Aligning Large Language Models with Human Preferences through Representation Engineering

0

Sign in to get full access
Overview
- This paper explores methods for aligning large language models (LLMs) with human preferences through "representation engineering" - the process of modifying the internal representations of an LLM to better match human values and objectives.
- The authors investigate different approaches to representation engineering, including using iterated amplification and debate to refine the model's internal representations.
- The goal is to create LLMs that are more trustworthy, reliable, and aligned with human values, addressing concerns about the potential negative impacts of powerful AI systems.
Plain English Explanation
Large language models (LLMs) like GPT-3 are incredibly powerful AI systems that can generate human-like text on a wide range of topics. However, as these models become more advanced, there are growing concerns about ensuring they behave in ways that are aligned with human values and preferences.
The researchers in this paper explore different methods for "representation engineering" - modifying the internal representations and decision-making processes of LLMs to better match what humans want and value. This could involve techniques like "iterated amplification," where the model is iteratively refined through interaction with humans, or "debate," where the model is trained to consider multiple perspectives on an issue.
The key idea is to create LLMs that are not only highly capable, but also trustworthy and reliable - systems that we can depend on to make decisions and take actions that are consistent with human ethics and goals. This is an important challenge as these models become increasingly powerful and influential in our lives.
By developing more "human-aligned" LLMs through representation engineering, the researchers hope to unlock the immense potential of these AI systems while mitigating the risks of unintended negative consequences. This could lead to AI assistants, decision-support tools, and other applications that we can use with greater confidence and trust.
Technical Explanation
The paper explores different approaches to aligning large language models with human preferences, a key challenge in the development of powerful AI systems. The authors focus on "representation engineering" - the process of modifying the internal representations and decision-making mechanisms of large language models (LLMs) to better match human values and objectives.
One key technique investigated is iterated amplification, where the model is iteratively refined through interaction with humans. This allows the model's internal representations to be shaped by direct feedback and oversight from people. The authors also explore the use of debate, where the model is trained to consider multiple perspectives on an issue, as a way to instill more nuanced and human-aligned decision-making.
The goal is to create LLMs that are not only highly capable, but also more reliably aligned with human preferences - systems that can be trusted to make decisions and take actions that are consistent with human ethics and values. This is a critical challenge as these models become increasingly powerful and influential.
The authors suggest that by developing more "human-aligned" LLMs through representation engineering, we can unlock the immense potential of these AI systems while mitigating the risks of unintended negative consequences. This could lead to AI assistants, decision-support tools, and other applications that we can use with greater confidence and trust.
Critical Analysis
The researchers present a compelling approach to the important challenge of aligning large language models with human preferences. Representation engineering, with techniques like iterated amplification and debate, offers a promising path towards creating LLMs that are not only highly capable, but also reliably aligned with human values and ethics.
One potential limitation is the difficulty of fully capturing the nuance and complexity of human preferences through iterative interactions or structured debate. There may be biases or blind spots in the feedback provided by the human participants involved. Careful consideration of participant selection and the scope of the interactions will be crucial.
Additionally, the authors acknowledge that scaling these techniques to the largest and most powerful LLMs may pose significant technical and computational challenges. Ensuring the integrity and reliability of the representation engineering process will be critical as these models grow in scale and influence.
Overall, this research represents an important step towards developing AI systems that are not just powerful, but also trustworthy and beneficial to humanity. Continued work in this area, with a focus on rigorous testing and validation, will be essential as large language models become increasingly central to our lives and decision-making processes.
Conclusion
This paper presents a novel approach to aligning large language models with human preferences through "representation engineering" - modifying the internal representations and decision-making processes of these powerful AI systems to better match human values and objectives.
By exploring techniques like iterated amplification and debate, the researchers aim to create LLMs that are not only highly capable, but also reliably aligned with human ethics and goals. This is a crucial challenge as these models become increasingly influential in our lives.
While the proposed methods show promise, there are important limitations and challenges that will need to be addressed through continued research and development. Ensuring the integrity and trustworthiness of these human-aligned LLMs will be essential as they become more integral to our decision-making and problem-solving processes.
Overall, this work represents an important step towards unlocking the potential of large language models while mitigating the risks of unintended negative consequences. As AI systems become more capable and ubiquitous, developing techniques to align them with human preferences will be crucial for realizing the technology's benefits while protecting against its potential harms.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Aligning Large Language Models with Human Preferences through Representation Engineering
Wenhao Liu, Xiaohua Wang, Muling Wu, Tianlong Li, Changze Lv, Zixuan Ling, Jianhao Zhu, Cenyuan Zhang, Xiaoqing Zheng, Xuanjing Huang
Aligning large language models (LLMs) with human preferences is crucial for enhancing their utility in terms of helpfulness, truthfulness, safety, harmlessness, and interestingness. Existing methods for achieving this alignment often involves employing reinforcement learning from human feedback (RLHF) to fine-tune LLMs based on human labels assessing the relative quality of model responses. Nevertheless, RLHF is susceptible to instability during fine-tuning and presents challenges in implementation.Drawing inspiration from the emerging field of representation engineering (RepE), this study aims to identify relevant representations for high-level human preferences embedded in patterns of activity within an LLM, and achieve precise control of model behavior by transforming its representations. This novel approach, denoted as Representation Alignment from Human Feedback (RAHF), proves to be effective, computationally efficient, and easy to implement.Extensive experiments demonstrate the efficacy of RAHF in not only capturing but also manipulating representations to align with a broad spectrum of human preferences or values, rather than being confined to a singular concept or function (e.g. honesty or bias). RAHF's versatility in accommodating diverse human preferences shows its potential for advancing LLM performance.
Read more7/4/2024
0
More RLHF, More Trust? On The Impact of Human Preference Alignment On Language Model Trustworthiness
Aaron J. Li, Satyapriya Krishna, Himabindu Lakkaraju
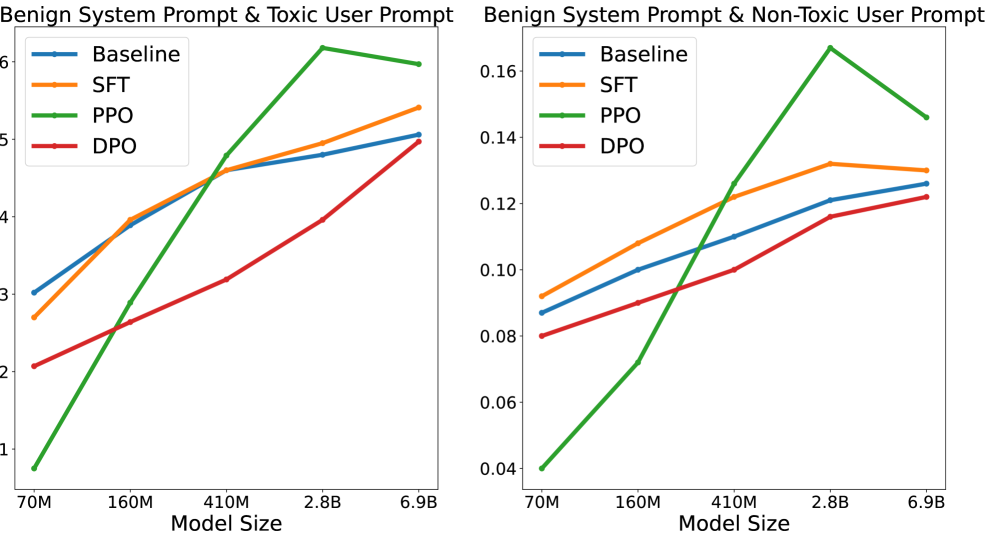
The surge in Large Language Models (LLMs) development has led to improved performance on cognitive tasks as well as an urgent need to align these models with human values in order to safely exploit their power. Despite the effectiveness of preference learning algorithms like Reinforcement Learning From Human Feedback (RLHF) in aligning human preferences, their assumed improvements on model trustworthiness haven't been thoroughly testified. Toward this end, this study investigates how models that have been aligned with general-purpose preference data on helpfulness and harmlessness perform across five trustworthiness verticals: toxicity, stereotypical bias, machine ethics, truthfulness, and privacy. For model alignment, we focus on three widely used RLHF variants: Supervised Finetuning (SFT), Proximal Policy Optimization (PPO), and Direct Preference Optimization (DPO). Through extensive empirical investigations, we discover that the improvement in trustworthiness by RLHF is far from guaranteed, and there exists a complex interplay between preference data, alignment algorithms, and specific trustworthiness aspects. Together, our results underscore the need for more nuanced approaches for model alignment. By shedding light on the intricate dynamics of these components within model alignment, we hope this research will guide the community towards developing language models that are both capable and trustworthy.
Read more4/30/2024
💬
0
Aligning language models with human preferences
Tomasz Korbak
Language models (LMs) trained on vast quantities of text data can acquire sophisticated skills such as generating summaries, answering questions or generating code. However, they also manifest behaviors that violate human preferences, e.g., they can generate offensive content, falsehoods or perpetuate social biases. In this thesis, I explore several approaches to aligning LMs with human preferences. First, I argue that aligning LMs can be seen as Bayesian inference: conditioning a prior (base, pretrained LM) on evidence about human preferences (Chapter 2). Conditioning on human preferences can be implemented in numerous ways. In Chapter 3, I investigate the relation between two approaches to finetuning pretrained LMs using feedback given by a scoring function: reinforcement learning from human feedback (RLHF) and distribution matching. I show that RLHF can be seen as a special case of distribution matching but distributional matching is strictly more general. In chapter 4, I show how to extend the distribution matching to conditional language models. Finally, in chapter 5 I explore a different root: conditioning an LM on human preferences already during pretraining. I show that involving human feedback from the very start tends to be more effective than using it only during supervised finetuning. Overall, these results highlight the room for alignment techniques different from and complementary to RLHF.
Read more4/19/2024
💬
0
The Real, the Better: Aligning Large Language Models with Online Human Behaviors
Guanying Jiang, Lingyong Yan, Haibo Shi, Dawei Yin
Large language model alignment is widely used and studied to avoid LLM producing unhelpful and harmful responses. However, the lengthy training process and predefined preference bias hinder adaptation to online diverse human preferences. To this end, this paper proposes an alignment framework, called Reinforcement Learning with Human Behavior (RLHB), to align LLMs by directly leveraging real online human behaviors. By taking the generative adversarial framework, the generator is trained to respond following expected human behavior; while the discriminator tries to verify whether the triplets of query, response, and human behavior come from real online environments. Behavior modeling in natural-language form and the multi-model joint training mechanism enable an active and sustainable online alignment. Experimental results confirm the effectiveness of our proposed methods by both human and automatic evaluations.
Read more5/2/2024