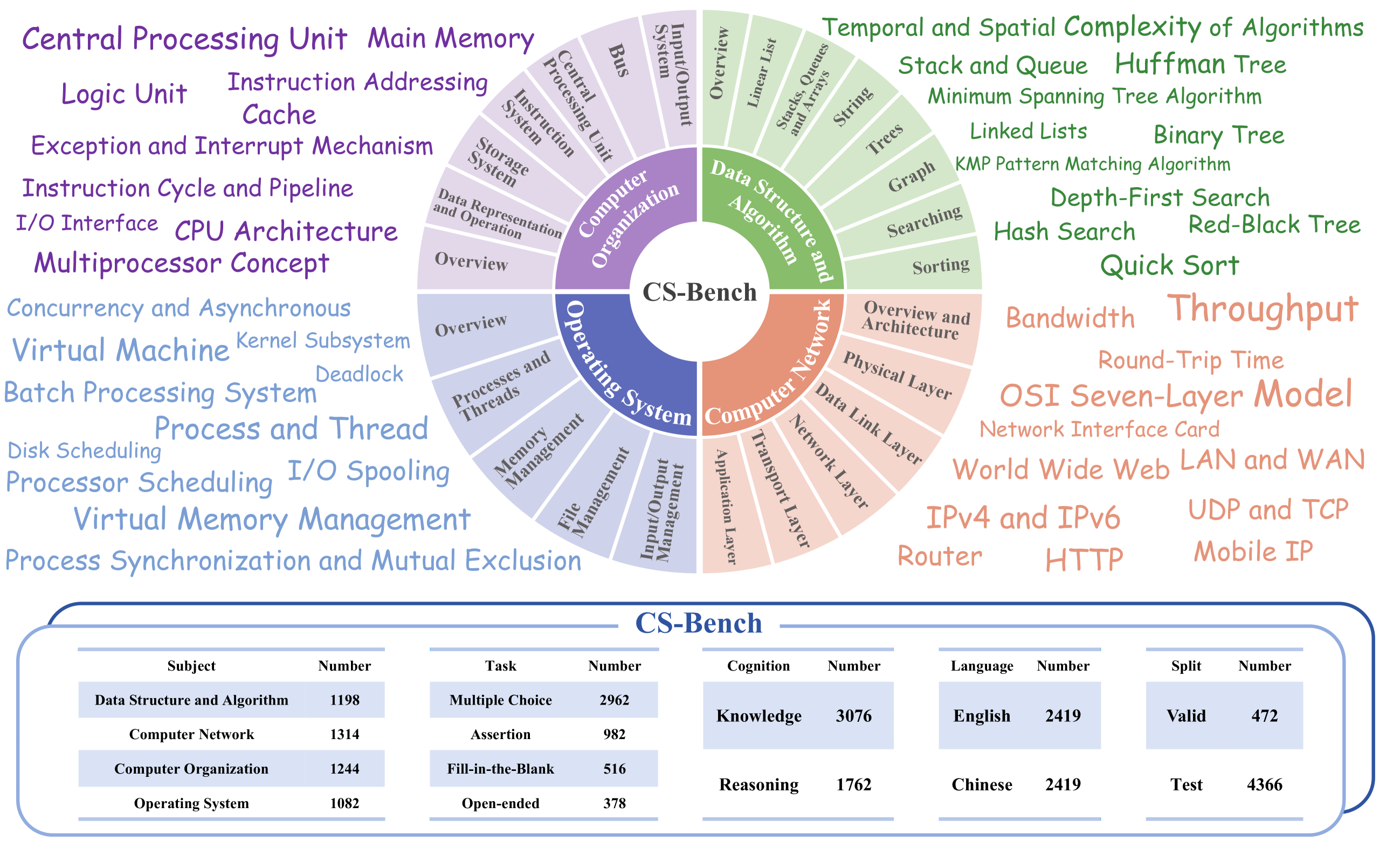
Xiaoshuai Song, Muxi Diao, Guanting Dong, Zhengyang Wang, Yujia Fu, Runqi Qiao, Zhexu Wang, Dayuan Fu, Huangxuan Wu, Bin Liang, Weihao Zeng, Yejie Wang, Zhuoma GongQue, Jianing Yu, Qiuna Tan, Weiran Xu
Computer Science (CS) stands as a testament to the intricacies of human intelligence, profoundly advancing the development of artificial intelligence and modern society. However, the current community of large language models (LLMs) overly focuses on benchmarks for analyzing specific foundational skills (e.g. mathematics and code generation), neglecting an all-round evaluation of the computer science field. To bridge this gap, we introduce CS-Bench, the first bilingual (Chinese-English) benchmark dedicated to evaluating the performance of LLMs in computer science. CS-Bench comprises approximately 5K meticulously curated test samples, covering 26 subfields across 4 key areas of computer science, encompassing various task forms and divisions of knowledge and reasoning. Utilizing CS-Bench, we conduct a comprehensive evaluation of over 30 mainstream LLMs, revealing the relationship between CS performance and model scales. We also quantitatively analyze the reasons for failures in existing LLMs and highlight directions for improvements, including knowledge supplementation and CS-specific reasoning. Further cross-capability experiments show a high correlation between LLMs' capabilities in computer science and their abilities in mathematics and coding. Moreover, expert LLMs specialized in mathematics and coding also demonstrate strong performances in several CS subfields. Looking ahead, we envision CS-Bench serving as a cornerstone for LLM applications in the CS field and paving new avenues in assessing LLMs' diverse reasoning capabilities. The CS-Bench data and evaluation code are available at https://github.com/csbench/csbench.
Read more6/14/2024