C-Pack: Packaged Resources To Advance General Chinese Embedding

0
🛸
Sign in to get full access
Overview
- C-Pack: A comprehensive package of resources for advancing Chinese text embeddings
- Key components:
- C-MTEB: A benchmark for evaluating Chinese text embeddings across 6 tasks and 35 datasets
- C-MTP: A large dataset for training Chinese text embedding models
- C-TEM: A family of Chinese text embedding models that outperform prior work
Plain English Explanation
C-Pack is a collection of tools and resources that significantly improve the field of Chinese text embeddings. It includes three important parts:
-
C-MTEB: This is a thorough benchmark that can be used to test and compare different Chinese text embedding models. It covers 6 different tasks and 35 datasets, providing a comprehensive way to evaluate performance.
-
C-MTP: This is a massive dataset of Chinese text that can be used to train new text embedding models. It includes both labeled and unlabeled data, giving models a lot of material to learn from.
-
C-TEM: These are a series of Chinese text embedding models developed by the researchers. When tested on the C-MTEB benchmark, these models outperform all previous Chinese text embeddings by up to 10%.
In addition to the Chinese resources, the researchers also released English text embedding models and data. Their English models achieved state-of-the-art performance on a separate benchmark, and the English dataset they released is twice as large as the Chinese one.
Overall, C-Pack provides a significant advancement in the field of Chinese text embeddings, with high-quality benchmarks, datasets, and models that can be used by researchers and developers.
Technical Explanation
The C-Pack package includes three key components:
-
C-MTEB: This is a comprehensive Chinese text embedding benchmark that covers 6 different tasks and 35 datasets. It provides a standardized way to evaluate the performance of Chinese text embedding models across a wide range of applications.
-
C-MTP: This is a large dataset of Chinese text, curated from both labeled and unlabeled sources. It contains a massive amount of data that can be used to train high-quality Chinese text embedding models.
-
C-TEM: These are a family of Chinese text embedding models developed by the researchers. When evaluated on the C-MTEB benchmark, these models outperformed all previous state-of-the-art Chinese text embeddings by up to 10%.
The researchers also integrated and optimized the entire suite of training methods used to develop the C-TEM models, ensuring they are as effective as possible.
In addition to the Chinese resources, the researchers released their English text embedding models and data. Their English models achieved state-of-the-art performance on a separate benchmark, the MTEB, and the English dataset they released is twice as large as the Chinese one.
Critical Analysis
The C-Pack resources appear to be a significant advancement in the field of Chinese text embeddings. The comprehensive C-MTEB benchmark and large-scale C-MTP dataset provide valuable tools for researchers and developers working in this area.
However, the paper does not address potential limitations or caveats of the C-Pack resources. For example, it's unclear how the datasets and models might perform on more specialized or domain-specific tasks, or how they might handle regional dialects or less common Chinese language variations.
Additionally, the researchers do not provide much insight into the specific architectures or training approaches used for the C-TEM models or how they compare to other state-of-the-art Chinese text embedding models, such as those developed by leading research groups in the field.
Readers may also want to understand how the C-Pack resources compare to other multilingual text embedding solutions or versatile text embedding approaches that could potentially be applied to the Chinese language.
Conclusion
Overall, the C-Pack package represents a significant advancement in the field of Chinese text embeddings. The comprehensive benchmark, large-scale dataset, and high-performing models provide valuable resources for researchers and developers working in this area.
The release of these resources, along with the researchers' English text embedding models and data, demonstrates their commitment to advancing the state-of-the-art in multilingual text representation learning. While the paper could benefit from additional analysis of the resources' limitations and comparisons to other approaches, C-Pack is a promising step forward in supporting more robust and effective Chinese natural language processing applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
0
C-Pack: Packaged Resources To Advance General Chinese Embedding
Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighoff, Defu Lian, Jian-Yun Nie
We introduce C-Pack, a package of resources that significantly advance the field of general Chinese embeddings. C-Pack includes three critical resources. 1) C-MTEB is a comprehensive benchmark for Chinese text embeddings covering 6 tasks and 35 datasets. 2) C-MTP is a massive text embedding dataset curated from labeled and unlabeled Chinese corpora for training embedding models. 3) C-TEM is a family of embedding models covering multiple sizes. Our models outperform all prior Chinese text embeddings on C-MTEB by up to +10% upon the time of the release. We also integrate and optimize the entire suite of training methods for C-TEM. Along with our resources on general Chinese embedding, we release our data and models for English text embeddings. The English models achieve state-of-the-art performance on MTEB benchmark; meanwhile, our released English data is 2 times larger than the Chinese data. All these resources are made publicly available at https://github.com/FlagOpen/FlagEmbedding.
Read more5/14/2024

0
Recent advances in text embedding: A Comprehensive Review of Top-Performing Methods on the MTEB Benchmark
Hongliu Cao
Text embedding methods have become increasingly popular in both industrial and academic fields due to their critical role in a variety of natural language processing tasks. The significance of universal text embeddings has been further highlighted with the rise of Large Language Models (LLMs) applications such as Retrieval-Augmented Systems (RAGs). While previous models have attempted to be general-purpose, they often struggle to generalize across tasks and domains. However, recent advancements in training data quantity, quality and diversity; synthetic data generation from LLMs as well as using LLMs as backbones encourage great improvements in pursuing universal text embeddings. In this paper, we provide an overview of the recent advances in universal text embedding models with a focus on the top performing text embeddings on Massive Text Embedding Benchmark (MTEB). Through detailed comparison and analysis, we highlight the key contributions and limitations in this area, and propose potentially inspiring future research directions.
Read more6/21/2024
0
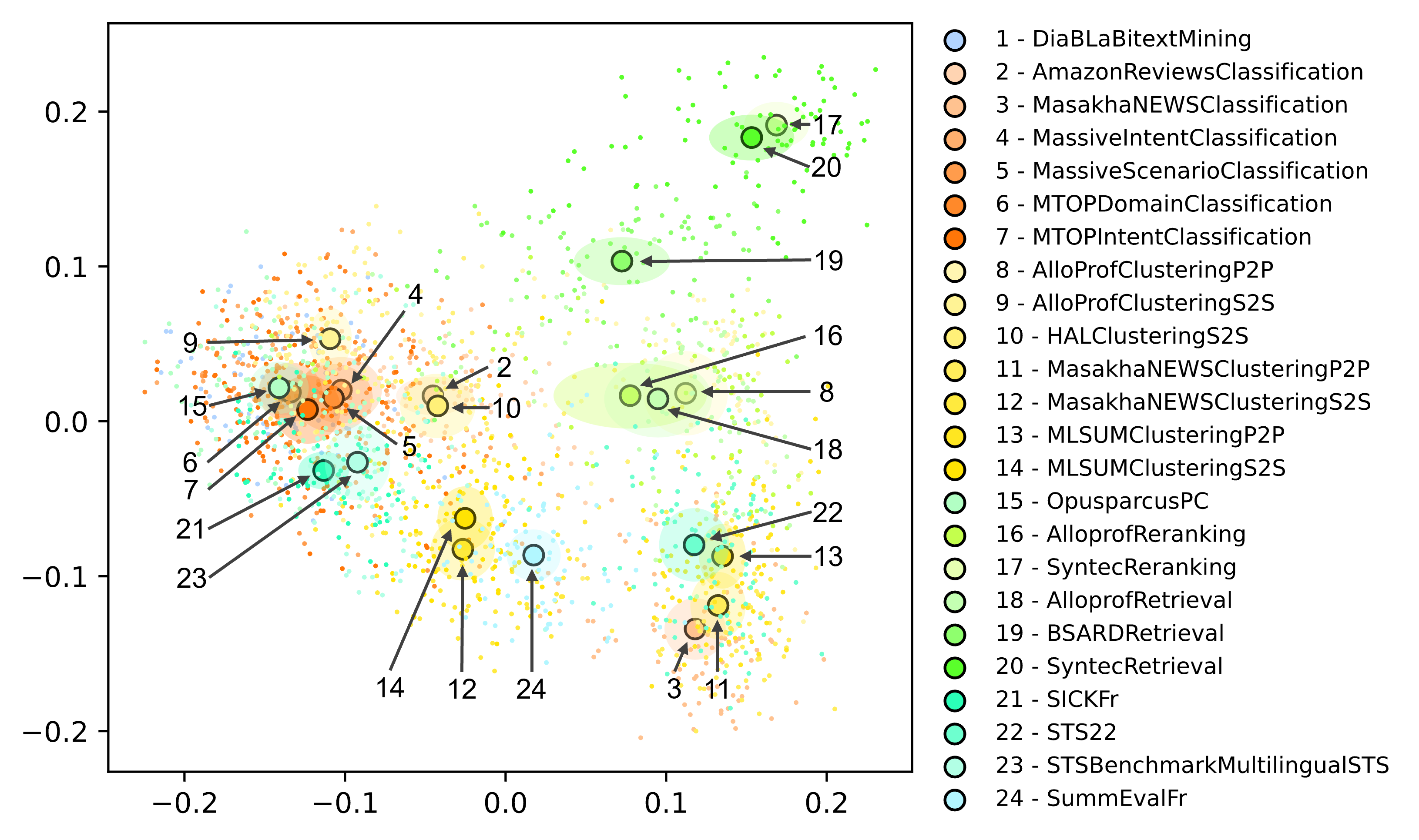
Extending the Massive Text Embedding Benchmark to French
Mathieu Ciancone, Imene Kerboua, Marion Schaeffer, Wissam Siblini
Recently, numerous embedding models have been made available and widely used for various NLP tasks. The Massive Text Embedding Benchmark (MTEB) has primarily simplified the process of choosing a model that performs well for several tasks in English, but extensions to other languages remain challenging. This is why we expand MTEB to propose the first massive benchmark of sentence embeddings for French. We gather 15 existing datasets in an easy-to-use interface and create three new French datasets for a global evaluation of 8 task categories. We compare 51 carefully selected embedding models on a large scale, conduct comprehensive statistical tests, and analyze the correlation between model performance and many of their characteristics. We find out that even if no model is the best on all tasks, large multilingual models pre-trained on sentence similarity perform exceptionally well. Our work comes with open-source code, new datasets and a public leaderboard.
Read more6/18/2024
0
Chinese Tiny LLM: Pretraining a Chinese-Centric Large Language Model
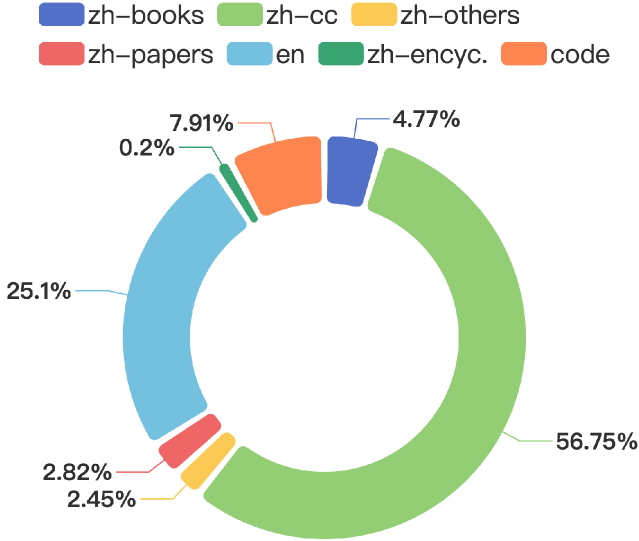
Xinrun Du, Zhouliang Yu, Songyang Gao, Ding Pan, Yuyang Cheng, Ziyang Ma, Ruibin Yuan, Xingwei Qu, Jiaheng Liu, Tianyu Zheng, Xinchen Luo, Guorui Zhou, Wenhu Chen, Ge Zhang
In this study, we introduce CT-LLM, a 2B large language model (LLM) that illustrates a pivotal shift towards prioritizing the Chinese language in developing LLMs. Uniquely initiated from scratch, CT-LLM diverges from the conventional methodology by primarily incorporating Chinese textual data, utilizing an extensive corpus of 1,200 billion tokens, including 800 billion Chinese tokens, 300 billion English tokens, and 100 billion code tokens. This strategic composition facilitates the model's exceptional proficiency in understanding and processing Chinese, a capability further enhanced through alignment techniques. Demonstrating remarkable performance on the CHC-Bench, CT-LLM excels in Chinese language tasks, and showcases its adeptness in English through SFT. This research challenges the prevailing paradigm of training LLMs predominantly on English corpora and then adapting them to other languages, broadening the horizons for LLM training methodologies. By open-sourcing the full process of training a Chinese LLM, including a detailed data processing procedure with the obtained Massive Appropriate Pretraining Chinese Corpus (MAP-CC), a well-chosen multidisciplinary Chinese Hard Case Benchmark (CHC-Bench), and the 2B-size Chinese Tiny LLM (CT-LLM), we aim to foster further exploration and innovation in both academia and industry, paving the way for more inclusive and versatile language models.
Read more9/16/2024