Associative Recurrent Memory Transformer

0

Sign in to get full access
Overview
- The paper introduces the Associative Recurrent Memory Transformer (ARMT), a novel neural network architecture that combines an associative memory module with a transformer-based language model.
- The ARMT is designed to improve the long-term memory retention and associative retrieval capabilities of language models, addressing key limitations of traditional transformer models.
- The paper evaluates the ARMT's performance on tasks that require associative recall and long-context memory, demonstrating its advantages over standard transformer architectures.
Plain English Explanation
The Associative Recurrent Memory Transformer (ARMT) is a new type of machine learning model that aims to improve the way language models remember and recall information. Traditional transformer models, while powerful in many ways, can struggle with tasks that require long-term memory or the ability to make associations between different pieces of information.
The ARMT addresses these limitations by combining a transformer-based language model with an additional component called an "associative memory module." This module acts like a supplementary memory bank, allowing the model to store and retrieve relevant information more effectively.
The paper shows that the ARMT outperforms standard transformer models on tasks that test its ability to remember and recall information over long time periods, as well as its capacity to make connections between different concepts. This suggests that the ARMT could be particularly useful for applications that require language understanding and reasoning, such as question-answering systems, dialogue agents, or continual learning systems.
Technical Explanation
The Associative Recurrent Memory Transformer (ARMT) builds upon the architecture of standard transformer models, which have achieved state-of-the-art performance on a wide range of natural language processing tasks. However, transformers can struggle with tasks that require long-term memory retention or the ability to make associations between disparate pieces of information.
To address these limitations, the ARMT incorporates an "associative memory module" that operates in parallel with the transformer's attention mechanism. This module uses a content-addressable memory system to store and retrieve relevant information from the model's past inputs and outputs. By combining this associative memory with the transformer's powerful language modeling capabilities, the ARMT is able to better remember and recall important details over long time periods, as well as make meaningful connections between related concepts.
The paper evaluates the ARMT's performance on a variety of tasks, including associative retrieval and long-context memory retention. The results demonstrate that the ARMT outperforms standard transformer models, particularly on tasks that require the model to integrate and reason about information from across a large context window.
Critical Analysis
The paper makes a compelling case for the ARMT's ability to address key limitations of transformer models, particularly in tasks that require long-term memory and associative reasoning. The inclusion of the associative memory module is a promising approach to enhancing the model's cognitive capabilities.
However, the paper does not explore the potential downsides or limitations of the ARMT architecture. For example, the additional complexity introduced by the associative memory module may come at the cost of increased computational requirements or training time, which could limit the model's practical applicability. Additionally, the paper does not discuss potential biases or ethical considerations that may arise from the ARMT's enhanced memory and reasoning abilities.
Further research is needed to fully understand the ARMT's performance in more diverse and challenging real-world scenarios, as well as to investigate potential trade-offs or unintended consequences of the proposed approach. Nonetheless, the ARMT represents an intriguing step forward in the ongoing effort to develop language models with more robust and flexible cognitive capabilities, as explored in the Extended Mind Transformers research.
Conclusion
The Associative Recurrent Memory Transformer (ARMT) introduces a novel approach to enhancing the memory and associative reasoning capabilities of transformer-based language models. By integrating an associative memory module with the transformer architecture, the ARMT demonstrates improved performance on tasks that require long-term memory retention and the ability to make connections between disparate pieces of information.
The ARMT's success in these areas suggests that it could be a valuable tool for a wide range of language-based applications, from question-answering systems to interactive dialogue agents. As the field of natural language processing continues to advance, the ARMT's unique blend of transformer-based language modeling and associative memory represents an important step towards developing more robust and cognitively-capable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Associative Recurrent Memory Transformer
Ivan Rodkin, Yuri Kuratov, Aydar Bulatov, Mikhail Burtsev
This paper addresses the challenge of creating a neural architecture for very long sequences that requires constant time for processing new information at each time step. Our approach, Associative Recurrent Memory Transformer (ARMT), is based on transformer self-attention for local context and segment-level recurrence for storage of task specific information distributed over a long context. We demonstrate that ARMT outperfors existing alternatives in associative retrieval tasks and sets a new performance record in the recent BABILong multi-task long-context benchmark by answering single-fact questions over 50 million tokens with an accuracy of 79.9%. The source code for training and evaluation is available on github.
Read more7/9/2024

0
Recurrent Action Transformer with Memory
Egor Cherepanov, Alexey Staroverov, Dmitry Yudin, Alexey K. Kovalev, Aleksandr I. Panov
Recently, the use of transformers in offline reinforcement learning has become a rapidly developing area. This is due to their ability to treat the agent's trajectory in the environment as a sequence, thereby reducing the policy learning problem to sequence modeling. In environments where the agent's decisions depend on past events (POMDPs), capturing both the event itself and the decision point in the context of the model is essential. However, the quadratic complexity of the attention mechanism limits the potential for context expansion. One solution to this problem is to enhance transformers with memory mechanisms. This paper proposes a Recurrent Action Transformer with Memory (RATE), a novel model architecture incorporating a recurrent memory mechanism designed to regulate information retention. To evaluate our model, we conducted extensive experiments on memory-intensive environments (ViZDoom-Two-Colors, T-Maze, Memory Maze, Minigrid.Memory), classic Atari games and MuJoCo control environments. The results show that using memory can significantly improve performance in memory-intensive environments while maintaining or improving results in classic environments. We hope our findings will stimulate research on memory mechanisms for transformers applicable to offline reinforcement learning.
Read more7/24/2024
32
TransformerFAM: Feedback attention is working memory
Dongseong Hwang, Weiran Wang, Zhuoyuan Huo, Khe Chai Sim, Pedro Moreno Mengibar
While Transformers have revolutionized deep learning, their quadratic attention complexity hinders their ability to process infinitely long inputs. We propose Feedback Attention Memory (FAM), a novel Transformer architecture that leverages a feedback loop to enable the network to attend to its own latent representations. This design fosters the emergence of working memory within the Transformer, allowing it to process indefinitely long sequences. TransformerFAM requires no additional weights, enabling seamless integration with pre-trained models. Our experiments show that TransformerFAM significantly improves Transformer performance on long-context tasks across various model sizes (1B, 8B, and 24B). These results showcase the potential to empower Large Language Models (LLMs) to process sequences of unlimited length.
Read more5/8/2024
27
Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
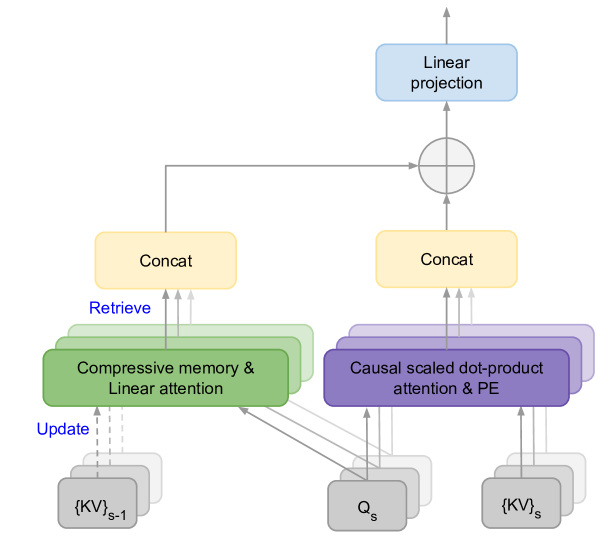
Tsendsuren Munkhdalai, Manaal Faruqui, Siddharth Gopal
This work introduces an efficient method to scale Transformer-based Large Language Models (LLMs) to infinitely long inputs with bounded memory and computation. A key component in our proposed approach is a new attention technique dubbed Infini-attention. The Infini-attention incorporates a compressive memory into the vanilla attention mechanism and builds in both masked local attention and long-term linear attention mechanisms in a single Transformer block. We demonstrate the effectiveness of our approach on long-context language modeling benchmarks, 1M sequence length passkey context block retrieval and 500K length book summarization tasks with 1B and 8B LLMs. Our approach introduces minimal bounded memory parameters and enables fast streaming inference for LLMs.
Read more8/13/2024