Approximate Dec-POMDP Solving Using Multi-Agent A*
2405.05662
0
0
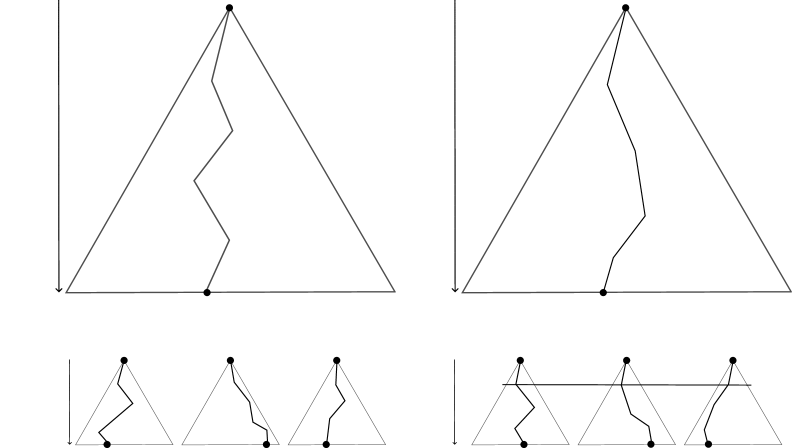
Abstract
We present an A*-based algorithm to compute policies for finite-horizon Dec-POMDPs. Our goal is to sacrifice optimality in favor of scalability for larger horizons. The main ingredients of our approach are (1) using clustered sliding window memory, (2) pruning the A* search tree, and (3) using novel A* heuristics. Our experiments show competitive performance to the state-of-the-art. Moreover, for multiple benchmarks, we achieve superior performance. In addition, we provide an A* algorithm that finds upper bounds for the optimum, tailored towards problems with long horizons. The main ingredient is a new heuristic that periodically reveals the state, thereby limiting the number of reachable beliefs. Our experiments demonstrate the efficacy and scalability of the approach.
Create account to get full access
Overview
- Presents a novel approach called "Small-step MAA*" for approximately solving Decentralized Partially Observable Markov Decision Processes (Dec-POMDPs)
- Leverages a multi-agent version of the A* search algorithm to efficiently explore the joint policy space
- Introduces lower bounds and heuristics to guide the search and provide performance guarantees
Plain English Explanation
The paper tackles the challenge of Decentralized Partially Observable Markov Decision Processes (Dec-POMDPs), which are used to model decision-making problems involving multiple agents with incomplete information about their environment. Solving Dec-POMDP problems optimally is computationally intractable, so the authors propose an approximate solution method called "Small-step MAA*".
The key idea behind Small-step MAA* is to use a multi-agent version of the A* search algorithm to efficiently explore the space of possible joint policies for the agents. A* is a well-known path-finding algorithm that uses heuristics to guide the search towards promising solutions. By adapting A* to the multi-agent setting, the authors can quickly identify good approximate solutions without having to exhaustively search the entire policy space.
To make the search more effective, the authors also introduce novel lower bounds and heuristics that provide performance guarantees for the solutions found. These techniques help prune the search space and focus the algorithm on the most promising areas, leading to significant efficiency gains compared to previous approaches.
Technical Explanation
The paper presents a novel algorithm called "Small-step MAA*" for approximately solving Decentralized Partially Observable Markov Decision Processes (Dec-POMDPs). Dec-POMDPs are a type of multi-agent decision-making problem where each agent has only partial information about the environment and must coordinate with other agents to achieve a common goal.
Small-step MAA* is based on a multi-agent extension of the A* search algorithm, which is a well-known path-finding algorithm that uses heuristics to guide the search towards promising solutions. In the context of Dec-POMDPs, the authors adapt A* to explore the joint policy space for the agents, rather than just a single path.
To make the search more effective, the authors introduce several key innovations:
-
Lower Bounds: The paper proposes novel lower bounds on the optimal value function that can be computed efficiently. These lower bounds help prune the search space by identifying suboptimal joint policies early on.
-
Heuristics: The authors develop heuristic functions that provide admissible estimates of the optimal value, further guiding the search towards high-quality solutions.
-
Small-step Exploration: Instead of considering full joint policies at each step, Small-step MAA* explores the policy space in a more granular fashion, considering small incremental changes to the agents' individual policies. This allows for more efficient exploration of the joint policy space.
The paper demonstrates the effectiveness of Small-step MAA* through extensive experiments on a variety of Dec-POMDP benchmark problems. The results show that the algorithm can find high-quality approximate solutions much more efficiently than previous state-of-the-art methods.
Critical Analysis
The paper presents a compelling approach to solving Dec-POMDP problems, which are known to be computationally challenging. The authors' key innovations, such as the lower bounds and heuristics, are well-motivated and appear to be effective in practice.
One potential limitation of the work is that it still relies on a search-based approach, which may not scale well to very large or complex problems. The authors acknowledge this and suggest that incorporating machine learning techniques could be a fruitful avenue for future research to further improve the scalability of the approach.
Additionally, the paper does not explore the potential limitations or failure modes of the Small-step MAA* algorithm. It would be valuable to understand the types of problems or scenarios where the algorithm may struggle to find good approximate solutions, and how robust it is to different problem characteristics or assumptions.
Overall, the paper makes a significant contribution to the field of multi-agent decision-making and provides a solid foundation for further research in this area. The authors' other work on plan-based reasoning and policy optimization suggests that they are well-equipped to continue advancing the state of the art in this domain.
Conclusion
The paper presents a novel algorithm called "Small-step MAA*" for approximately solving Decentralized Partially Observable Markov Decision Processes (Dec-POMDPs), a challenging class of multi-agent decision-making problems. The key innovations include the use of a multi-agent version of the A* search algorithm, as well as the introduction of novel lower bounds and heuristics to guide the search and provide performance guarantees.
The authors demonstrate the effectiveness of their approach through extensive experiments, showing that Small-step MAA* can find high-quality approximate solutions much more efficiently than previous state-of-the-art methods. While the paper acknowledges potential limitations in terms of scalability, it lays the groundwork for further research in this important area of multi-agent decision-making, with promising implications for a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
Solving Collaborative Dec-POMDPs with Deep Reinforcement Learning Heuristics
Nitsan Soffair
0
0
WQMIX, QMIX, QTRAN, and VDN are SOTA algorithms for Dec-POMDP. All of them cannot solve complex agents' cooperation domains. We give an algorithm to solve such problems. In the first stage, we solve a single-agent problem and get a policy. In the second stage, we solve the multi-agent problem with the single-agent policy. SA2MA has a clear advantage over all competitors in complex agents' cooperative domains.
6/4/2024
🛠️
Optimizing Agent Collaboration through Heuristic Multi-Agent Planning
Nitsan Soffair
0
0
The SOTA algorithms for addressing QDec-POMDP issues, QDec-FP and QDec-FPS, are unable to effectively tackle problems that involve different types of sensing agents. We propose a new algorithm that addresses this issue by requiring agents to adopt the same plan if one agent is unable to take a sensing action but the other can. Our algorithm performs significantly better than both QDec-FP and QDec-FPS in these types of situations.
6/4/2024
🌿
Learning Explainable and Better Performing Representations of POMDP Strategies
Alexander Bork, Debraj Chakraborty, Kush Grover, Jan Kretinsky, Stefanie Mohr
0
0
Strategies for partially observable Markov decision processes (POMDP) typically require memory. One way to represent this memory is via automata. We present a method to learn an automaton representation of a strategy using a modification of the L*-algorithm. Compared to the tabular representation of a strategy, the resulting automaton is dramatically smaller and thus also more explainable. Moreover, in the learning process, our heuristics may even improve the strategy's performance. In contrast to approaches that synthesize an automaton directly from the POMDP thereby solving it, our approach is incomparably more scalable.
5/22/2024
Measurement Simplification in rho-POMDP with Performance Guarantees
Tom Yotam, Vadim Indelman
0
0
Decision making under uncertainty is at the heart of any autonomous system acting with imperfect information. The cost of solving the decision making problem is exponential in the action and observation spaces, thus rendering it unfeasible for many online systems. This paper introduces a novel approach to efficient decision-making, by partitioning the high-dimensional observation space. Using the partitioned observation space, we formulate analytical bounds on the expected information-theoretic reward, for general belief distributions. These bounds are then used to plan efficiently while keeping performance guarantees. We show that the bounds are adaptive, computationally efficient, and that they converge to the original solution. We extend the partitioning paradigm and present a hierarchy of partitioned spaces that allows greater efficiency in planning. We then propose a specific variant of these bounds for Gaussian beliefs and show a theoretical performance improvement of at least a factor of 4. Finally, we compare our novel method to other state of the art algorithms in active SLAM scenarios, in simulation and in real experiments. In both cases we show a significant speed-up in planning with performance guarantees.
6/18/2024