Are AI-Generated Text Detectors Robust to Adversarial Perturbations?

0

Sign in to get full access
Overview
- This paper examines the robustness of AI-generated text detectors to adversarial attacks, which are small, imperceptible modifications to the input that can fool the detector.
- The researchers evaluate several state-of-the-art text detection models against different adversarial attack techniques and find that the models are vulnerable to such attacks.
- The paper provides insights into the limitations of current AI-generated text detection systems and suggests areas for improvement to make them more robust.
Plain English Explanation
In this paper, the researchers look at how well the AI systems that are designed to detect if text was generated by a machine (rather than a human) hold up against attempts to trick them. They take some of the best-performing AI text detection models and try out different techniques to make small, hard-to-notice changes to the text that can fool the models into wrongly thinking the text was written by a person.
The researchers find that these AI text detectors are actually quite vulnerable to these kinds of adversarial attacks. Even small, subtle changes to the text can cause the detectors to completely miss that the text was actually generated by a machine. This reveals some important limitations in the current state of AI-generated text detection technology.
The paper provides useful insights into how we can improve these AI systems to make them more robust and resistant to being tricked. As AI-generated content becomes more prevalent, having reliable and secure text detection will be crucial. This research highlights some of the challenges that need to be addressed to get us there.
Technical Explanation
The paper evaluates the robustness of several state-of-the-art AI-generated text detection models, including MAGE, RAIDaR, and Efficient Detection, against different adversarial attack techniques.
The researchers apply several types of adversarial attacks, including gradient-based attacks and black-box attacks, to the text detection models. They find that even small, imperceptible perturbations to the input text can significantly degrade the performance of these models, causing them to incorrectly classify machine-generated text as human-written.
The paper provides a detailed analysis of the vulnerabilities of these text detection models, including an examination of how the models' performance degrades as the strength of the adversarial attacks is increased. The researchers also investigate the transferability of adversarial examples across different text detection models, finding that adversarial examples generated for one model can often fool other models as well.
Additionally, the paper explores potential strategies to enhance the noise robustness of text retrieval models, which could be leveraged to improve the resilience of AI-generated text detection systems.
Critical Analysis
The paper provides valuable insights into the current limitations of AI-generated text detection models, which is an important area of research as the use of generative AI models becomes more widespread. The researchers' findings suggest that these models are still vulnerable to adversarial attacks, which could undermine their effectiveness in real-world applications.
One potential limitation of the study is that it only evaluates a select set of text detection models, and the results may not necessarily generalize to other models or architectures. Additionally, the paper does not explore potential mitigation strategies in depth, beyond briefly mentioning the possibility of enhancing the noise robustness of text retrieval models.
Further research could investigate more comprehensive defense mechanisms, such as adversarial training or other techniques, to improve the resilience of AI-generated text detection systems. It would also be valuable to explore the generalization of these findings across a wider range of text detection models and adversarial attack scenarios.
Conclusion
This paper highlights the vulnerability of state-of-the-art AI-generated text detection models to adversarial attacks, which can significantly degrade their performance. The findings suggest that current text detection systems may not be sufficiently robust for real-world applications where adversarial attacks could be a concern.
The insights from this research underscore the need for continued advancements in the field of AI-generated text detection, focusing on developing more resilient models that can withstand adversarial perturbations. As the use of generative AI models becomes more prevalent, ensuring the reliability and security of text detection systems will be crucial for maintaining trust and integrity in the digital landscape.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Are AI-Generated Text Detectors Robust to Adversarial Perturbations?
Guanhua Huang, Yuchen Zhang, Zhe Li, Yongjian You, Mingze Wang, Zhouwang Yang
The widespread use of large language models (LLMs) has sparked concerns about the potential misuse of AI-generated text, as these models can produce content that closely resembles human-generated text. Current detectors for AI-generated text (AIGT) lack robustness against adversarial perturbations, with even minor changes in characters or words causing a reversal in distinguishing between human-created and AI-generated text. This paper investigates the robustness of existing AIGT detection methods and introduces a novel detector, the Siamese Calibrated Reconstruction Network (SCRN). The SCRN employs a reconstruction network to add and remove noise from text, extracting a semantic representation that is robust to local perturbations. We also propose a siamese calibration technique to train the model to make equally confidence predictions under different noise, which improves the model's robustness against adversarial perturbations. Experiments on four publicly available datasets show that the SCRN outperforms all baseline methods, achieving 6.5%-18.25% absolute accuracy improvement over the best baseline method under adversarial attacks. Moreover, it exhibits superior generalizability in cross-domain, cross-genre, and mixed-source scenarios. The code is available at url{https://github.com/CarlanLark/Robust-AIGC-Detector}.
Read more6/27/2024

0
Navigating the Shadows: Unveiling Effective Disturbances for Modern AI Content Detectors
Ying Zhou, Ben He, Le Sun
With the launch of ChatGPT, large language models (LLMs) have attracted global attention. In the realm of article writing, LLMs have witnessed extensive utilization, giving rise to concerns related to intellectual property protection, personal privacy, and academic integrity. In response, AI-text detection has emerged to distinguish between human and machine-generated content. However, recent research indicates that these detection systems often lack robustness and struggle to effectively differentiate perturbed texts. Currently, there is a lack of systematic evaluations regarding detection performance in real-world applications, and a comprehensive examination of perturbation techniques and detector robustness is also absent. To bridge this gap, our work simulates real-world scenarios in both informal and professional writing, exploring the out-of-the-box performance of current detectors. Additionally, we have constructed 12 black-box text perturbation methods to assess the robustness of current detection models across various perturbation granularities. Furthermore, through adversarial learning experiments, we investigate the impact of perturbation data augmentation on the robustness of AI-text detectors. We have released our code and data at https://github.com/zhouying20/ai-text-detector-evaluation.
Read more6/14/2024
0
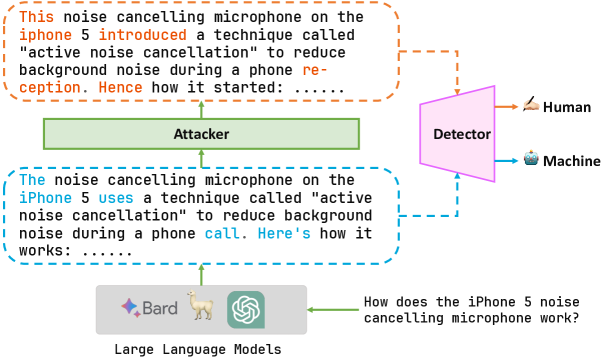
Humanizing Machine-Generated Content: Evading AI-Text Detection through Adversarial Attack
Ying Zhou, Ben He, Le Sun
With the development of large language models (LLMs), detecting whether text is generated by a machine becomes increasingly challenging in the face of malicious use cases like the spread of false information, protection of intellectual property, and prevention of academic plagiarism. While well-trained text detectors have demonstrated promising performance on unseen test data, recent research suggests that these detectors have vulnerabilities when dealing with adversarial attacks such as paraphrasing. In this paper, we propose a framework for a broader class of adversarial attacks, designed to perform minor perturbations in machine-generated content to evade detection. We consider two attack settings: white-box and black-box, and employ adversarial learning in dynamic scenarios to assess the potential enhancement of the current detection model's robustness against such attacks. The empirical results reveal that the current detection models can be compromised in as little as 10 seconds, leading to the misclassification of machine-generated text as human-written content. Furthermore, we explore the prospect of improving the model's robustness over iterative adversarial learning. Although some improvements in model robustness are observed, practical applications still face significant challenges. These findings shed light on the future development of AI-text detectors, emphasizing the need for more accurate and robust detection methods.
Read more4/3/2024
0
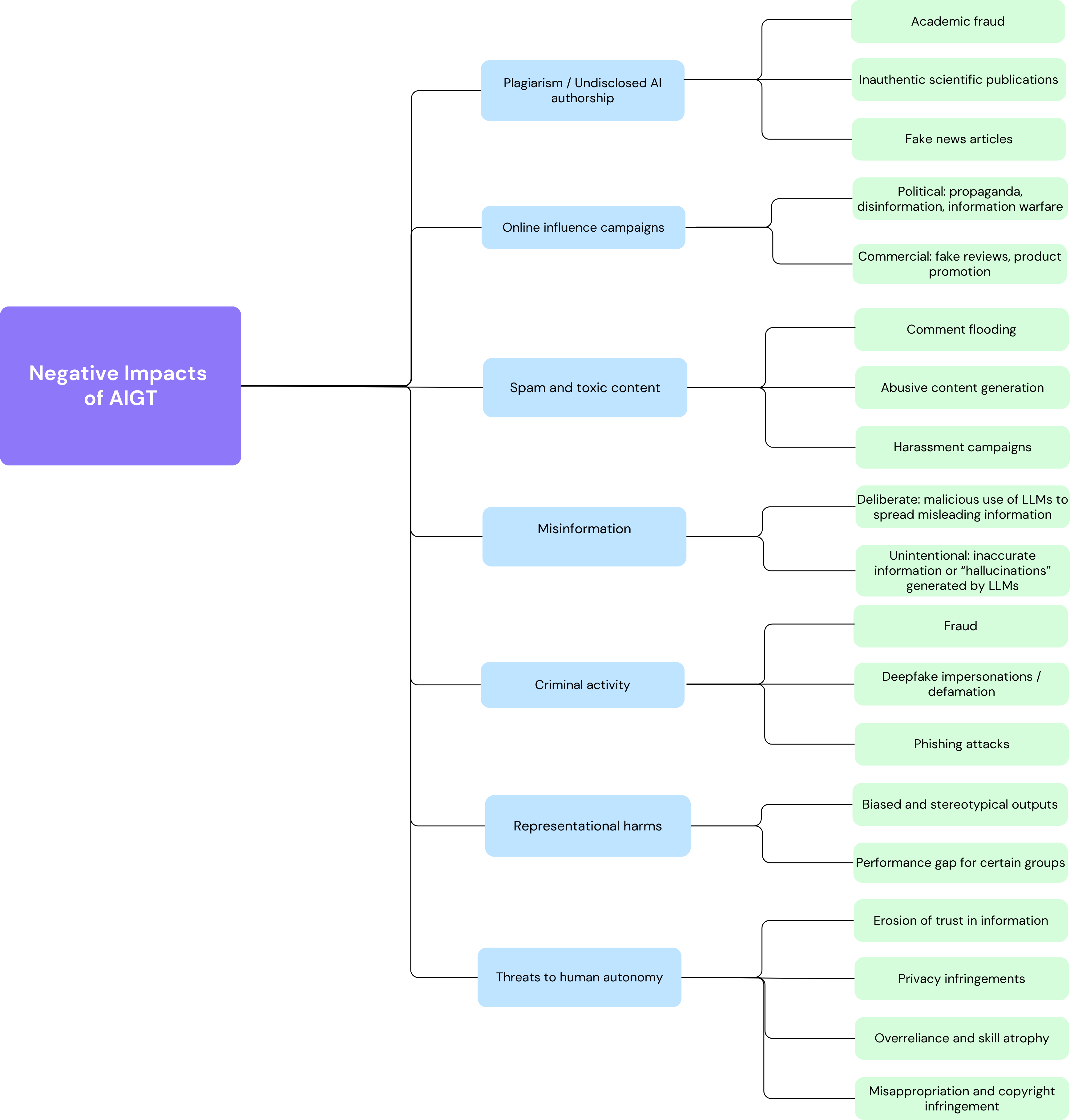
Detecting AI-Generated Text: Factors Influencing Detectability with Current Methods
Kathleen C. Fraser, Hillary Dawkins, Svetlana Kiritchenko
Large language models (LLMs) have advanced to a point that even humans have difficulty discerning whether a text was generated by another human, or by a computer. However, knowing whether a text was produced by human or artificial intelligence (AI) is important to determining its trustworthiness, and has applications in many domains including detecting fraud and academic dishonesty, as well as combating the spread of misinformation and political propaganda. The task of AI-generated text (AIGT) detection is therefore both very challenging, and highly critical. In this survey, we summarize state-of-the art approaches to AIGT detection, including watermarking, statistical and stylistic analysis, and machine learning classification. We also provide information about existing datasets for this task. Synthesizing the research findings, we aim to provide insight into the salient factors that combine to determine how detectable AIGT text is under different scenarios, and to make practical recommendations for future work towards this significant technical and societal challenge.
Read more6/26/2024