Aquatic Navigation: A Challenging Benchmark for Deep Reinforcement Learning
2405.20534
0
0

Abstract
An exciting and promising frontier for Deep Reinforcement Learning (DRL) is its application to real-world robotic systems. While modern DRL approaches achieved remarkable successes in many robotic scenarios (including mobile robotics, surgical assistance, and autonomous driving) unpredictable and non-stationary environments can pose critical challenges to such methods. These features can significantly undermine fundamental requirements for a successful training process, such as the Markovian properties of the transition model. To address this challenge, we propose a new benchmarking environment for aquatic navigation using recent advances in the integration between game engines and DRL. In more detail, we show that our benchmarking environment is problematic even for state-of-the-art DRL approaches that may struggle to generate reliable policies in terms of generalization power and safety. Specifically, we focus on PPO, one of the most widely accepted algorithms, and we propose advanced training techniques (such as curriculum learning and learnable hyperparameters). Our extensive empirical evaluation shows that a well-designed combination of these ingredients can achieve promising results. Our simulation environment and training baselines are freely available to facilitate further research on this open problem and encourage collaboration in the field.
Create account to get full access
Overview
- This paper introduces a new benchmark for evaluating deep reinforcement learning algorithms in the context of aquatic navigation.
- The benchmark simulates a marine environment with complex hydrodynamics, including currents and vortices, which pose significant challenges for autonomous navigation.
- The authors evaluate the performance of various reinforcement learning algorithms on this benchmark and provide insights into the strengths and weaknesses of different approaches.
Plain English Explanation
This research paper proposes a new testing environment for evaluating the capabilities of deep reinforcement learning algorithms in navigating complex underwater environments. The simulated scenario mimics the challenges faced by autonomous underwater vehicles, such as dealing with strong currents and swirling vortices in the water. The researchers assess the performance of several reinforcement learning techniques in this challenging benchmark, providing insights into the strengths and limitations of each approach. The goal is to advance the field of underwater robotics by creating a standardized testing ground that can help developers improve their algorithms and overcome the unique obstacles encountered in aquatic environments.
Technical Explanation
The paper introduces a new benchmark for evaluating deep reinforcement learning algorithms in the context of aquatic navigation. The benchmark simulates a marine environment with complex hydrodynamics, including currents and vortices, which pose significant challenges for autonomous navigation. The authors evaluate the performance of various reinforcement learning algorithms, including deep reinforcement learning-enhanced PPO and multi-robot cooperative socially aware navigation, on this benchmark and provide insights into the strengths and weaknesses of different approaches. The benchmark is designed to serve as a standardized testing ground for the development of robust underwater navigation systems.
Critical Analysis
The paper presents a compelling benchmark for evaluating deep reinforcement learning algorithms in the context of aquatic navigation, which is an important and underexplored area of research. The simulated environment captures the complex hydrodynamics and challenges faced by autonomous underwater vehicles, providing a realistic testing ground for assessing the capabilities of different reinforcement learning approaches.
However, the paper does not address the potential limitations of the benchmark, such as the accuracy of the simulated hydrodynamics or the extensibility of the benchmark to real-world environments. Additionally, the authors could have provided more details on the specific reinforcement learning algorithms evaluated and their comparative performance, which would have allowed for a more thorough understanding of the strengths and weaknesses of each approach.
Further research is needed to validate the benchmark's relevance and utility for the development of practical underwater navigation systems. Integrating the benchmark with physical experiments or real-world data could help to bridge the gap between simulation and reality, and provide a more comprehensive evaluation of the reinforcement learning algorithms.
Conclusion
This paper introduces a new benchmark for evaluating deep reinforcement learning algorithms in the context of aquatic navigation, which is a critical and challenging domain for autonomous systems. The simulated environment captures the complex hydrodynamics and obstacles encountered in underwater environments, providing a standardized testing ground for the development of robust navigation algorithms. The insights gained from this research can help to advance the field of underwater robotics and enhance the capabilities of autonomous vehicles operating in complex aquatic environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
Quantum Deep Reinforcement Learning for Robot Navigation Tasks
Hans Hohenfeld, Dirk Heimann, Felix Wiebe, Frank Kirchner
0
0
We utilize hybrid quantum deep reinforcement learning to learn navigation tasks for a simple, wheeled robot in simulated environments of increasing complexity. For this, we train parameterized quantum circuits (PQCs) with two different encoding strategies in a hybrid quantum-classical setup as well as a classical neural network baseline with the double deep Q network (DDQN) reinforcement learning algorithm. Quantum deep reinforcement learning (QDRL) has previously been studied in several relatively simple benchmark environments, mainly from the OpenAI gym suite. However, scaling behavior and applicability of QDRL to more demanding tasks closer to real-world problems e. g., from the robotics domain, have not been studied previously. Here, we show that quantum circuits in hybrid quantum-classic reinforcement learning setups are capable of learning optimal policies in multiple robotic navigation scenarios with notably fewer trainable parameters compared to a classical baseline. Across a large number of experimental configurations, we find that the employed quantum circuits outperform the classical neural network baselines when equating for the number of trainable parameters. Yet, the classical neural network consistently showed better results concerning training times and stability, with at least one order of magnitude of trainable parameters more than the best-performing quantum circuits. However, validating the robustness of the learning methods in a large and dynamic environment, we find that the classical baseline produces more stable and better performing policies overall.
6/26/2024
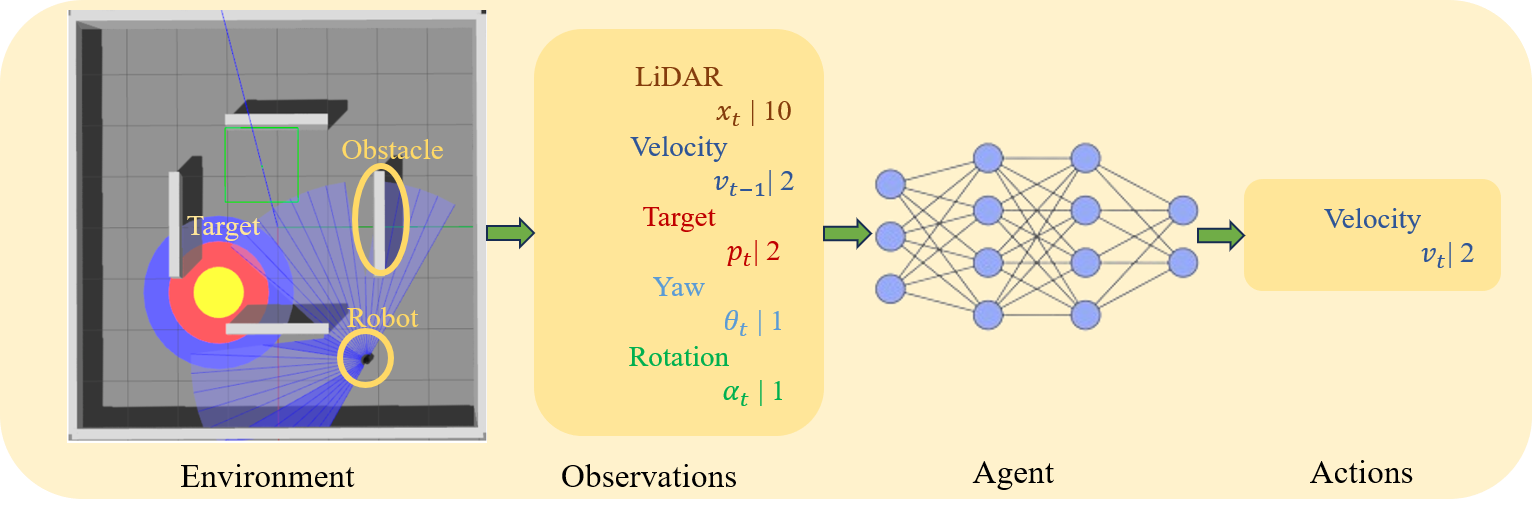
Deep Reinforcement Learning with Enhanced PPO for Safe Mobile Robot Navigation
Hamid Taheri, Seyed Rasoul Hosseini
0
0
Collision-free motion is essential for mobile robots. Most approaches to collision-free and efficient navigation with wheeled robots require parameter tuning by experts to obtain good navigation behavior. This study investigates the application of deep reinforcement learning to train a mobile robot for autonomous navigation in a complex environment. The robot utilizes LiDAR sensor data and a deep neural network to generate control signals guiding it toward a specified target while avoiding obstacles. We employ two reinforcement learning algorithms in the Gazebo simulation environment: Deep Deterministic Policy Gradient and proximal policy optimization. The study introduces an enhanced neural network structure in the Proximal Policy Optimization algorithm to boost performance, accompanied by a well-designed reward function to improve algorithm efficacy. Experimental results conducted in both obstacle and obstacle-free environments underscore the effectiveness of the proposed approach. This research significantly contributes to the advancement of autonomous robotics in complex environments through the application of deep reinforcement learning.
5/28/2024
Object Manipulation in Marine Environments using Reinforcement Learning
Ahmed Nader, Muhayy Ud Din, Mughni Irfan, Irfan Hussain
0
0
Performing intervention tasks in the maritime domain is crucial for safety and operational efficiency. The unpredictable and dynamic marine environment makes the intervention tasks such as object manipulation extremely challenging. This study proposes a robust solution for object manipulation from a dock in the presence of disturbances caused by sea waves. To tackle this challenging problem, we apply a deep reinforcement learning (DRL) based algorithm called Soft. Actor-Critic (SAC). SAC employs an actor-critic framework; the actors learn a policy that minimizes an objective function while the critic evaluates the learned policy and provides feedback to guide the actor-learning process. We trained the agent using the PyBullet dynamic simulator and tested it in a realistic simulation environment called MBZIRC maritime simulator. This simulator allows the simulation of different wave conditions according to the World Meteorological Organization (WMO) sea state code. Simulation results demonstrate a high success rate in retrieving the objects from the dock. The trained agent achieved an 80 percent success rate when applied in the simulation environment in the presence of waves characterized by sea state 2, according to the WMO sea state code
6/6/2024
Efficient Navigation of a Robotic Fish Swimming Across the Vortical Flow Field
Haodong Feng, Dehan Yuan, Jiale Miao, Jie You, Yue Wang, Yi Zhu, Dixia Fan
0
0
Navigating efficiently across vortical flow fields presents a significant challenge in various robotic applications. The dynamic and unsteady nature of vortical flows often disturbs the control of underwater robots, complicating their operation in hydrodynamic environments. Conventional control methods, which depend on accurate modeling, fail in these settings due to the complexity of fluid-structure interactions (FSI) caused by unsteady hydrodynamics. This study proposes a deep reinforcement learning (DRL) algorithm, trained in a data-driven manner, to enable efficient navigation of a robotic fish swimming across vortical flows. Our proposed algorithm incorporates the LSTM architecture and uses several recent consecutive observations as the state to address the issue of partial observation, often due to sensor limitations. We present a numerical study of navigation within a Karman vortex street, created by placing a stationary cylinder in a uniform flow, utilizing the immersed boundary-lattice Boltzmann method (IB-LBM). The aim is to train the robotic fish to discover efficient navigation policies, enabling it to reach a designated target point across the Karman vortex street from various initial positions. After training, the fish demonstrates the ability to rapidly reach the target from different initial positions, showcasing the effectiveness and robustness of our proposed algorithm. Analysis of the results reveals that the robotic fish can leverage velocity gains and pressure differences induced by the vortices to reach the target, underscoring the potential of our proposed algorithm in enhancing navigation in complex hydrodynamic environments.
5/24/2024