Ask Again, Then Fail: Large Language Models' Vacillations in Judgment

0

Sign in to get full access
Overview
- The paper explores how large language models (LLMs) struggle to maintain consistent judgments when asked to re-evaluate their initial responses.
- It introduces a "follow-up questioning mechanism" to test LLMs' ability to justify and update their judgments.
- The findings highlight the overconfidence and instability of LLMs' decision-making, raising concerns about their reliability in high-stakes applications.
Plain English Explanation
The paper investigates a curious phenomenon observed in large language models (LLMs) - their tendency to change their minds when asked to re-evaluate their initial responses. LLMs are AI systems trained on vast amounts of text data, allowing them to generate human-like responses. However, this research suggests that LLMs may not always be as confident or consistent in their judgments as one might expect.
To explore this issue, the researchers developed a "follow-up questioning mechanism." This involves asking the LLM a question, then immediately following up with a request to re-evaluate or justify its previous response. The findings reveal that LLMs often struggle to maintain their original stance, frequently changing or even contradicting their initial judgments.
This inconsistency highlights a concerning trend - LLMs can be overconfident in their initial responses, yet ultimately fail to provide reliable or coherent justifications when pressed further. This raises important questions about the trustworthiness of LLMs, especially in high-stakes applications where their decisions could have significant real-world consequences.
The paper's findings underscore the need for continued research and development to improve the stability and transparency of LLM decision-making. As these AI systems become more prevalent in various domains, it's crucial to ensure they can provide consistently sound and justifiable judgments that humans can rely on.
Technical Explanation
The paper introduces a "follow-up questioning mechanism" to assess the stability and consistency of large language models' (LLMs') decision-making. This mechanism involves presenting an LLM with a prompt, then immediately following up with a request for the model to re-evaluate or justify its previous response.
The researchers designed a diverse set of prompts covering topics such as ethics, reasoning, and common sense. These prompts were carefully crafted to elicit judgments from the LLMs that could then be scrutinized through the follow-up questioning.
The experiments were conducted using several prominent LLMs, including GPT-3, InstructGPT, and PaLM. The findings reveal that these models often struggled to maintain their initial judgments when asked to re-evaluate or explain them. In many cases, the LLMs revised or even contradicted their previous responses, displaying a concerning level of overconfidence and inconsistency.
This instability in LLM decision-making highlights potential issues with their reliability and trustworthiness - particularly in high-stakes applications where predictable and justifiable outputs are crucial. The paper also discusses the implications of these findings for the development of more robust and transparent AI systems capable of providing consistently sound judgments.
Critical Analysis
The paper's findings raise important concerns about the limitations of current large language models (LLMs) and their ability to maintain stable and justifiable judgments. The researchers' use of the "follow-up questioning mechanism" provides a valuable approach for probing the underlying decision-making processes of these AI systems.
One key limitation acknowledged in the paper is the potential for bias in the prompt design and the selection of topics covered. While the researchers attempt to mitigate this by using a diverse set of prompts, the inherent biases in the training data and model architectures may still influence the LLMs' responses.
Additionally, the paper does not delve into the specific reasons why the LLMs struggle to maintain their initial judgments. Further research is needed to understand the underlying cognitive mechanisms and architectural limitations that contribute to this inconsistency. Exploring the role of verbalized uncertainty and predictive confidence may provide valuable insights.
Another area for further investigation is the potential impact of fine-tuning or prompt engineering on the stability and justification capabilities of LLMs. Examining whether specialized training or prompting techniques can improve the models' decision-making consistency would be a valuable addition to this line of research.
Overall, the paper highlights a crucial challenge facing the development of reliable and trustworthy AI systems. Addressing the instability and overconfidence observed in LLMs will be essential as these models become increasingly prevalent in real-world applications.
Conclusion
The paper's exploration of large language models' (LLMs') struggles to maintain consistent judgments when faced with follow-up questioning reveals significant limitations in the current state of these AI systems. The findings suggest that LLMs may be overconfident in their initial responses and lack the ability to provide stable, justifiable judgments when pressed for further explanation.
This instability raises concerns about the reliability and trustworthiness of LLMs, especially in high-stakes applications where predictable and accountable decision-making is critical. The paper's introduction of the "follow-up questioning mechanism" offers a valuable tool for probing the decision-making processes of these AI models, paving the way for further research and development efforts to address the identified challenges.
As large language models continue to advance and become more integrated into various domains, it will be essential to ensure their judgments are consistent, transparent, and align with human values and ethical principles. Ongoing work to improve the robustness and predictive uncertainty of these AI systems will be crucial for realizing their full potential and building trust in their capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Ask Again, Then Fail: Large Language Models' Vacillations in Judgment
Qiming Xie, Zengzhi Wang, Yi Feng, Rui Xia
We observe that current conversational language models often waver in their judgments when faced with follow-up questions, even if the original judgment was correct. This wavering presents a significant challenge for generating reliable responses and building user trust. To comprehensively assess this issue, we introduce a textsc{Follow-up Questioning Mechanism} along with two metrics to quantify this inconsistency, confirming its widespread presence in current language models. To mitigate this issue, we explore various prompting strategies for closed-source models; moreover, we develop a training-based framework textsc{Unwavering-FQ} that teaches language models to maintain their originally correct judgments through synthesized high-quality preference data. Our experimental results confirm the effectiveness of our framework and its ability to enhance the general capabilities of models.
Read more6/12/2024
💬
0
Follow-Up Questions Improve Documents Generated by Large Language Models
Bernadette J Tix
This study investigates the impact of Large Language Models (LLMs) generating follow-up questions in response to user requests for short (1-page) text documents. Users interacted with a novel web-based AI system designed to ask follow-up questions. Users requested documents they would like the AI to produce. The AI then generated follow-up questions to clarify the user's needs or offer additional insights before generating the requested documents. After answering the questions, users were shown a document generated using both the initial request and the questions and answers, and a document generated using only the initial request. Users indicated which document they preferred and gave feedback about their experience with the question-answering process. The findings of this study show clear benefits to question-asking both in document preference and in the qualitative user experience. This study further shows that users found more value in questions which were thought-provoking, open-ended, or offered unique insights into the user's request as opposed to simple information-gathering questions.
Read more8/16/2024

0
Relying on the Unreliable: The Impact of Language Models' Reluctance to Express Uncertainty
Kaitlyn Zhou, Jena D. Hwang, Xiang Ren, Maarten Sap
As natural language becomes the default interface for human-AI interaction, there is a need for LMs to appropriately communicate uncertainties in downstream applications. In this work, we investigate how LMs incorporate confidence in responses via natural language and how downstream users behave in response to LM-articulated uncertainties. We examine publicly deployed models and find that LMs are reluctant to express uncertainties when answering questions even when they produce incorrect responses. LMs can be explicitly prompted to express confidences, but tend to be overconfident, resulting in high error rates (an average of 47%) among confident responses. We test the risks of LM overconfidence by conducting human experiments and show that users rely heavily on LM generations, whether or not they are marked by certainty. Lastly, we investigate the preference-annotated datasets used in post training alignment and find that humans are biased against texts with uncertainty. Our work highlights new safety harms facing human-LM interactions and proposes design recommendations and mitigating strategies moving forward.
Read more7/11/2024
0
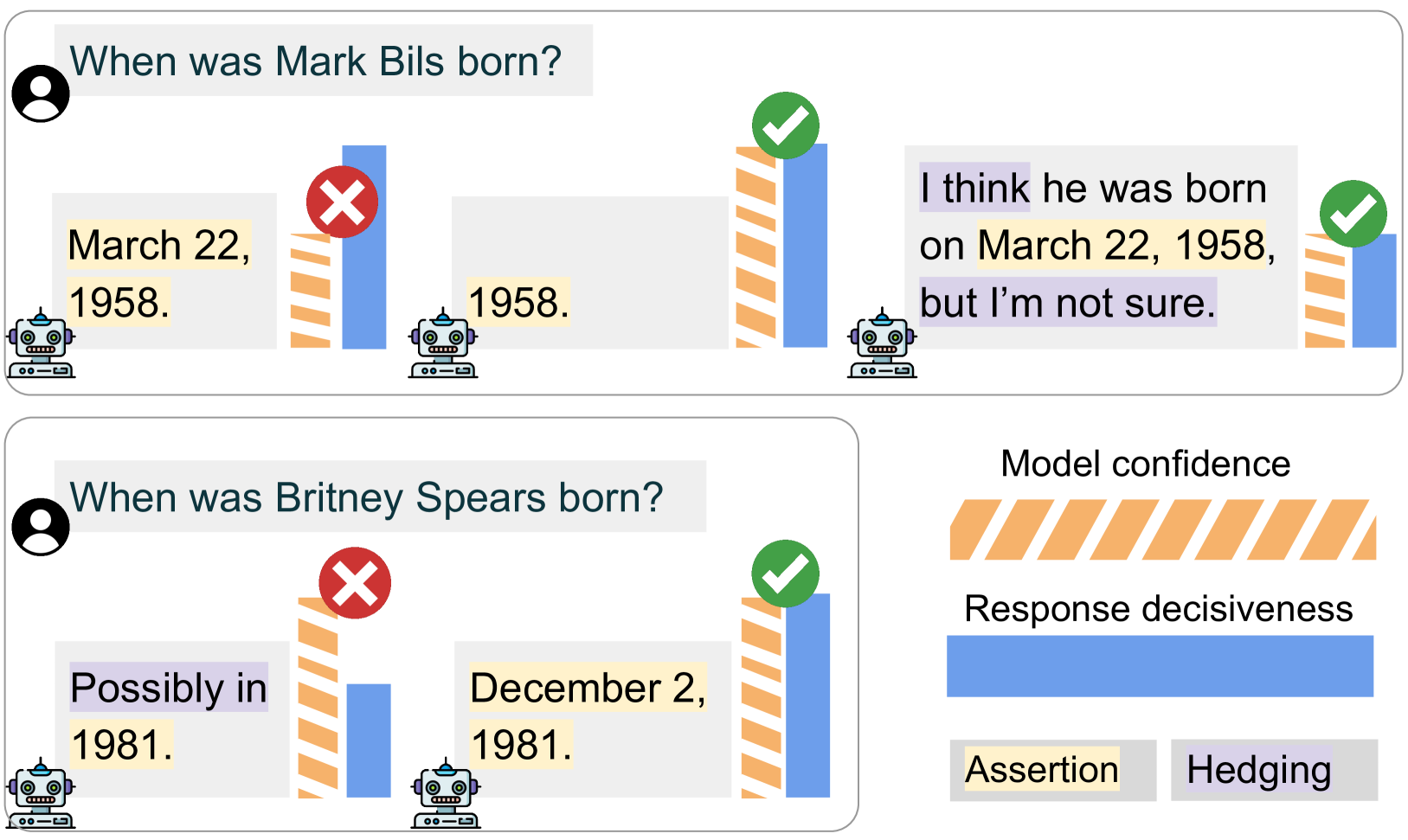
Can Large Language Models Faithfully Express Their Intrinsic Uncertainty in Words?
Gal Yona, Roee Aharoni, Mor Geva
We posit that large language models (LLMs) should be capable of expressing their intrinsic uncertainty in natural language. For example, if the LLM is equally likely to output two contradicting answers to the same question, then its generated response should reflect this uncertainty by hedging its answer (e.g., I'm not sure, but I think...). We formalize faithful response uncertainty based on the gap between the model's intrinsic confidence in the assertions it makes and the decisiveness by which they are conveyed. This example-level metric reliably indicates whether the model reflects its uncertainty, as it penalizes both excessive and insufficient hedging. We evaluate a variety of aligned LLMs at faithfully communicating uncertainty on several knowledge-intensive question answering tasks. Our results provide strong evidence that modern LLMs are poor at faithfully conveying their uncertainty, and that better alignment is necessary to improve their trustworthiness.
Read more5/28/2024