Distinctive and Natural Speaker Anonymization via Singular Value Transformation-assisted Matrix

0
Sign in to get full access
Overview
- This paper presents a novel approach for speaker anonymization that aims to preserve the distinctive characteristics of a speaker's voice while obfuscating their identity.
- The key innovation is the use of a singular value transformation-assisted matrix to manipulate the speaker's acoustic features in a way that retains the natural-sounding quality of the anonymized voice.
- The proposed method was evaluated in the context of the VoicePrivacy Challenge, a benchmark for assessing speaker anonymization techniques.
Plain English Explanation
The research paper describes a new way to anonymize someone's voice. The goal is to change the voice so that the speaker's identity is hidden, but the voice still sounds natural and distinctive.
The researchers use a mathematical technique called "singular value decomposition" to modify the acoustic properties of the speaker's voice. This allows them to alter the voice in a way that preserves the unique characteristics of the speaker, while making it difficult to identify the original person.
The effectiveness of this approach was tested as part of the VoicePrivacy Challenge, which is a competition to develop the best speaker anonymization methods. The results suggest this new technique can successfully anonymize a voice while maintaining its distinctive qualities.
Technical Explanation
The paper presents a speaker anonymization method based on singular value transformation-assisted matrix manipulation. The key steps are:
- Representing the speaker's speech signal as a matrix, where each column corresponds to the acoustic features of a speech frame.
- Applying singular value decomposition (SVD) to this matrix to decompose it into three component matrices: U, Σ, and V^T.
- Modifying the Σ matrix to obfuscate the speaker's identity, while preserving the distinctive elements of their voice.
- Reconstructing the anonymized speech signal using the modified Σ matrix and the original U and V^T matrices.
The researchers hypothesized that this SVD-based approach would allow them to selectively transform the acoustic features that are most indicative of a speaker's identity, while retaining the natural-sounding qualities of the voice.
The method was evaluated on the VoicePrivacy Challenge dataset, which contains speech recordings from multiple speakers. The results showed that the proposed approach outperformed baseline anonymization techniques in terms of preserving the expressive characteristics of the speaker's voice.
Critical Analysis
The research presented in this paper offers a promising approach to speaker anonymization that aims to balance the need for privacy protection with the desire to maintain the distinctive qualities of a speaker's voice.
One potential limitation is that the evaluation was conducted on a relatively small dataset from the VoicePrivacy Challenge. Further testing on a larger and more diverse set of speech samples would be needed to fully assess the generalizability of the method.
Additionally, the paper does not provide a detailed analysis of the perceptual quality of the anonymized voices. While the results suggest the method can preserve the natural-sounding characteristics of the speech, more subjective testing with human listeners would help validate this claim.
Finally, the paper does not address potential ethical concerns or privacy implications of speaker anonymization technology. As these tools become more advanced, it will be important to consider their societal impact and ensure they are developed and deployed responsibly.
Conclusion
This paper presents a novel approach to speaker anonymization that uses singular value transformation to modify the acoustic features of a speaker's voice. The key innovation is the ability to selectively obfuscate the elements that are most closely tied to a speaker's identity, while preserving the natural and distinctive qualities of their voice.
The results from the VoicePrivacy Challenge suggest this method outperforms baseline anonymization techniques in terms of maintaining the expressive characteristics of the speaker. While further research is needed to fully assess the method's capabilities and limitations, this work represents an important step forward in the development of privacy-preserving voice technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Distinctive and Natural Speaker Anonymization via Singular Value Transformation-assisted Matrix
Jixun Yao, Qing Wang, Pengcheng Guo, Ziqian Ning, Lei Xie
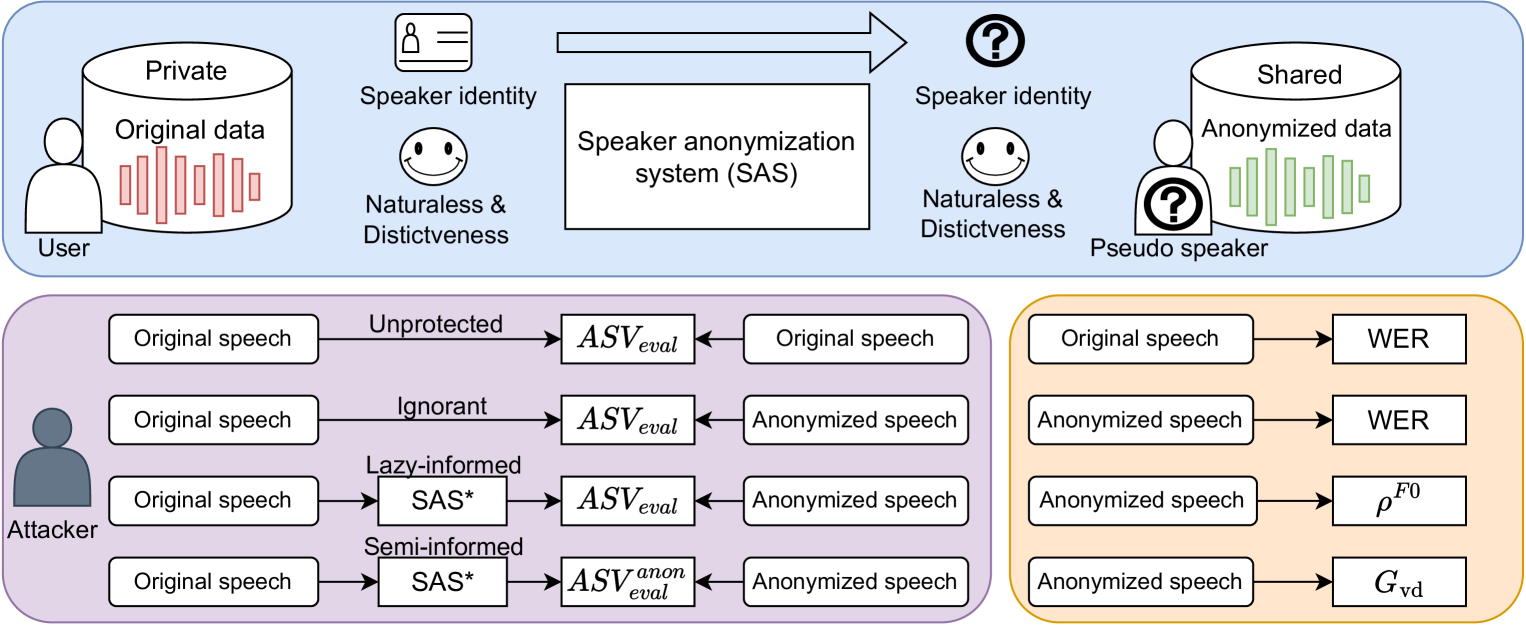
Speaker anonymization is an effective privacy protection solution that aims to conceal the speaker's identity while preserving the naturalness and distinctiveness of the original speech. Mainstream approaches use an utterance-level vector from a pre-trained automatic speaker verification (ASV) model to represent speaker identity, which is then averaged or modified for anonymization. However, these systems suffer from deterioration in the naturalness of anonymized speech, degradation in speaker distinctiveness, and severe privacy leakage against powerful attackers. To address these issues and especially generate more natural and distinctive anonymized speech, we propose a novel speaker anonymization approach that models a matrix related to speaker identity and transforms it into an anonymized singular value transformation-assisted matrix to conceal the original speaker identity. Our approach extracts frame-level speaker vectors from a pre-trained ASV model and employs an attention mechanism to create a speaker-score matrix and speaker-related tokens. Notably, the speaker-score matrix acts as the weight for the corresponding speaker-related token, representing the speaker's identity. The singular value transformation-assisted matrix is generated by recomposing the decomposed orthonormal eigenvectors matrix and non-linear transformed singular through Singular Value Decomposition (SVD). Experiments on VoicePrivacy Challenge datasets demonstrate the effectiveness of our approach in protecting speaker privacy under all attack scenarios while maintaining speech naturalness and distinctiveness.
Read more5/20/2024
0
Multi-speaker Text-to-speech Training with Speaker Anonymized Data
Wen-Chin Huang, Yi-Chiao Wu, Tomoki Toda
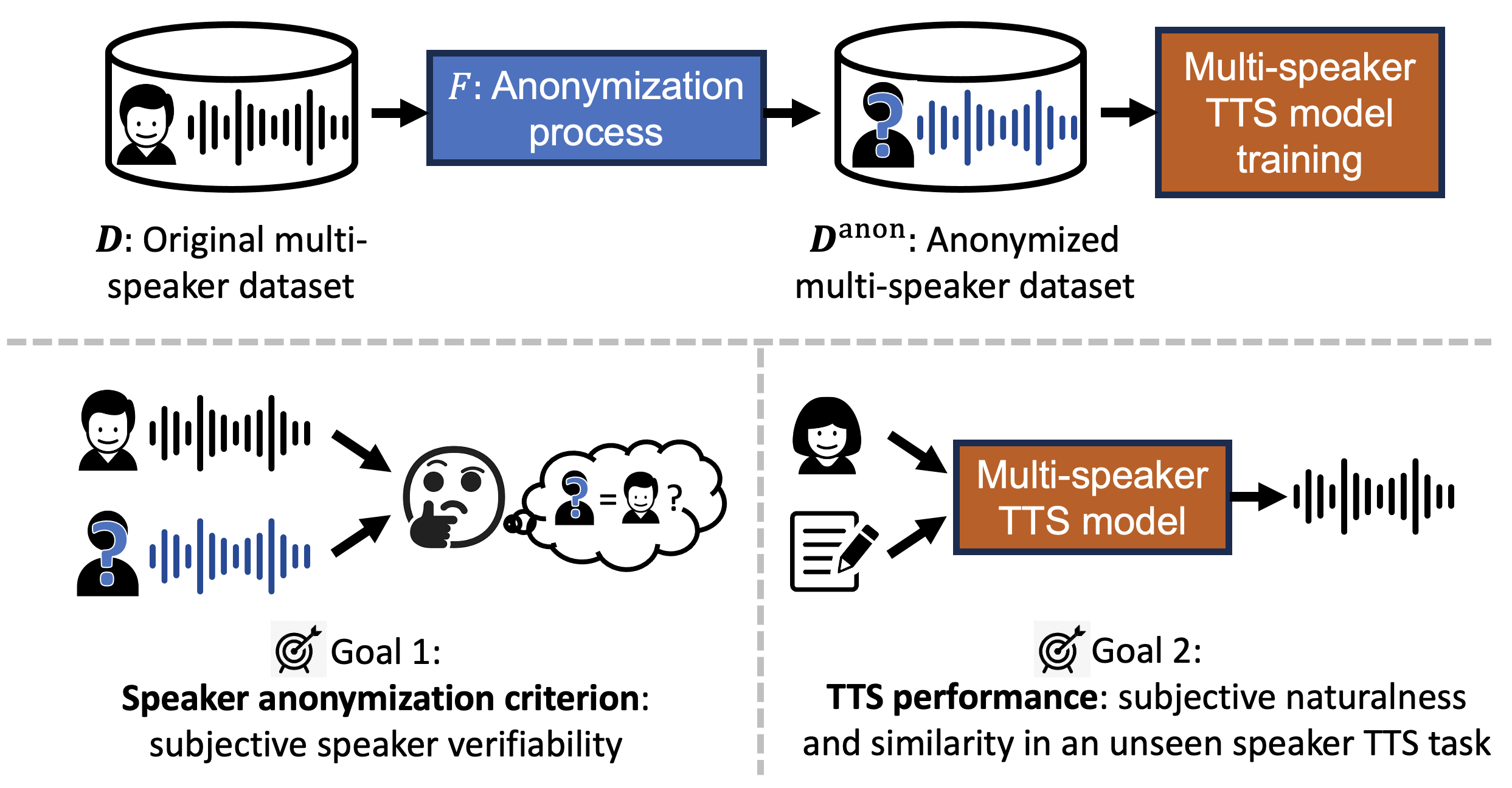
The trend of scaling up speech generation models poses a threat of biometric information leakage of the identities of the voices in the training data, raising privacy and security concerns. In this paper, we investigate training multi-speaker text-to-speech (TTS) models using data that underwent speaker anonymization (SA), a process that tends to hide the speaker identity of the input speech while maintaining other attributes. Two signal processing-based and three deep neural network-based SA methods were used to anonymize VCTK, a multi-speaker TTS dataset, which is further used to train an end-to-end TTS model, VITS, to perform unseen speaker TTS during the testing phase. We conducted extensive objective and subjective experiments to evaluate the anonymized training data, as well as the performance of the downstream TTS model trained using those data. Importantly, we found that UTMOS, a data-driven subjective rating predictor model, and GVD, a metric that measures the gain of voice distinctiveness, are good indicators of the downstream TTS performance. We summarize insights in the hope of helping future researchers determine the goodness of the SA system for multi-speaker TTS training.
Read more5/21/2024

0
MUSA: Multi-lingual Speaker Anonymization via Serial Disentanglement
Jixun Yao, Qing Wang, Pengcheng Guo, Ziqian Ning, Yuguang Yang, Yu Pan, Lei Xie
Speaker anonymization is an effective privacy protection solution designed to conceal the speaker's identity while preserving the linguistic content and para-linguistic information of the original speech. While most prior studies focus solely on a single language, an ideal speaker anonymization system should be capable of handling multiple languages. This paper proposes MUSA, a Multi-lingual Speaker Anonymization approach that employs a serial disentanglement strategy to perform a step-by-step disentanglement from a global time-invariant representation to a temporal time-variant representation. By utilizing semantic distillation and self-supervised speaker distillation, the serial disentanglement strategy can avoid strong inductive biases and exhibit superior generalization performance across different languages. Meanwhile, we propose a straightforward anonymization strategy that employs empty embedding with zero values to simulate the speaker identity concealment process, eliminating the need for conversion to a pseudo-speaker identity and thereby reducing the complexity of speaker anonymization process. Experimental results on VoicePrivacy official datasets and multi-lingual datasets demonstrate that MUSA can effectively protect speaker privacy while preserving linguistic content and para-linguistic information.
Read more7/17/2024

0
Asynchronous Voice Anonymization Using Adversarial Perturbation On Speaker Embedding
Rui Wang, Liping Chen, Kong AiK Lee, Zhen-Hua Ling
Voice anonymization has been developed as a technique for preserving privacy by replacing the speaker's voice in a speech signal with that of a pseudo-speaker, thereby obscuring the original voice attributes from machine recognition and human perception. In this paper, we focus on altering the voice attributes against machine recognition while retaining human perception. We referred to this as the asynchronous voice anonymization. To this end, a speech generation framework incorporating a speaker disentanglement mechanism is employed to generate the anonymized speech. The speaker attributes are altered through adversarial perturbation applied on the speaker embedding, while human perception is preserved by controlling the intensity of perturbation. Experiments conducted on the LibriSpeech dataset showed that the speaker attributes were obscured with their human perception preserved for 60.71% of the processed utterances.
Read more6/14/2024