Aligning (Medical) LLMs for (Counterfactual) Fairness

0
Sign in to get full access
Overview
- The paper examines the challenge of aligning large language models (LLMs) with principles of fairness and non-discrimination, particularly in the context of medical applications.
- It presents a comprehensive evaluation of bias patterns in LLMs and explores approaches for mitigating these biases to ensure fair and equitable outcomes.
- The research focuses on counterfactual fairness, which aims to ensure that model predictions are not influenced by protected attributes like race, gender, or socioeconomic status.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text on a wide range of topics. However, these models can also reflect and amplify societal biases, potentially leading to unfair or discriminatory outcomes, especially in sensitive domains like healthcare.
The researchers in this paper set out to thoroughly investigate the bias patterns present in LLMs and explore ways to "align" these models with principles of fairness and non-discrimination. They focus on the concept of counterfactual fairness, which means ensuring that a model's predictions are not influenced by factors like race, gender, or socioeconomic status.
By conducting a comprehensive evaluation of bias patterns in LLMs, the researchers aim to identify the specific areas where these models fall short in terms of fairness. This knowledge can then be used to develop techniques to mitigate these biases and create more equitable and fair AI systems, especially in critical domains like healthcare decision-making.
Technical Explanation
The paper presents a comprehensive evaluation of bias patterns in LLMs, with a focus on medical applications. The researchers use a range of fairness metrics to assess the models' performance across different demographic groups, including measures of counterfactual fairness.
The study explores various bias mitigation techniques, such as fine-tuning the models on debiased datasets or incorporating fairness-aware loss functions during training. The researchers also investigate the impact of different architectural choices and prompting strategies on the models' fairness performance.
Through their experiments, the researchers identify significant bias patterns in LLMs, particularly in areas like clinical decision-making and risk assessment. They also demonstrate the effectiveness of certain debiasing approaches in improving the models' fairness, while acknowledging the inherent challenges in achieving perfect fairness.
Critical Analysis
The paper provides a thorough and well-designed evaluation of bias patterns in LLMs, highlighting the importance of ensuring fairness and non-discrimination in the deployment of these powerful AI systems, especially in high-stakes domains like healthcare.
One potential limitation of the research is the reliance on a limited set of fairness metrics, which may not capture all aspects of bias and fairness. Additionally, the effectiveness of the proposed debiasing techniques may depend on the specific dataset and task, and further research is needed to understand their generalizability.
It would also be valuable to explore the impact of different architectural choices and training strategies on the models' fairness, as well as the trade-offs between fairness and other desirable model properties, such as accuracy and robustness.
Conclusion
This paper makes an important contribution to the growing body of research on fairness in LLMs. By conducting a comprehensive evaluation of bias patterns and exploring effective debiasing approaches, the researchers have taken a significant step towards ensuring that these powerful AI systems are aligned with principles of fairness and non-discrimination, particularly in critical applications like medical decision support.
The insights from this work can inform the development of more equitable and inclusive AI systems, which will be crucial as LLMs become increasingly prevalent in various domains. Continued research and collaboration in this area will be essential to addressing the challenge of bias and fairness in large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Aligning (Medical) LLMs for (Counterfactual) Fairness
Raphael Poulain, Hamed Fayyaz, Rahmatollah Beheshti
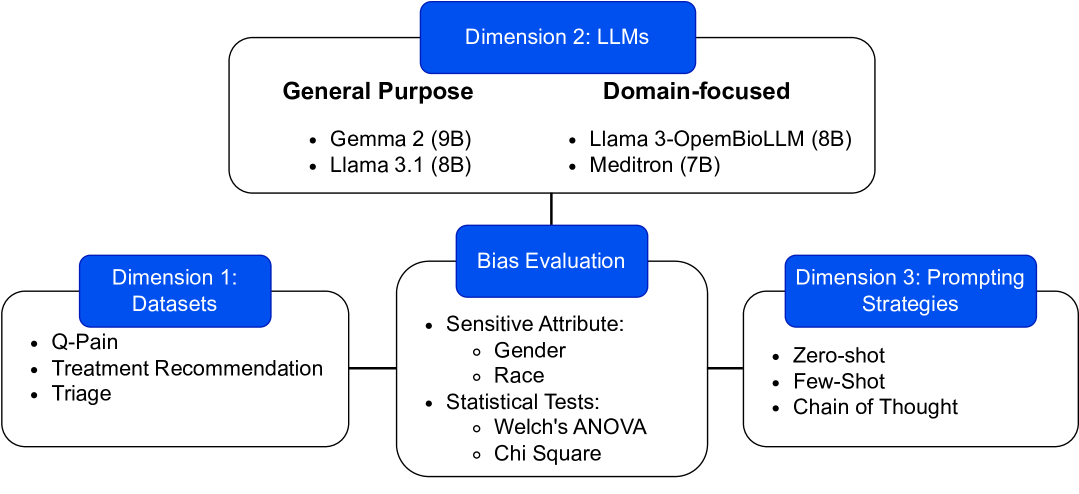
Large Language Models (LLMs) have emerged as promising solutions for a variety of medical and clinical decision support applications. However, LLMs are often subject to different types of biases, which can lead to unfair treatment of individuals, worsening health disparities, and reducing trust in AI-augmented medical tools. Aiming to address this important issue, in this study, we present a new model alignment approach for aligning LLMs using a preference optimization method within a knowledge distillation framework. Prior to presenting our proposed method, we first use an evaluation framework to conduct a comprehensive (largest to our knowledge) empirical evaluation to reveal the type and nature of existing biases in LLMs used for medical applications. We then offer a bias mitigation technique to reduce the unfair patterns in LLM outputs across different subgroups identified by the protected attributes. We show that our mitigation method is effective in significantly reducing observed biased patterns. Our code is publicly available at url{https://github.com/healthylaife/FairAlignmentLLM}.
Read more8/23/2024
🌀
0
Bias patterns in the application of LLMs for clinical decision support: A comprehensive study
Raphael Poulain, Hamed Fayyaz, Rahmatollah Beheshti
Large Language Models (LLMs) have emerged as powerful candidates to inform clinical decision-making processes. While these models play an increasingly prominent role in shaping the digital landscape, two growing concerns emerge in healthcare applications: 1) to what extent do LLMs exhibit social bias based on patients' protected attributes (like race), and 2) how do design choices (like architecture design and prompting strategies) influence the observed biases? To answer these questions rigorously, we evaluated eight popular LLMs across three question-answering (QA) datasets using clinical vignettes (patient descriptions) standardized for bias evaluations. We employ red-teaming strategies to analyze how demographics affect LLM outputs, comparing both general-purpose and clinically-trained models. Our extensive experiments reveal various disparities (some significant) across protected groups. We also observe several counter-intuitive patterns such as larger models not being necessarily less biased and fined-tuned models on medical data not being necessarily better than the general-purpose models. Furthermore, our study demonstrates the impact of prompt design on bias patterns and shows that specific phrasing can influence bias patterns and reflection-type approaches (like Chain of Thought) can reduce biased outcomes effectively. Consistent with prior studies, we call on additional evaluations, scrutiny, and enhancement of LLMs used in clinical decision support applications.
Read more4/24/2024
💬
0
Fairness in Large Language Models in Three Hour
Thang Doan Viet, Zichong Wang, Minh Nhat Nguyen, Wenbin Zhang
Large Language Models (LLMs) have demonstrated remarkable success across various domains but often lack fairness considerations, potentially leading to discriminatory outcomes against marginalized populations. Unlike fairness in traditional machine learning, fairness in LLMs involves unique backgrounds, taxonomies, and fulfillment techniques. This tutorial provides a systematic overview of recent advances in the literature concerning fair LLMs, beginning with real-world case studies to introduce LLMs, followed by an analysis of bias causes therein. The concept of fairness in LLMs is then explored, summarizing the strategies for evaluating bias and the algorithms designed to promote fairness. Additionally, resources for assessing bias in LLMs, including toolkits and datasets, are compiled, and current research challenges and open questions in the field are discussed. The repository is available at url{https://github.com/LavinWong/Fairness-in-Large-Language-Models}.
Read more8/6/2024
💬
0
Bias and Fairness in Large Language Models: A Survey
Isabel O. Gallegos, Ryan A. Rossi, Joe Barrow, Md Mehrab Tanjim, Sungchul Kim, Franck Dernoncourt, Tong Yu, Ruiyi Zhang, Nesreen K. Ahmed
Rapid advancements of large language models (LLMs) have enabled the processing, understanding, and generation of human-like text, with increasing integration into systems that touch our social sphere. Despite this success, these models can learn, perpetuate, and amplify harmful social biases. In this paper, we present a comprehensive survey of bias evaluation and mitigation techniques for LLMs. We first consolidate, formalize, and expand notions of social bias and fairness in natural language processing, defining distinct facets of harm and introducing several desiderata to operationalize fairness for LLMs. We then unify the literature by proposing three intuitive taxonomies, two for bias evaluation, namely metrics and datasets, and one for mitigation. Our first taxonomy of metrics for bias evaluation disambiguates the relationship between metrics and evaluation datasets, and organizes metrics by the different levels at which they operate in a model: embeddings, probabilities, and generated text. Our second taxonomy of datasets for bias evaluation categorizes datasets by their structure as counterfactual inputs or prompts, and identifies the targeted harms and social groups; we also release a consolidation of publicly-available datasets for improved access. Our third taxonomy of techniques for bias mitigation classifies methods by their intervention during pre-processing, in-training, intra-processing, and post-processing, with granular subcategories that elucidate research trends. Finally, we identify open problems and challenges for future work. Synthesizing a wide range of recent research, we aim to provide a clear guide of the existing literature that empowers researchers and practitioners to better understand and prevent the propagation of bias in LLMs.
Read more7/16/2024