AnimateZoo: Zero-shot Video Generation of Cross-Species Animation via Subject Alignment
2404.04946
0
0

Abstract
Recent video editing advancements rely on accurate pose sequences to animate subjects. However, these efforts are not suitable for cross-species animation due to pose misalignment between species (for example, the poses of a cat differs greatly from that of a pig due to differences in body structure). In this paper, we present AnimateZoo, a zero-shot diffusion-based video generator to address this challenging cross-species animation issue, aiming to accurately produce animal animations while preserving the background. The key technique used in our AnimateZoo is subject alignment, which includes two steps. First, we improve appearance feature extraction by integrating a Laplacian detail booster and a prompt-tuning identity extractor. These components are specifically designed to capture essential appearance information, including identity and fine details. Second, we align shape features and address conflicts from differing subjects by introducing a scale-information remover. This ensures accurate cross-species animation. Moreover, we introduce two high-quality animal video datasets featuring a wide variety of species. Trained on these extensive datasets, our model is capable of generating videos characterized by accurate movements, consistent appearance, and high-fidelity frames, without the need for the pre-inference fine-tuning that prior arts required. Extensive experiments showcase the outstanding performance of our method in cross-species action following tasks, demonstrating exceptional shape adaptation capability. The project page is available at https://justinxu0.github.io/AnimateZoo/.
Create account to get full access
Overview
- This paper presents a novel approach called "AnimateZoo" for generating zero-shot video animations of cross-species characters.
- The key innovation is a subject alignment technique that allows the model to transfer motion and expressions from one species to another without requiring any additional training data or manual animation.
- The authors demonstrate the effectiveness of their method on a variety of animal characters, showing how it can be used to create seamless and lifelike animations.
Plain English Explanation
The paper introduces a new way to create animated videos of different types of animals, without needing to train the model on a lot of data for each specific animal. The core idea is to align the subject - that is, match up the key features and movement of one animal with another, even if they are very different species. This mitigates objective misalignment that can occur when trying to animate completely new characters.
The authors show that their cross-attention approach can take motion capture data of one animal, like a dog, and transfer it to animate a very different animal, like a lion or a bird, in a way that looks natural and lifelike. This zero-shot capability means the model doesn't have to be retrained from scratch for each new animal - it can generalize to animate all sorts of creatures.
Technical Explanation
The key technical contribution of this paper is the AnimateZoo framework, which combines several novel components to enable zero-shot cross-species video animation:
-
Subject Alignment Module: This module learns to map the keypoints and motion of one animal subject onto the corresponding anatomy of a different animal. It does this in a self-supervised way by leveraging paired video data of various animal species.
-
Motion Transfer Network: This network takes the aligned subject information and the source video frames as input, and generates new video frames that seamlessly animate the target animal species.
-
Adversarial Training: The authors employ an adversarial training strategy, where a discriminator network is trained to distinguish real from generated videos. This helps improve the realism and coherence of the final animations.
The authors evaluate AnimateZoo on a diverse set of animal characters, including mammals, birds, and reptiles. Their results demonstrate that the model can generate high-quality, lifelike animations in a zero-shot setting, without requiring any manual keyframing or per-character training.
Critical Analysis
One potential limitation of the AnimateZoo approach is that it relies on having access to a suitable dataset of paired animal videos for the subject alignment training. The authors show good results on their curated dataset, but it's unclear how well the method would generalize to more exotic or rare animal species with limited available video data.
Additionally, while the zero-shot capability is impressive, the generated animations may still lack some of the nuance and expressiveness of manually animated characters. Further research could explore ways to better capture the unique motion characteristics and personality of different animal species.
Finally, the ethical implications of this technology are worth considering, as it could potentially be misused to create misleading or deceptive media. The authors do not address these concerns in the paper, and it would be valuable for future work to consider responsible deployment and safeguards.
Conclusion
Overall, the AnimateZoo framework represents an exciting advancement in the field of video animation, enabling the creation of high-quality, cross-species animations without the need for extensive manual work or per-character training. This zero-shot capability has the potential to streamline the animation process and open up new creative possibilities for filmmakers, game developers, and other content creators. As the technology continues to evolve, it will be important to address the potential challenges and ethical considerations to ensure it is used in a responsible and beneficial manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

PoseAnimate: Zero-shot high fidelity pose controllable character animation
Bingwen Zhu, Fanyi Wang, Tianyi Lu, Peng Liu, Jingwen Su, Jinxiu Liu, Yanhao Zhang, Zuxuan Wu, Guo-Jun Qi, Yu-Gang Jiang
0
0
Image-to-video (I2V) generation aims to create a video sequence from a single image, which requires high temporal coherence and visual fidelity. However, existing approaches suffer from inconsistency of character appearances and poor preservation of fine details. Moreover, they require a large amount of video data for training, which can be computationally demanding. To address these limitations, we propose PoseAnimate, a novel zero-shot I2V framework for character animation. PoseAnimate contains three key components: 1) a Pose-Aware Control Module (PACM) that incorporates diverse pose signals into text embeddings, to preserve character-independent content and maintain precise alignment of actions. 2) a Dual Consistency Attention Module (DCAM) that enhances temporal consistency and retains character identity and intricate background details. 3) a Mask-Guided Decoupling Module (MGDM) that refines distinct feature perception abilities, improving animation fidelity by decoupling the character and background. We also propose a Pose Alignment Transition Algorithm (PATA) to ensure smooth action transition. Extensive experiment results demonstrate that our approach outperforms the state-of-the-art training-based methods in terms of character consistency and detail fidelity. Moreover, it maintains a high level of temporal coherence throughout the generated animations.
6/6/2024

ID-Animator: Zero-Shot Identity-Preserving Human Video Generation
Xuanhua He, Quande Liu, Shengju Qian, Xin Wang, Tao Hu, Ke Cao, Keyu Yan, Jie Zhang
0
0
Generating high fidelity human video with specified identities has attracted significant attention in the content generation community. However, existing techniques struggle to strike a balance between training efficiency and identity preservation, either requiring tedious case-by-case finetuning or usually missing the identity details in video generation process. In this study, we present ID-Animator, a zero-shot human-video generation approach that can perform personalized video generation given single reference facial image without further training. ID-Animator inherits existing diffusion-based video generation backbones with a face adapter to encode the ID-relevant embeddings from learnable facial latent queries. To facilitate the extraction of identity information in video generation, we introduce an ID-oriented dataset construction pipeline, which incorporates decoupled human attribute and action captioning technique from a constructed facial image pool. Based on this pipeline, a random face reference training method is further devised to precisely capture the ID-relevant embeddings from reference images, thus improving the fidelity and generalization capacity of our model for ID-specific video generation. Extensive experiments demonstrate the superiority of ID-Animator to generate personalized human videos over previous models. Moreover, our method is highly compatible with popular pre-trained T2V models like animatediff and various community backbone models, showing high extendability in real-world applications for video generation where identity preservation is highly desired. Our codes and checkpoints will be released at https://github.com/ID-Animator/ID-Animator.
5/15/2024
👁️
Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation
Li Hu, Xin Gao, Peng Zhang, Ke Sun, Bang Zhang, Liefeng Bo
0
0
Character Animation aims to generating character videos from still images through driving signals. Currently, diffusion models have become the mainstream in visual generation research, owing to their robust generative capabilities. However, challenges persist in the realm of image-to-video, especially in character animation, where temporally maintaining consistency with detailed information from character remains a formidable problem. In this paper, we leverage the power of diffusion models and propose a novel framework tailored for character animation. To preserve consistency of intricate appearance features from reference image, we design ReferenceNet to merge detail features via spatial attention. To ensure controllability and continuity, we introduce an efficient pose guider to direct character's movements and employ an effective temporal modeling approach to ensure smooth inter-frame transitions between video frames. By expanding the training data, our approach can animate arbitrary characters, yielding superior results in character animation compared to other image-to-video methods. Furthermore, we evaluate our method on benchmarks for fashion video and human dance synthesis, achieving state-of-the-art results.
6/14/2024
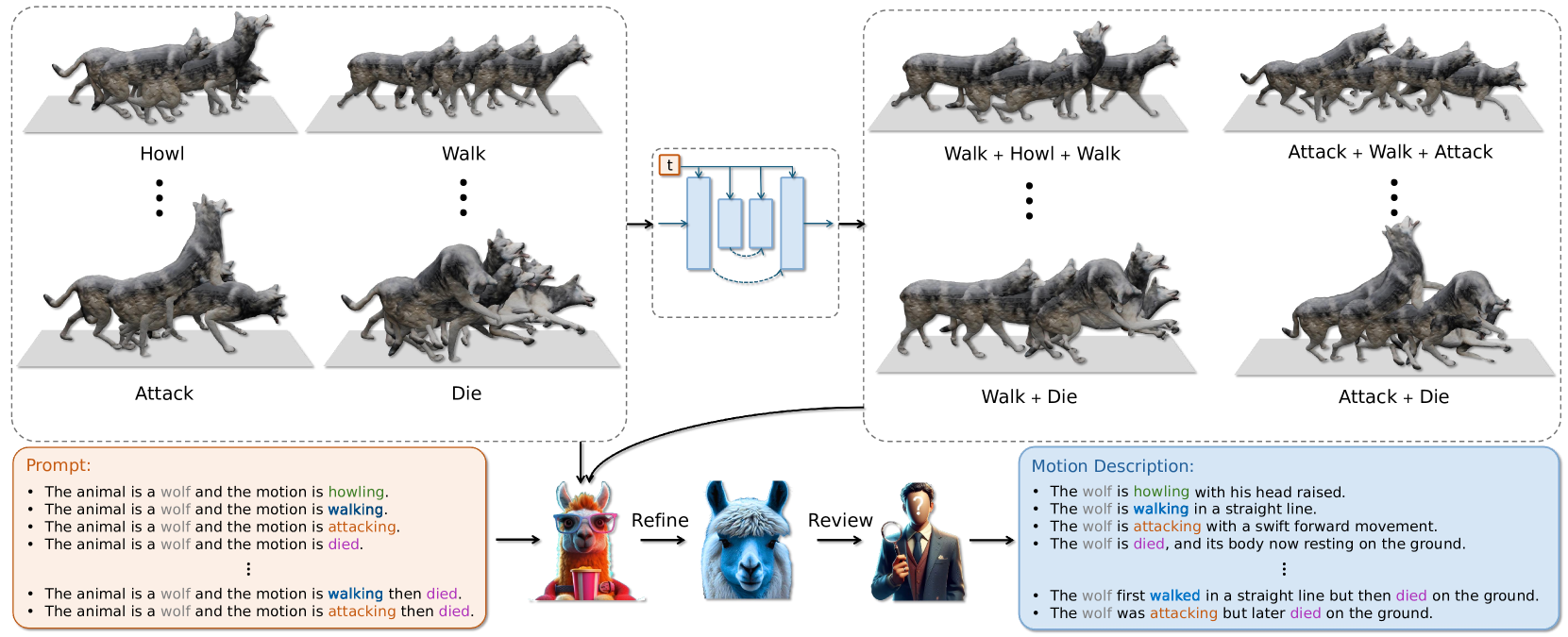
Motion Avatar: Generate Human and Animal Avatars with Arbitrary Motion
Zeyu Zhang, Yiran Wang, Biao Wu, Shuo Chen, Zhiyuan Zhang, Shiya Huang, Wenbo Zhang, Meng Fang, Ling Chen, Yang Zhao
0
0
In recent years, there has been significant interest in creating 3D avatars and motions, driven by their diverse applications in areas like film-making, video games, AR/VR, and human-robot interaction. However, current efforts primarily concentrate on either generating the 3D avatar mesh alone or producing motion sequences, with integrating these two aspects proving to be a persistent challenge. Additionally, while avatar and motion generation predominantly target humans, extending these techniques to animals remains a significant challenge due to inadequate training data and methods. To bridge these gaps, our paper presents three key contributions. Firstly, we proposed a novel agent-based approach named Motion Avatar, which allows for the automatic generation of high-quality customizable human and animal avatars with motions through text queries. The method significantly advanced the progress in dynamic 3D character generation. Secondly, we introduced a LLM planner that coordinates both motion and avatar generation, which transforms a discriminative planning into a customizable Q&A fashion. Lastly, we presented an animal motion dataset named Zoo-300K, comprising approximately 300,000 text-motion pairs across 65 animal categories and its building pipeline ZooGen, which serves as a valuable resource for the community. See project website https://steve-zeyu-zhang.github.io/MotionAvatar/
5/21/2024