Aligning Knowledge Graph with Visual Perception for Object-goal Navigation

0

Sign in to get full access
Overview
- This paper proposes a method for aligning knowledge graphs with visual perception to enable object-goal navigation in robotic systems.
- The approach leverages both symbolic knowledge from knowledge graphs and perceptual information from visual sensors to improve the robot's understanding of its environment and ability to navigate to specific objects.
- The method involves learning a joint embedding space that maps visual and conceptual representations, allowing the robot to ground symbolic knowledge in visual perception.
Plain English Explanation
The paper describes a way to help robots better understand their surroundings and navigate to specific objects. Robots often rely on two types of information: knowledge graphs that provide symbolic knowledge about the world, and visual perception from cameras and sensors that allow them to "see" their environment.
The key insight is that by aligning these two types of information - the symbolic knowledge and the visual perception - the robot can build a more complete understanding. This allows the robot to navigate more effectively to specific objects it is looking for, like navigating to a cup or a chair.
The paper presents a method to learn a joint embedding space that maps the symbolic knowledge from the knowledge graph and the perceptual information from the robot's visual sensors. This allows the robot to ground its abstract, conceptual understanding of the world in the concrete visual reality it observes, improving its ability to understand the scene and navigate to desired object goals.
Technical Explanation
The core of the proposed method is learning a joint embedding space that aligns the symbolic knowledge from a knowledge graph with the perceptual information from the robot's visual sensors. This is achieved through a multi-task learning framework that trains the model to:
- Predict the visual features of objects given their symbolic representation in the knowledge graph.
- Predict the symbolic representation of objects given their visual features.
By optimizing both of these objectives simultaneously, the model learns to map the symbolic and perceptual representations into a shared embedding space where they are well-aligned. This allows the robot to ground its abstract conceptual understanding in the observed visual reality, improving its ability to reason about and navigate to specific object goals.
The authors evaluate their approach on a series of object-goal navigation tasks, where the robot must navigate to a target object specified by name. They show that the knowledge graph alignment significantly improves the robot's performance compared to baselines that only use visual perception or symbolic knowledge alone.
Critical Analysis
The authors present a well-designed and comprehensive evaluation, testing their method on a range of object-goal navigation tasks with both simulated and real-world environments. The results demonstrate the benefits of aligning symbolic knowledge with visual perception, suggesting this is a promising direction for improving robot understanding and navigation capabilities.
However, the paper does not address some potential limitations or areas for future work. For example, the knowledge graph used in the experiments is relatively small and curated, whereas real-world knowledge graphs can be much larger and noisier. It's unclear how well the proposed method would scale to more complex and noisy knowledge representations.
Additionally, the paper focuses on static object-goal navigation, but many real-world scenarios involve dynamic environments and moving targets. Extending the approach to handle such scenarios could be an important next step.
Overall, the research makes a valuable contribution by showing how the integration of symbolic and perceptual information can enhance robotic navigation, but there are still opportunities to further develop and refine the techniques to handle more realistic and complex real-world conditions.
Conclusion
This paper presents a novel method for aligning knowledge graphs with visual perception to improve object-goal navigation in robotic systems. By learning a joint embedding space that maps symbolic and perceptual representations, the robot can ground its abstract conceptual understanding in observed visual reality, leading to enhanced scene understanding and more effective navigation to desired object goals.
The results demonstrate the benefits of this approach compared to using visual perception or symbolic knowledge alone, suggesting that the integration of these complementary information sources is a promising direction for advancing the capabilities of robotic systems. While the current work focuses on static object-goal scenarios, there is potential to extend the techniques to handle more dynamic real-world environments and tasks, which could have important implications for a wide range of robotic applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Aligning Knowledge Graph with Visual Perception for Object-goal Navigation
Nuo Xu, Wen Wang, Rong Yang, Mengjie Qin, Zheyuan Lin, Wei Song, Chunlong Zhang, Jason Gu, Chao Li
Object-goal navigation is a challenging task that requires guiding an agent to specific objects based on first-person visual observations. The ability of agent to comprehend its surroundings plays a crucial role in achieving successful object finding. However, existing knowledge-graph-based navigators often rely on discrete categorical one-hot vectors and vote counting strategy to construct graph representation of the scenes, which results in misalignment with visual images. To provide more accurate and coherent scene descriptions and address this misalignment issue, we propose the Aligning Knowledge Graph with Visual Perception (AKGVP) method for object-goal navigation. Technically, our approach introduces continuous modeling of the hierarchical scene architecture and leverages visual-language pre-training to align natural language description with visual perception. The integration of a continuous knowledge graph architecture and multimodal feature alignment empowers the navigator with a remarkable zero-shot navigation capability. We extensively evaluate our method using the AI2-THOR simulator and conduct a series of experiments to demonstrate the effectiveness and efficiency of our navigator. Code available: https://github.com/nuoxu/AKGVP.
Read more4/29/2024
0
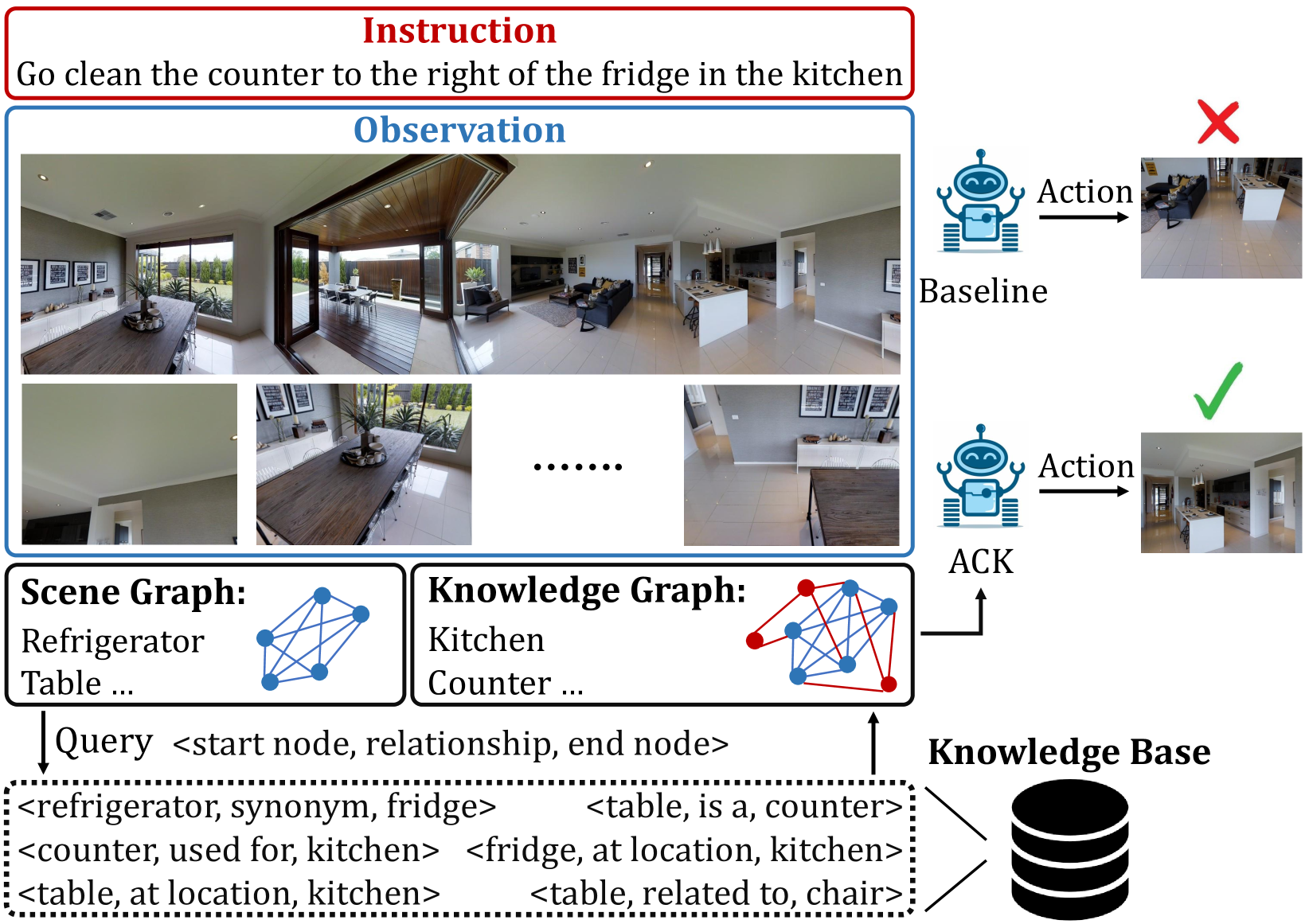
Augmented Commonsense Knowledge for Remote Object Grounding
Bahram Mohammadi, Yicong Hong, Yuankai Qi, Qi Wu, Shirui Pan, Javen Qinfeng Shi
The vision-and-language navigation (VLN) task necessitates an agent to perceive the surroundings, follow natural language instructions, and act in photo-realistic unseen environments. Most of the existing methods employ the entire image or object features to represent navigable viewpoints. However, these representations are insufficient for proper action prediction, especially for the REVERIE task, which uses concise high-level instructions, such as ''Bring me the blue cushion in the master bedroom''. To address enhancing representation, we propose an augmented commonsense knowledge model (ACK) to leverage commonsense information as a spatio-temporal knowledge graph for improving agent navigation. Specifically, the proposed approach involves constructing a knowledge base by retrieving commonsense information from ConceptNet, followed by a refinement module to remove noisy and irrelevant knowledge. We further present ACK which consists of knowledge graph-aware cross-modal and concept aggregation modules to enhance visual representation and visual-textual data alignment by integrating visible objects, commonsense knowledge, and concept history, which includes object and knowledge temporal information. Moreover, we add a new pipeline for the commonsense-based decision-making process which leads to more accurate local action prediction. Experimental results demonstrate our proposed model noticeably outperforms the baseline and archives the state-of-the-art on the REVERIE benchmark.
Read more6/4/2024

0
VLPG-Nav: Object Navigation Using Visual Language Pose Graph and Object Localization Probability Maps
Senthil Hariharan Arul (Tony), Dhruva Kumar (Tony), Vivek Sugirtharaj (Tony), Richard Kim (Tony), Xuewei (Tony), Qi, Rajasimman Madhivanan, Arnie Sen, Dinesh Manocha
We present VLPG-Nav, a visual language navigation method for guiding robots to specified objects within household scenes. Unlike existing methods primarily focused on navigating the robot toward objects, our approach considers the additional challenge of centering the object within the robot's camera view. Our method builds a visual language pose graph (VLPG) that functions as a spatial map of VL embeddings. Given an open vocabulary object query, we plan a viewpoint for object navigation using the VLPG. Despite navigating to the viewpoint, real-world challenges like object occlusion, displacement, and the robot's localization error can prevent visibility. We build an object localization probability map that leverages the robot's current observations and prior VLPG. When the object isn't visible, the probability map is updated and an alternate viewpoint is computed. In addition, we propose an object-centering formulation that locally adjusts the robot's pose to center the object in the camera view. We evaluate the effectiveness of our approach through simulations and real-world experiments, evaluating its ability to successfully view and center the object within the camera field of view. VLPG-Nav demonstrates improved performance in locating the object, navigating around occlusions, and centering the object within the robot's camera view, outperforming the selected baselines in the evaluation metrics.
Read more8/16/2024

0
Visual-Geometry GP-based Navigable Space for Autonomous Navigation
Mahmoud Ali, Durgkant Pushp, Zheng Chen, Lantao Liu
Autonomous navigation in unknown environments is challenging and demands the consideration of both geometric and semantic information in order to parse the navigability of the environment. In this work, we propose a novel space modeling framework, Visual-Geometry Sparse Gaussian Process (VG-SGP), that simultaneously considers semantics and geometry of the scene. Our proposed approach can overcome the limitation of visual planners that fail to recognize geometry associated with the semantic and the geometric planners that completely overlook the semantic information which is very critical in real-world navigation. The proposed method leverages dual Sparse Gaussian Processes in an integrated manner; the first is trained to forecast geometrically navigable spaces while the second predicts the semantically navigable areas. This integrated model is able to pinpoint the overlapping (geometric and semantic) navigable space. The simulation and real-world experiments demonstrate that the ability of the proposed VG-SGP model, coupled with our innovative navigation strategy, outperforms models solely reliant on visual or geometric navigation algorithms, highlighting a superior adaptive behavior.
Read more7/10/2024