The BiGGen Bench: A Principled Benchmark for Fine-grained Evaluation of Language Models with Language Models

0
💬
Sign in to get full access
Overview
- As language models (LMs) become more capable, evaluating their performance is becoming as challenging as developing them.
- Current generation benchmarks often use abstract criteria like "helpfulness" and "harmlessness" that lack the flexibility and nuance of human assessment.
- These benchmarks also tend to focus disproportionately on specific capabilities, leading to coverage bias.
Plain English Explanation
To overcome the limitations of existing language model evaluation methods, researchers have introduced the BiGGen Bench, a comprehensive benchmark designed to thoroughly evaluate nine distinct capabilities of LMs across 77 diverse tasks. A key feature of the BiGGen Bench is its use of instance-specific evaluation criteria, which closely mirror the nuanced discernment of human assessment.
The researchers applied this benchmark to assess 103 frontier LMs using five evaluator LMs. The code, data, and evaluation results are all publicly available, allowing others to build on this work and further advance the field of language model evaluation.
Technical Explanation
The BiGGen Bench is a generation benchmark that aims to evaluate nine distinct capabilities of language models, including task completion, coherence, factuality, and harmlessness, across 77 diverse tasks. This benchmark uses instance-specific evaluation criteria, similar to how humans assess the quality of language model outputs.
The researchers applied the BiGGen Bench to 103 frontier LMs, using five evaluator LMs to provide detailed assessments. The publicly available code, data, and evaluation results allow others to build on this work and further explore the capabilities of language models.
Critical Analysis
The BiGGen Bench represents a significant step forward in language model evaluation, as it addresses the limitations of existing benchmarks by using a more comprehensive and nuanced approach. However, the researchers acknowledge that there is still room for improvement, particularly in the area of capturing the full range of human-level discernment.
Additionally, the use of evaluator LMs to assess the performance of the target LMs raises questions about the potential biases and limitations of these evaluator models. It would be valuable to explore alternative evaluation methods, such as TinyBenchmarks or WildBench, which aim to evaluate language models using fewer examples or more challenging real-world tasks.
Conclusion
The BiGGen Bench represents an important advance in the evaluation of language models, addressing the limitations of existing benchmarks and providing a more comprehensive and nuanced assessment of LM capabilities. The public availability of the code, data, and evaluation results facilitates further research and development in this critical area. As language models continue to evolve, the need for robust and reliable evaluation methods will only grow, and the BiGGen Bench offers a promising approach to meet this challenge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
The BiGGen Bench: A Principled Benchmark for Fine-grained Evaluation of Language Models with Language Models
Seungone Kim, Juyoung Suk, Ji Yong Cho, Shayne Longpre, Chaeeun Kim, Dongkeun Yoon, Guijin Son, Yejin Cho, Sheikh Shafayat, Jinheon Baek, Sue Hyun Park, Hyeonbin Hwang, Jinkyung Jo, Hyowon Cho, Haebin Shin, Seongyun Lee, Hanseok Oh, Noah Lee, Namgyu Ho, Se June Joo, Miyoung Ko, Yoonjoo Lee, Hyungjoo Chae, Jamin Shin, Joel Jang, Seonghyeon Ye, Bill Yuchen Lin, Sean Welleck, Graham Neubig, Moontae Lee, Kyungjae Lee, Minjoon Seo
As language models (LMs) become capable of handling a wide range of tasks, their evaluation is becoming as challenging as their development. Most generation benchmarks currently assess LMs using abstract evaluation criteria like helpfulness and harmlessness, which often lack the flexibility and granularity of human assessment. Additionally, these benchmarks tend to focus disproportionately on specific capabilities such as instruction following, leading to coverage bias. To overcome these limitations, we introduce the BiGGen Bench, a principled generation benchmark designed to thoroughly evaluate nine distinct capabilities of LMs across 77 diverse tasks. A key feature of the BiGGen Bench is its use of instance-specific evaluation criteria, closely mirroring the nuanced discernment of human evaluation. We apply this benchmark to assess 103 frontier LMs using five evaluator LMs. Our code, data, and evaluation results are all publicly available at https://github.com/prometheus-eval/prometheus-eval/tree/main/BiGGen-Bench.
Read more6/11/2024
0
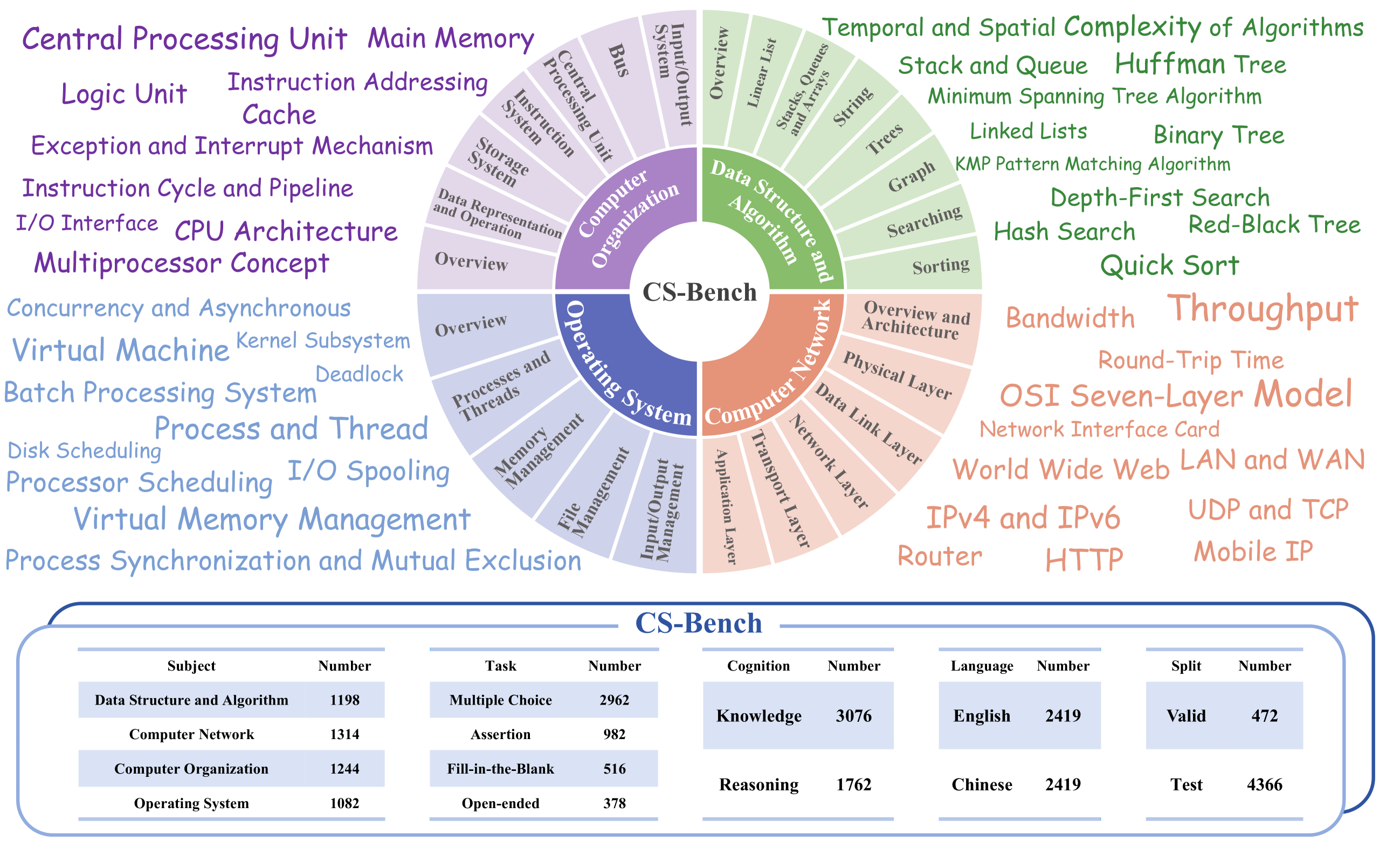
CS-Bench: A Comprehensive Benchmark for Large Language Models towards Computer Science Mastery
Xiaoshuai Song, Muxi Diao, Guanting Dong, Zhengyang Wang, Yujia Fu, Runqi Qiao, Zhexu Wang, Dayuan Fu, Huangxuan Wu, Bin Liang, Weihao Zeng, Yejie Wang, Zhuoma GongQue, Jianing Yu, Qiuna Tan, Weiran Xu
Computer Science (CS) stands as a testament to the intricacies of human intelligence, profoundly advancing the development of artificial intelligence and modern society. However, the current community of large language models (LLMs) overly focuses on benchmarks for analyzing specific foundational skills (e.g. mathematics and code generation), neglecting an all-round evaluation of the computer science field. To bridge this gap, we introduce CS-Bench, the first bilingual (Chinese-English) benchmark dedicated to evaluating the performance of LLMs in computer science. CS-Bench comprises approximately 5K meticulously curated test samples, covering 26 subfields across 4 key areas of computer science, encompassing various task forms and divisions of knowledge and reasoning. Utilizing CS-Bench, we conduct a comprehensive evaluation of over 30 mainstream LLMs, revealing the relationship between CS performance and model scales. We also quantitatively analyze the reasons for failures in existing LLMs and highlight directions for improvements, including knowledge supplementation and CS-specific reasoning. Further cross-capability experiments show a high correlation between LLMs' capabilities in computer science and their abilities in mathematics and coding. Moreover, expert LLMs specialized in mathematics and coding also demonstrate strong performances in several CS subfields. Looking ahead, we envision CS-Bench serving as a cornerstone for LLM applications in the CS field and paving new avenues in assessing LLMs' diverse reasoning capabilities. The CS-Bench data and evaluation code are available at https://github.com/csbench/csbench.
Read more6/14/2024
🛸
0
IndicGenBench: A Multilingual Benchmark to Evaluate Generation Capabilities of LLMs on Indic Languages
Harman Singh, Nitish Gupta, Shikhar Bharadwaj, Dinesh Tewari, Partha Talukdar
As large language models (LLMs) see increasing adoption across the globe, it is imperative for LLMs to be representative of the linguistic diversity of the world. India is a linguistically diverse country of 1.4 Billion people. To facilitate research on multilingual LLM evaluation, we release IndicGenBench - the largest benchmark for evaluating LLMs on user-facing generation tasks across a diverse set 29 of Indic languages covering 13 scripts and 4 language families. IndicGenBench is composed of diverse generation tasks like cross-lingual summarization, machine translation, and cross-lingual question answering. IndicGenBench extends existing benchmarks to many Indic languages through human curation providing multi-way parallel evaluation data for many under-represented Indic languages for the first time. We evaluate a wide range of proprietary and open-source LLMs including GPT-3.5, GPT-4, PaLM-2, mT5, Gemma, BLOOM and LLaMA on IndicGenBench in a variety of settings. The largest PaLM-2 models performs the best on most tasks, however, there is a significant performance gap in all languages compared to English showing that further research is needed for the development of more inclusive multilingual language models. IndicGenBench is released at www.github.com/google-research-datasets/indic-gen-bench
Read more4/26/2024
🎲
0
Benchmarks and Metrics for Evaluations of Code Generation: A Critical Review
Debalina Ghosh Paul, Hong Zhu, Ian Bayley
With the rapid development of Large Language Models (LLMs), a large number of machine learning models have been developed to assist programming tasks including the generation of program code from natural language input. However, how to evaluate such LLMs for this task is still an open problem despite of the great amount of research efforts that have been made and reported to evaluate and compare them. This paper provides a critical review of the existing work on the testing and evaluation of these tools with a focus on two key aspects: the benchmarks and the metrics used in the evaluations. Based on the review, further research directions are discussed.
Read more6/19/2024