Is Free Self-Alignment Possible?
2406.03642
0
0

Abstract
Aligning pretrained language models (LMs) is a complex and resource-intensive process, often requiring access to large amounts of ground-truth preference data and substantial compute. Are these costs necessary? That is, it is possible to align using only inherent model knowledge and without additional training? We tackle this challenge with AlignEZ, a novel approach that uses (1) self-generated preference data and (2) representation editing to provide nearly cost-free alignment. During inference, AlignEZ modifies LM representations to reduce undesirable and boost desirable components using subspaces identified via self-generated preference pairs. Our experiments reveal that this nearly cost-free procedure significantly narrows the gap between base pretrained and tuned models by an average of 31.6%, observed across six datasets and three model architectures. Additionally, we explore the potential of using AlignEZ as a means of expediting more expensive alignment procedures. Our experiments show that AlignEZ improves DPO models tuned only using a small subset of ground-truth preference data. Lastly, we study the conditions under which improvement using AlignEZ is feasible, providing valuable insights into its effectiveness.
Create account to get full access
Overview
- This paper explores the possibility of achieving "free self-alignment" - the idea that language models could align themselves with human values and preferences without the need for explicit training or oversight.
- The authors investigate the theoretical feasibility of this concept and discuss the potential benefits and challenges associated with free self-alignment.
- The paper reviews related work in the field of language model alignment, including efforts to align language models with human preferences and decoupled alignment.
Plain English Explanation
The paper examines whether it's possible for language models, like large AI chatbots, to naturally align themselves with human values and preferences without requiring extensive training or supervision. The idea is that the models could, on their own, develop an understanding of what's beneficial for humans and act accordingly.
This could be beneficial because it might allow for the creation of highly capable AI assistants that are reliably aligned with human interests, without the need for constant monitoring or complex alignment procedures. However, the authors investigate whether this kind of "free self-alignment" is theoretically feasible, and discuss the potential challenges and limitations.
The paper reviews related research, such as efforts to directly train language models to align with human preferences and techniques for decoupling the alignment process from the core model training. This provides context for understanding the potential benefits and drawbacks of the free self-alignment approach.
Technical Explanation
The paper examines the theoretical possibility of "free self-alignment" - the idea that language models could independently develop an alignment with human values and preferences, without the need for explicit training or oversight.
The authors review related work in the field of language model alignment, including techniques like latent distance-guided alignment and adversarial critic-based approaches. These methods aim to train language models to be aligned with human preferences, but require the use of specialized alignment procedures.
In contrast, the free self-alignment concept suggests that language models could, through their own learning process, naturally develop an understanding of human values and preferences, and then act accordingly. This could potentially simplify the alignment problem and lead to more robust and reliable AI assistants.
The paper explores the theoretical feasibility of this idea, considering factors like the objective function of the language model, the properties of the training data, and the model's internal dynamics. The authors also discuss potential challenges, such as the difficulty of specifying and measuring alignment, and the risk of unintended consequences.
Critical Analysis
The paper raises some important questions about the feasibility of free self-alignment, and the potential tradeoffs involved. While the idea is intriguing, the authors acknowledge that there are significant challenges and open questions that would need to be addressed.
One key concern is the difficulty of specifying and measuring alignment in a robust and comprehensive way. The paper notes that human values and preferences can be complex, multifaceted, and even contradictory, making it difficult for a language model to reliably internalize and act upon them.
Additionally, the authors suggest that free self-alignment could be vulnerable to unintended consequences, where the model's internal dynamics lead to behaviors that are not actually aligned with human interests. This could be particularly problematic if the model's self-alignment process is opaque or difficult to interpret.
The paper also raises questions about the scalability and generalizability of the free self-alignment approach. The authors note that it may be challenging to achieve robust alignment at the scale required for large-scale language models and AI assistants.
Overall, the paper provides a thoughtful exploration of the free self-alignment concept, highlighting both its potential benefits and significant challenges. It encourages readers to think critically about the alignment problem and consider alternative approaches, such as the decoupled alignment and adversarial critic-based methods discussed in the related work.
Conclusion
This paper explores the intriguing idea of "free self-alignment" - the possibility that language models could independently develop an alignment with human values and preferences, without the need for explicit training or oversight. While the concept is compelling, the authors identify significant theoretical and practical challenges that would need to be addressed.
The paper's analysis suggests that reliably achieving free self-alignment may be difficult, given the complexity of human values, the risk of unintended consequences, and the scalability issues involved. However, the authors encourage further research and exploration of this idea, as well as continued efforts to develop more robust and reliable language model alignment techniques, such as the decoupled alignment and adversarial critic-based approaches discussed in the related work.
Ultimately, the paper provides a thought-provoking perspective on the challenges and potential benefits of language model alignment, and highlights the need for continued innovation and careful consideration in the development of advanced AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Aligning Large Language Models with Self-generated Preference Data
Dongyoung Kim, Kimin Lee, Jinwoo Shin, Jaehyung Kim
0
0
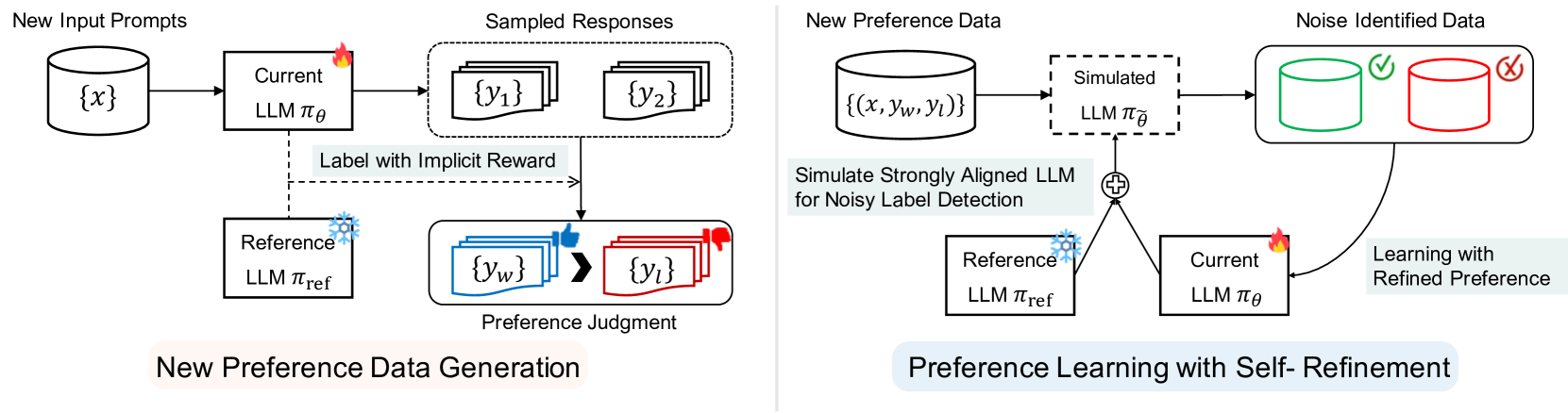
Aligning large language models (LLMs) with human preferences becomes a key component to obtaining state-of-the-art performance, but it yields a huge cost to construct a large human-annotated preference dataset. To tackle this problem, we propose a new framework that boosts the alignment of LLMs through Self-generated Preference data (Selfie) using only a very small amount of human-annotated preference data. Our key idea is leveraging the human prior knowledge within the small (seed) data and progressively improving the alignment of LLM, by iteratively generating the responses and learning from them with the self-annotated preference data. To be specific, we propose to derive the preference label from the logits of LLM to explicitly extract the model's inherent preference. Compared to the previous approaches using external reward models or implicit in-context learning, we observe that the proposed approach is significantly more effective. In addition, we introduce a noise-aware preference learning algorithm to mitigate the risk of low quality within generated preference data. Our experimental results demonstrate that the proposed framework significantly boosts the alignment of LLMs. For example, we achieve superior alignment performance on AlpacaEval 2.0 with only 3.3% of the ground-truth preference labels in the Ultrafeedback data compared to the cases using the entire data or state-of-the-art baselines.
6/10/2024
⚙️
Aligner: Efficient Alignment by Learning to Correct
Jiaming Ji, Boyuan Chen, Hantao Lou, Donghai Hong, Borong Zhang, Xuehai Pan, Juntao Dai, Tianyi Qiu, Yaodong Yang
0
0
With the rapid development of large language models (LLMs) and ever-evolving practical requirements, finding an efficient and effective alignment method has never been more critical. However, the tension between the complexity of current alignment methods and the need for rapid iteration in deployment scenarios necessitates the development of a model-agnostic alignment approach that can operate under these constraints. In this paper, we introduce Aligner, a novel and simple alignment paradigm that learns the correctional residuals between preferred and dispreferred answers using a small model. Designed as a model-agnostic, plug-and-play module, Aligner can be directly applied to various open-source and API-based models with only one-off training, making it suitable for rapid iteration. Notably, Aligner can be applied to any powerful, large-scale upstream models. Moreover, it can even iteratively bootstrap the upstream models using corrected responses as synthetic human preference data, breaking through the model's performance ceiling. Our experiments demonstrate performance improvements by deploying the same Aligner model across 11 different LLMs, evaluated on the 3H dimensions (helpfulness, harmlessness, and honesty). Specifically, Aligner-7B has achieved an average improvement of 68.9% in helpfulness and 23.8% in harmlessness across the tested LLMs while also effectively reducing hallucination. In the Alpaca-Eval leaderboard, stacking Aligner-2B on GPT-4 Turbo improved its LC Win Rate from 55.0% to 58.3%, surpassing GPT-4 Omni's 57.5% Win Rate (community report).
6/4/2024
Language Models Resist Alignment
Jiaming Ji, Kaile Wang, Tianyi Qiu, Boyuan Chen, Jiayi Zhou, Changye Li, Hantao Lou, Yaodong Yang
0
0
Large language models (LLMs) may exhibit undesirable behaviors. Recent efforts have focused on aligning these models to prevent harmful generation. Despite these efforts, studies have shown that even a well-conducted alignment process can be easily circumvented, whether intentionally or accidentally. Do alignment fine-tuning have robust effects on models, or are merely superficial? In this work, we answer this question through both theoretical and empirical means. Empirically, we demonstrate the elasticity of post-alignment models, i.e., the tendency to revert to the behavior distribution formed during the pre-training phase upon further fine-tuning. Using compression theory, we formally derive that such fine-tuning process disproportionately undermines alignment compared to pre-training, potentially by orders of magnitude. We conduct experimental validations to confirm the presence of elasticity across models of varying types and sizes. Specifically, we find that model performance declines rapidly before reverting to the pre-training distribution, after which the rate of decline drops significantly. We further reveal that elasticity positively correlates with increased model size and the expansion of pre-training data. Our discovery signifies the importance of taming the inherent elasticity of LLMs, thereby overcoming the resistance of LLMs to alignment finetuning.
6/14/2024
🖼️
Aligners: Decoupling LLMs and Alignment
Lilian Ngweta, Mayank Agarwal, Subha Maity, Alex Gittens, Yuekai Sun, Mikhail Yurochkin
0
0
Large Language Models (LLMs) need to be aligned with human expectations to ensure their safety and utility in most applications. Alignment is challenging, costly, and needs to be repeated for every LLM and alignment criterion. We propose to decouple LLMs and alignment by training aligner models that can be used to align any LLM for a given criteria on an as-needed basis, thus also reducing the potential negative impacts of alignment on performance. Our recipe for training the aligner models solely relies on synthetic data generated with a (prompted) LLM and can be easily adjusted for a variety of alignment criteria. We use the same synthetic data to train inspectors, binary miss-alignment classification models to guide a squad of multiple aligners. Our empirical results demonstrate consistent improvements when applying aligner squad to various LLMs, including chat-aligned models, across several instruction-following and red-teaming datasets.
6/18/2024