On the Theory of Cross-Modality Distillation with Contrastive Learning

0

Sign in to get full access
Overview
- This paper introduces a novel approach called Cross-Modality Distillation (CMD) for training multimodal models using contrastive learning.
- CMD aims to transfer knowledge from a larger, more powerful "teacher" model to a smaller "student" model, allowing the student to achieve comparable performance while being more efficient.
- The authors provide a theoretical analysis of CMD and show how it can be used to bridge the gap between different modalities, such as vision and language.
Plain English Explanation
The researchers have developed a new way to train multimodal AI models, which are systems that can process and understand information from different sources, like text and images. The key idea is to take a large, complex model that is good at this task, and use it to teach a smaller, simpler model how to do the same thing.
This process, called Cross-Modality Distillation (CMD), allows the smaller model to learn from the larger one and achieve similar performance, but in a more efficient way. The researchers show how CMD can be particularly useful for bridging the gap between different types of information, like vision and language.
By using contrastive learning, the CMD approach encourages the student model to learn the relationships between different modalities, which can lead to more robust and generalizable multimodal models. This can have many applications, such as improving expression recognition or enhancing sentiment analysis.
Technical Explanation
The key innovation of this work is the Cross-Modality Distillation (CMD) framework, which leverages contrastive learning to bridge the gap between different modalities, such as vision and language. The authors provide a theoretical analysis of CMD, showing how it can be used to effectively transfer knowledge from a larger "teacher" model to a smaller "student" model.
The CMD approach works by first training a powerful multimodal teacher model on a diverse dataset. This teacher model is then used to generate "pseudo-labels" for the training data, which capture the relationships between the different modalities. The student model is then trained to predict these pseudo-labels, using a contrastive loss function that encourages the student to learn the same cross-modal associations as the teacher.
Through this cross-modal alignment and distillation process, the student model is able to achieve comparable performance to the teacher, but with a much more efficient architecture. The authors demonstrate the effectiveness of CMD on several multimodal benchmarks, showing that it can lead to significant improvements in tasks like expression recognition and sentiment analysis.
Critical Analysis
The authors provide a thorough theoretical analysis of the CMD framework, which lends strong support to the key claims and insights of the paper. However, it is worth noting that the experiments are primarily conducted on standard multimodal benchmarks, and the authors do not explore the potential limitations or edge cases of the approach.
One area for further research could be to investigate the performance of CMD in more challenging or real-world scenarios, where the distribution of the data may differ significantly from the training set. Additionally, the paper does not discuss the computational and memory requirements of the approach, which could be an important consideration for certain applications.
Despite these potential limitations, the CMD framework represents a promising step forward in the field of multimodal learning, and the authors' insights on the role of contrastive learning in bridging modalities are likely to have a significant impact on future research in this area.
Conclusion
This paper introduces a novel Cross-Modality Distillation (CMD) framework that leverages contrastive learning to effectively transfer knowledge from a larger "teacher" model to a smaller "student" model, enabling the student to achieve comparable performance in multimodal tasks. The authors provide a thorough theoretical analysis of CMD and demonstrate its effectiveness on several benchmarks, highlighting its potential for applications in areas like expression recognition and sentiment analysis.
While the paper does not explore all possible limitations of the approach, the core insights around the importance of cross-modal alignment and the role of contrastive learning are likely to have a lasting impact on the field of multimodal learning. The CMD framework represents an important step towards the development of more efficient and capable multimodal AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
On the Theory of Cross-Modality Distillation with Contrastive Learning
Hangyu Lin, Chen Liu, Chengming Xu, Zhengqi Gao, Yanwei Fu, Yuan Yao
Cross-modality distillation arises as an important topic for data modalities containing limited knowledge such as depth maps and high-quality sketches. Such techniques are of great importance, especially for memory and privacy-restricted scenarios where labeled training data is generally unavailable. To solve the problem, existing label-free methods leverage a few pairwise unlabeled data to distill the knowledge by aligning features or statistics between the source and target modalities. For instance, one typically aims to minimize the L2 distance or contrastive loss between the learned features of pairs of samples in the source (e.g. image) and the target (e.g. sketch) modalities. However, most algorithms in this domain only focus on the experimental results but lack theoretical insight. To bridge the gap between the theory and practical method of cross-modality distillation, we first formulate a general framework of cross-modality contrastive distillation (CMCD), built upon contrastive learning that leverages both positive and negative correspondence, towards a better distillation of generalizable features. Furthermore, we establish a thorough convergence analysis that reveals that the distance between source and target modalities significantly impacts the test error on downstream tasks within the target modality which is also validated by the empirical results. Extensive experimental results show that our algorithm outperforms existing algorithms consistently by a margin of 2-3% across diverse modalities and tasks, covering modalities of image, sketch, depth map, and audio and tasks of recognition and segmentation.
Read more5/29/2024

0
DisCoM-KD: Cross-Modal Knowledge Distillation via Disentanglement Representation and Adversarial Learning
Dino Ienco (EVERGREEN, UMR TETIS, INRAE), Cassio Fraga Dantas (UMR TETIS, INRAE, EVERGREEN)
Cross-modal knowledge distillation (CMKD) refers to the scenario in which a learning framework must handle training and test data that exhibit a modality mismatch, more precisely, training and test data do not cover the same set of data modalities. Traditional approaches for CMKD are based on a teacher/student paradigm where a teacher is trained on multi-modal data with the aim to successively distill knowledge from a multi-modal teacher to a single-modal student. Despite the widespread adoption of such paradigm, recent research has highlighted its inherent limitations in the context of cross-modal knowledge transfer.Taking a step beyond the teacher/student paradigm, here we introduce a new framework for cross-modal knowledge distillation, named DisCoM-KD (Disentanglement-learning based Cross-Modal Knowledge Distillation), that explicitly models different types of per-modality information with the aim to transfer knowledge from multi-modal data to a single-modal classifier. To this end, DisCoM-KD effectively combines disentanglement representation learning with adversarial domain adaptation to simultaneously extract, foreach modality, domain-invariant, domain-informative and domain-irrelevant features according to a specific downstream task. Unlike the traditional teacher/student paradigm, our framework simultaneously learns all single-modal classifiers, eliminating the need to learn each student model separately as well as the teacher classifier. We evaluated DisCoM-KD on three standard multi-modal benchmarks and compared its behaviourwith recent SOTA knowledge distillation frameworks. The findings clearly demonstrate the effectiveness of DisCoM-KD over competitors considering mismatch scenarios involving both overlapping and non-overlapping modalities. These results offer insights to reconsider the traditional paradigm for distilling information from multi-modal data to single-modal neural networks.
Read more8/15/2024
🤖
0
Enhancing Multi-modal Learning: Meta-learned Cross-modal Knowledge Distillation for Handling Missing Modalities
Hu Wang, Congbo Ma, Yuyuan Liu, Yuanhong Chen, Yu Tian, Jodie Avery, Louise Hull, Gustavo Carneiro
In multi-modal learning, some modalities are more influential than others, and their absence can have a significant impact on classification/segmentation accuracy. Hence, an important research question is if it is possible for trained multi-modal models to have high accuracy even when influential modalities are absent from the input data. In this paper, we propose a novel approach called Meta-learned Cross-modal Knowledge Distillation (MCKD) to address this research question. MCKD adaptively estimates the importance weight of each modality through a meta-learning process. These dynamically learned modality importance weights are used in a pairwise cross-modal knowledge distillation process to transfer the knowledge from the modalities with higher importance weight to the modalities with lower importance weight. This cross-modal knowledge distillation produces a highly accurate model even with the absence of influential modalities. Differently from previous methods in the field, our approach is designed to work in multiple tasks (e.g., segmentation and classification) with minimal adaptation. Experimental results on the Brain tumor Segmentation Dataset 2018 (BraTS2018) and the Audiovision-MNIST classification dataset demonstrate the superiority of MCKD over current state-of-the-art models. Particularly in BraTS2018, we achieve substantial improvements of 3.51% for enhancing tumor, 2.19% for tumor core, and 1.14% for the whole tumor in terms of average segmentation Dice score.
Read more5/14/2024
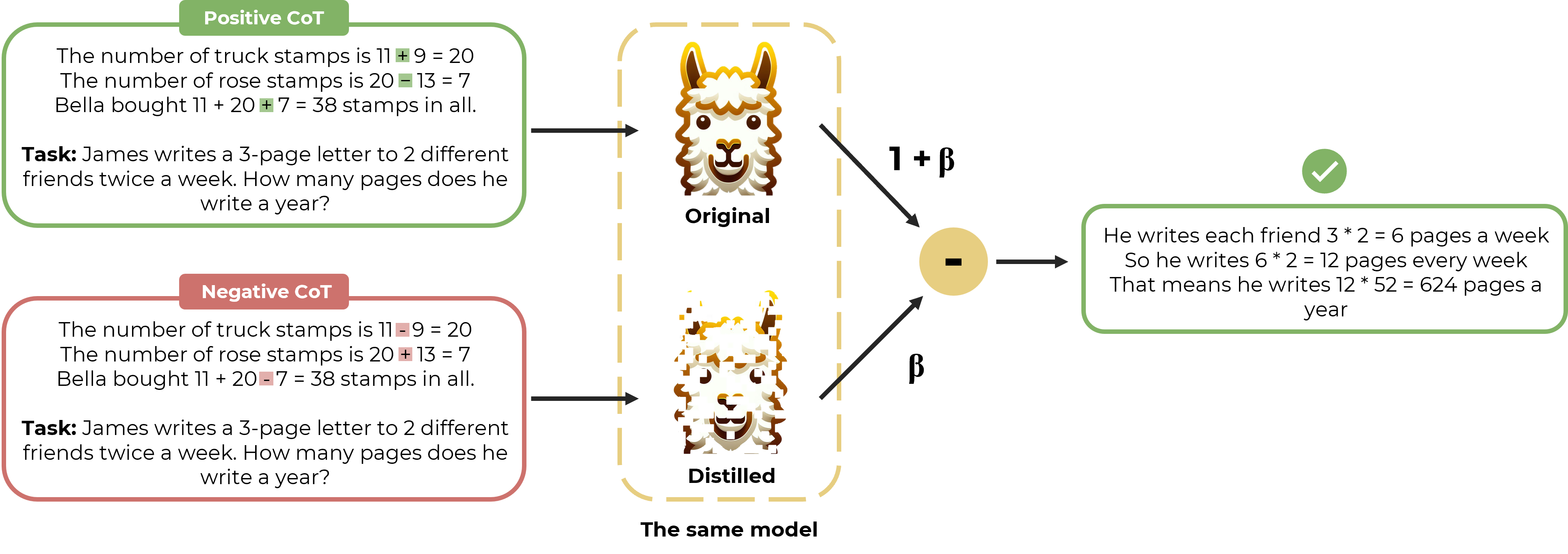
0
Distillation Contrastive Decoding: Improving LLMs Reasoning with Contrastive Decoding and Distillation
Phuc Phan, Hieu Tran, Long Phan
We propose a straightforward approach called Distillation Contrastive Decoding (DCD) to enhance the reasoning capabilities of Large Language Models (LLMs) during inference. In contrast to previous approaches that relied on smaller amateur models or analysis of hidden state differences, DCD employs Contrastive Chain-of-thought Prompting and advanced distillation techniques, including Dropout and Quantization. This approach effectively addresses the limitations of Contrastive Decoding (CD), which typically requires both an expert and an amateur model, thus increasing computational resource demands. By integrating contrastive prompts with distillation, DCD obviates the need for an amateur model and reduces memory usage. Our evaluations demonstrate that DCD significantly enhances LLM performance across a range of reasoning benchmarks, surpassing both CD and existing methods in the GSM8K and StrategyQA datasets.
Read more8/26/2024